目前,做數據分析工作,基本人手Numpy,pandas,scikit-learn。而這些計算程序包都是基於python平台的,所以搞數據的都得先裝個python環境。。。(當然,你用R或Julia請忽略本文)
在macOS上,默認安裝有python 2.7,鑒於python2即將停止更新,如果沒有大量的python2代碼需要維護,就直接安裝python3吧。
版本選擇
做數據運算,流行的方式是直接下載Anaconda安裝包,大概500M左右,各種依賴包(綁定了四五百個科學計算程序包),開發工具(jupyter notebook,spyder)一股腦兒都包含了,按照步驟安裝完成,開箱即用,不過裝完後會佔用幾個G的硬盤空間。
我這邊由於硬盤空間有限,採用Miniconda這個發行版本,最新的基於python3.7版本的不到50M。而Miniconda一樣使用conda作為包管理器,可以輕鬆的安裝自己需要的包,例如Numpy,pandas, matplotlib等等。
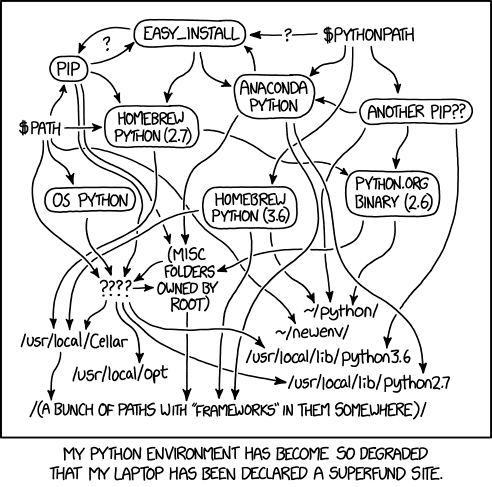
當然,也可以從安裝包或homebrew開始裝,然後再使用pip來安裝相關的程序包。總體上來說,python自身的版本和執行路徑是相當混亂的,可參考下圖。
安裝步驟
- 下載
先從官網下載適合自己操作系統的版本,Miniconda
支持Windows/Linux/macOS這三種主流操作系統。如果遇到官網下載慢的問題,可以考慮國內的鏡像站點,如。
下載完成后,可以先核對下hash值,與官網的值(5cf91dde8f6024061c8b9239a1b4c34380238297adbdb9ef2061eb9d1a7f69bc)是否一致保證安裝文件未被篡改。
$ shasum -a 256 Miniconda3-latest-MacOSX-x86_64.sh
5cf91dde8f6024061c8b9239a1b4c34380238297adbdb9ef2061eb9d1a7f69bc Miniconda3-latest-MacOSX-x86_64.sh
$ bash ./Miniconda3-latest-MacOSX-x86_64.sh
Welcome to Miniconda3 4.7.12
In order to continue the installation process, please review the license
agreement.
Please, press ENTER to continue
Do you accept the license terms? [yes|no]
[no] >>> yes
Miniconda3 will now be installed into this location:
/Users/shenfeng/miniconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/Users/shenfeng/miniconda3] >>>
>>>
按照提示,敲擊回車。中間需要同意使用條款,需要輸入yes,按照路徑點回車默認即可。
Do you wish the installer to initialize Miniconda3
by running conda init? [yes|no]
[yes] >>> yes
==> For changes to take effect, close and re-open your current shell. <==
If you'd prefer that conda's base environment not be activated on startup,
set the auto_activate_base parameter to false:
conda config --set auto_activate_base false
Thank you for installing Miniconda3!
