在上一篇文章中,我們詳細的介紹了Java,那麼這些Class文件是如何被加載到內存,由虛擬機來直接使用的呢?這就是本篇博客將要介紹的——類加載過程。
1、類的生命周期
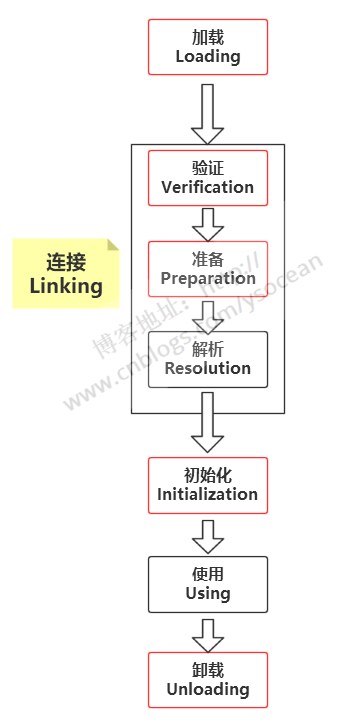
類從被加載到虛擬機內存開始,到卸載出內存為止,其聲明周期流程如下:
上圖中紅色的5個部分(加載、驗證、準備、初始化、卸載)順序是確定的,也就是說,類的加載過程必須按照這種順序按部就班的開始。這裏的“開始”不是按部就班的“進行”或者“完成”,因為這些階段通常是互相交叉混合的進行的,通常會在一個階段執行過程中調用另一個階段。
2、加載
“加載”階段是“類加載”生命周期的第一個階段。在加載階段,虛擬機要完成下面三件事:
①、通過一個類的全限定名來獲取定義此類的二進制字節流。
②、將這個字節流所代表的靜態存儲結構轉化為方法區的運行時數據結構。
③、在Java堆中生成一個代表這個類的java.lang.Class對象,作為方法區這些數據的訪問入口。
PS:類的全限定名可以理解為這個類存放的絕對路徑。方法區是JDK1.7以前定義的運行時數據區,而在JDK1.8以後改為元數據區(Metaspace),主要用於存放被Java虛擬機加載的類信息、常量、靜態變量、即時編譯器編譯后的代碼等數據。詳情可以參考這邊該系列的第二篇文章——。
另外,我們看第一點——通過類的權限定名來獲取定義此類的二進制流,這裏並沒有明確指明要從哪裡獲取以及怎樣獲取,也就是說並沒有明確規定一定要我們從一個 Class 文件中獲取。基於此,在Java的發展過程中,充滿創造力的開發人員在這個舞台上玩出了各種花樣:
1、從 ZIP 包中讀取。這稱為後面的 JAR、EAR、WAR 格式的基礎。
2、從網絡中獲取。比較典型的應用就是 Applet。
3、運行時計算生成。這就是動態代理技術。
4、由其它文件生成。比如 JSP 應用。
5、從數據庫中讀取。
加載階段完成后,虛擬機外部的二進制字節流就按照虛擬機所需的格式存儲在方法區中,然後在Java堆中實例化一個 java.lang.Class 類的對象,這個對象將作為程序訪問方法區中這些類型數據的外部接口。
注意,加載階段與連接階段的部分內容(如一部分字節碼文件的格式校驗)是交叉進行的,加載階段尚未完成,連接階段可能已經開始了。
3、驗證
驗證是連接階段的第一步,作用是為了確保 Class 文件的字節流中包含的信息符合當前虛擬機的要求,並且不會危害虛擬機自身的安全。
我們說Java語言本身是相對安全,因為編譯器的存在,純粹的Java代碼要訪問數組邊界外的數據、跳轉到不存在的代碼行之類的,是要被編譯器拒絕的。但是前面我們也說過,Class 文件不一定非要從Java源碼編譯過來,可以使用任何途徑,包括你很牛逼,直接用十六進制編輯器來編寫 Class 文件。
所以,如果虛擬機不檢查輸入的字節流,將會載入有害的字節流而導致系統崩潰。但是虛擬機規範對於檢查哪些方面,何時檢查,怎麼檢查都沒有明確的規定,不同的虛擬機實現方式可能都會有所不同,但是大致都會完成下面四個方面的檢查。
①、文件格式驗證
校驗字節流是否符合Class文件格式的規範,並且能夠被當前版本的虛擬機處理。
一、是否以魔數 0xCAFEBABE 開頭。
二、主、次版本號是否是當前虛擬機處理範圍之內。
三、常量池的常量中是否有不被支持的常量類型(檢查常量tag標誌)
四、指向常量的各種索引值中是否有指向不存在的常量或不符合類型的常量。
五、CONSTANT_Utf8_info 型的常量中是否有不符合 UTF8 編碼的數據。
六、Class 文件中各個部分及文件本身是否有被刪除的或附加的其他信息。
以上是一部分校驗內容,當然遠不止這些。經過這些校驗后,字節流才會進入內存的方法區中存儲,接下來後面的三個階段校驗都是基於方法區的存儲結構進行的。
②、元數據驗證
第二個階段主要是對字節碼描述的信息進行語義分析,以保證其描述的信息符合Java語言規範要求。
一、這個類是否有父類(除了java.lang.Object 類之外,所有的類都應當有父類)。
二、這個類的父類是否繼承了不允許被繼承的類(被final修飾的類)。
三、如果這個類不是抽象類,是否實現了其父類或接口之中要求實現的所有普通方法。
四、類中的字段、方法是否與父類產生了矛盾(例如覆蓋了父類的final字段、或者出現不符合規則的重載)
③、字節碼驗證
第三個階段字節碼驗證是整個驗證階段中最複雜的,主要是進行數據流和控制流分析。該階段將對類的方法進行分析,保證被校驗的方法在運行時不會做出危害虛擬機安全的行為。
一、保證任意時刻操作數棧中的數據類型與指令代碼序列都能配合工作。例如不會出現在操作數棧中放置了一個 int 類型的數據,使用時卻按照 long 類型來加載到本地變量表中。
二、保證跳轉指令不會跳轉到方法體以外的字節碼指令中。
