閉包內容: 匿名函數:能夠完成簡單的功能,傳遞這個函數的引用,只有功能 普通函數:能夠完成複雜的功能,傳遞這個 …
月份: 2020 年 7 月
常見的索引模型淺析
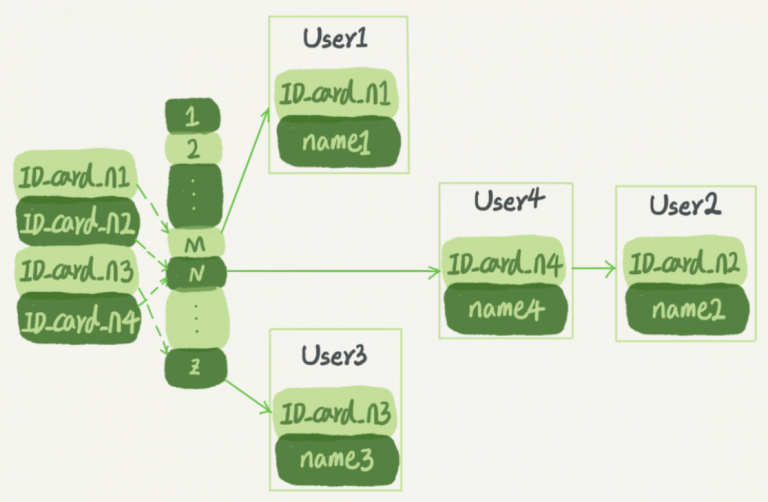
索引的出現是為了提高數據庫查詢的效率,就像書的目錄一樣。常見的索引模型有哈希表、有序數組、B+樹。 自適應 …
4. union-find算法
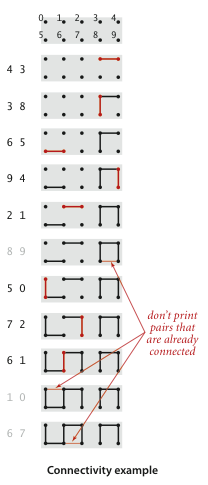
算法的主題思想: 1.優秀的算法因為能夠解決實際問題而變得更為重要; 2.高效算法的代碼也可以很簡 …
實時web應用方案——SignalR(.net core)
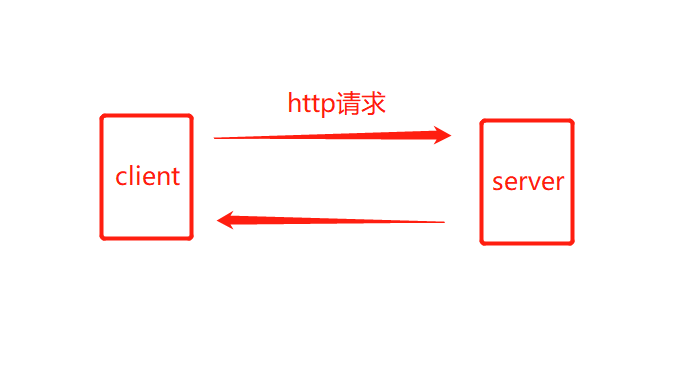
何為實時 先從理論上解釋一下兩者的區別。 大多數傳統的web應用是這樣的:客戶端發起http請求到服務端,服務 …
2020/6/11 JavaScript高級程序設計 DOM
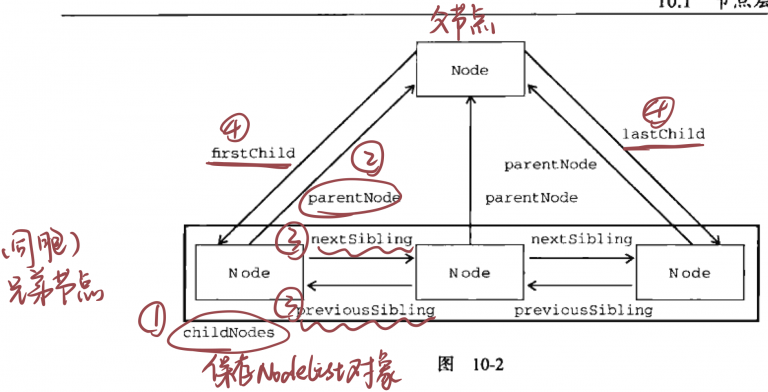
DOM(文檔對象模型)是針對HTML和XML文檔的一個API(應用程序接口)。他描繪了一個層次化的節點樹,允許 …