最後的提示是,可以用conda config --set auto_activate_base false命令取消python3環境在啟動時自行加載。
- 重新開一個新的終端
可以發現,python3的env已經生效了。
(base) my:~ shenfeng$ python
Python 3.7.4 (default, Aug 13 2019, 15:17:50)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
$ conda env list
# conda environments:
#
base * /Users/shenfeng/miniconda3
使用conda deactivate可以python3的執行環境,使用conda activate base可以激活默認的python3環境。
- 添加國內鏡像源
由於conda的包服務器都在海外,直接連接安裝可能出現連接超時無法完成的時候,所以可以通過修改用戶目錄下的.condarc 文件。
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
- 使用conda安裝相應的程序包
先使用conda list檢查已經安裝的包,使用conda install需要的程序包
$ $ conda list numpy
# packages in environment at /Users/shenfeng/miniconda3:
#
# Name Version Build Channel
$ conda install numpy
$ conda list numpy
# packages in environment at /Users/shenfeng/miniconda3:
#
# Name Version Build Channel
numpy 1.17.3 py37h4174a10_0 defaults
numpy-base 1.17.3 py37h6575580_0 defaults
相同的方式,我們可以安裝scipy,pandas等包,不再贅述。
交互式工具安裝
大家耳熟能詳的交互式工具肯定就是Jupyter notebook,但我在本機同樣由於磁盤空間問題只安裝ipython。實際上,Jupyter是基於ipython notebook的瀏覽器版本。
$ conda install ipython
$ ipython
Python 3.7.4 (default, Aug 13 2019, 15:17:50)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.9.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import numpy as np
In [2]: dataset= [2,6,8,12,18,24,28,32]
In [3]: sd= np.std(dataset,ddof=1)
In [4]: print(sd)
10.977249200050075
樣例數據處理
先從網上下載一個樣例數據,為excel文件,另存為成csv進行處理。
以下結合上周文章中的,計算這組數據的概括性度量。
import numpy as np
from scipy import stats
dataset = np.genfromtxt('/Users/shenfeng/Downloads/test1.csv',delimiter=',', skip_header=1)
print('Shape of numpy array: ', dataset.shape)
Shape of numpy array: (699,)
集中趨勢的度量
mode = stats.mode(dataset)
print('該組數據的眾數為: ', mode)
該組數據的眾數為: ModeResult(mode=array([1.]), count=array([145]))
# 結果說明眾數為1,出現了145次
print('該組數據的中位數為: ', np.median(dataset))
該組數據的中位數為: 4.0
# 不需要提前排序
print("1/4分位數: ", np.percentile(dataset, 25, interpolation='linear'))
1/4分位數: 2.0
print("1/2分位數: ", np.percentile(dataset, 50, interpolation='linear'))
1/2分位數: 4.0
print("3/4分位數: ", np.percentile(dataset, 75, interpolation='linear'))
3/4分位數: 6.0
print('該組數據的平均數為: ', np.mean(dataset))
該組數據的平均數為: 4.417739628040057
離散程度的度量
print('該組數據的總體標準差為: ', np.std(dataset,ddof=0))
該組數據的總體標準差為: 2.8137258170785375
# 變量值與其平均數的離差除以標準差后的稱為標準分數(standard score)
print('該組數據的標準分數為: ', stats.zscore(dataset))
該組數據的標準分數為: [ 0.20693572 0.20693572 -0.50386559 0.56233637 -0.14846494 1.27313768
-1.2146669 -0.85926625 -0.85926625 -0.14846494 -1.2146669 -0.85926625 ...省略 ]
# 離散係數是測度數據離散程度的統計量,主要用於比較不同樣本數據的離散程度。
print('該組數據的離散係數為: ', stats.variation(dataset))
該組數據的離散係數為: 0.6369152675317026
偏態與峰態的度量
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.hist(dataset, bins=30)
獲得以下分布圖
print('該組數據的偏態係數為: ', stats.skew(dataset))
該組數據的偏態係數為: 0.5915855449527385
# 偏態係數在0.5~1或-1~-0.5之間,則認為是中等偏態分佈
print('該組數據的峰態係數為: ', stats.kurtosis(dataset))
該組數據的峰態係數為: -0.6278342838815454
# 當K<0時為扁平分佈,數據的分佈更分散
總結
本文使用Miniconda發行版配置本地數據運算環境,並對樣例做數據的概括性度量。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益