IOT設備SmartConfig實現
一般情況下,IOT設備(針對wifi設備)在智能化過程中需要連接到家庭路由。但在此之前,需要將wifi信息(通 …
mybatis緩存之一級緩存(二)
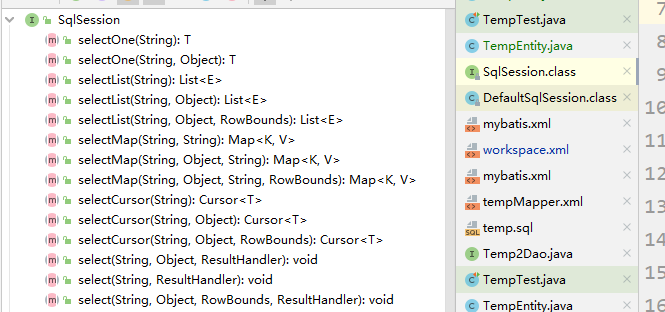
這篇文章介紹下mybatis的一級緩存的生命周期 一級緩存的產生 一級緩存的產生,並不是看mappper的xm …
十、深度優先 && 廣度優先
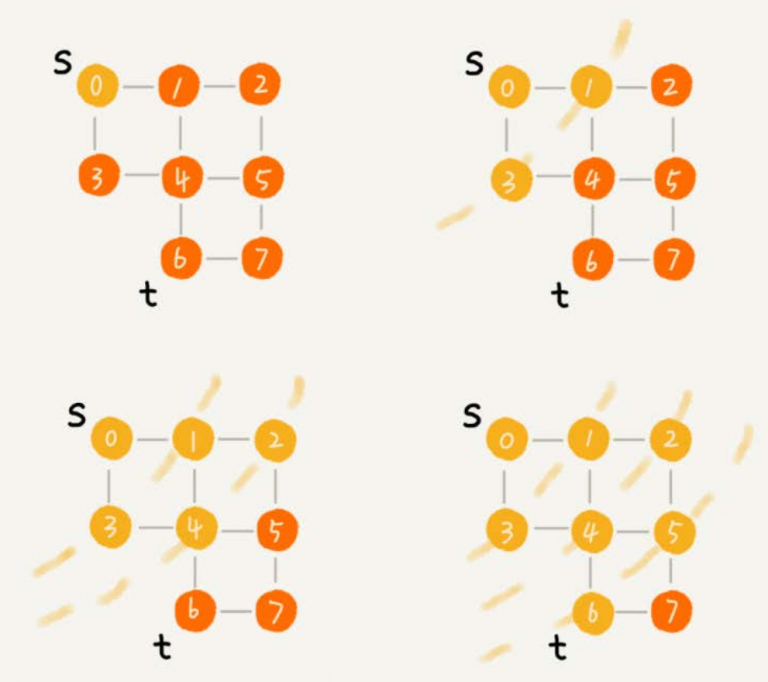
原文地址 一、什麼是“搜索”算法? 算法是作用於具體數據結構之上的,深度優先搜索算法和廣度優先搜索算法都是基於 …
springboot的jar為何能獨立運行
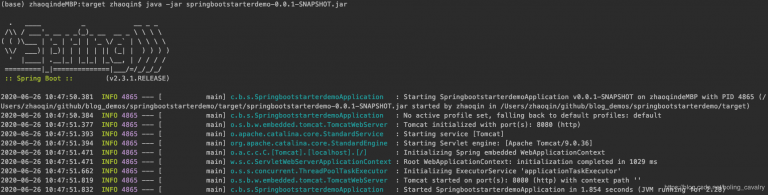
歡迎訪問我的GitHub https://github.com/zq2599/blog_demos 內容:所有 …
高雄鼓勵換電動機車 最高補助額達 2.3 萬
高雄市機車總數達 201 萬輛,成為都市的污染源之一,為了鼓勵機車族更換電動機車,高雄市政府環保局推動補助政策 …