三、保證方法體中的類型轉換是有效的。比如把一個子類對象賦值給父類數據類型,這是安全的。但是把父類對象賦值給子類數據類型,甚至賦值給完全不相干的類型,這就是不合法的。
④、符號引用驗證
符號引用驗證主要是對類自身以外(常量池中的各種符號引用)的信息進行匹配性的校驗,通常需要校驗如下內容:
一、符號引用中通過字符串描述的全限定名是否能夠找到相應的類。
二、在指定類中是否存在符合方法的字段描述符及簡單名稱所描述的方法和字段。
三、符號引用中的類、字段和方法的訪問性(private、protected、public、default)是否可以被當前類訪問。
4、準備
準備階段是正式為類變量分配內存並設置類變量初始值的階段,這些內存是在方法區中進行分配。
注意:
一、上面說的是類變量,也就是被 static 修飾的變量,不包括實例變量。實例變量會在對象實例化時隨着對象一起分配在堆中。
二、初始值,指的是一些數據類型的默認值。基本的數據類型初始值如下(引用類型的初始值為null):
比如,定義 public static int value = 123 。那麼在準備階段過後,value 的值是 0 而不是 123,把 value 賦值為123 是在程序被編譯后,存放在類的構造器方法之中,是在初始化階段才會被執行。但是有一種特殊情況,通過final 修飾的屬性,比如 定義 public final static int value = 123,那麼在準備階段過後,value 就被賦值為123了。
5、解析
解析階段是虛擬機將常量池中的符號引用替換為直接引用的過程。
符號引用(Symbolic References):符號引用以一組符號來描述所引用的目標,符號可以是任何形式的字面量,只要使用時能無歧義的定位到目標即可。符號引用與虛擬機實現的內存布局無關,引用的目標不一定已經加載到內存中。
直接引用(Direct References):直接引用可以是直接指向目標的指針、相對偏移量或是一個能間接定位到目標的句柄。直接引用是與虛擬機實現內存布局相關的,同一個符號引用在不同虛擬機實例上翻譯出來的直接引用一般不會相同。如果有了直接引用,那麼引用的目標必定已經在內存中存在。
解析動作主要針對類或接口、字段、類方法、接口方法四類符號引用,分別對應於常量池的 CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info、CONSTANTS_InterfaceMethodref_info四種類型常量。
6、初始化
初始化階段是類加載階段的最後一步,前面過程中,除第一個加載階段可以通過用戶自定義類加載器參与之外,其餘過程都是完全由虛擬機主導和控制。而到了初始化階段,則開始真正執行類中定義的Java程序代碼(或者說是字節碼)。
在前面介紹的準備階段中,類變量已經被賦值過初始值了,而初始化階段,則根據程序員的編碼去初始化變量和資源。
換句話來說,初始化階段是執行類構造器<clinit>() 方法的過程。
①、<clinit>() 方法 是由編譯器自動收集類中的所有類變量的賦值動作和靜態語句塊(static{})中的語句合併產生的,編譯器收集的順序是由語句在源文件中出現的順序所決定的,靜態語句塊中只能訪問到定義在靜態語句塊之前的變量,定義在它之後的變量,在前面的靜態語句塊中可以賦值,但是不能訪問。
比如如下代碼會報錯:
但是你把第 14 行代碼放到 static 靜態代碼塊的上面就不會報錯了。或者不改變代碼順序,將第 11 行代碼移除,也不會報錯。
②、<clinit>() 方法與類的構造函數(或者說是實例構造器<init>()方法)不同,它不需要显示的調用父類構造器,虛擬機會保證在子類的<init>()方法執行之前,父類的<init>()方法已經執行完畢。因此虛擬機中第一個被執行的<init>()方法的類肯定是 java.lang.Object。
③、由於父類的<clinit>() 方法先執行,所以父類中定義的靜態語句塊要優先於子類的變量賦值操作。
④、<clinit>() 方法對於接口來說並不是必須的,如果一個類中沒有靜態語句塊,也沒有對變量的賦值操作,那麼編譯器可以不為這個類生成<clinit>() 方法。
⑤、接口中不能使用靜態語句塊,但仍然有變量初始化的賦值操作,因此接口與類一樣都會生成<clinit>() 方法。但接口與類不同的是,執行接口中的<clinit>() 方法不需要先執行父接口的<clinit>() 方法。只有當父接口中定義的變量被使用時,父接口才會被初始化。
⑥、接口的實現類在初始化時也一樣不會執行接口的<clinit>() 方法。
⑦、虛擬機會保證一個類的<clinit>() 方法在多線程環境中被正確的加鎖和同步。如果多個線程同時去初始化一個類,那麼只會有一個線程去執行這個類的<clinit>() 方法,其他的線程都需要阻塞等待,直到活動線程執行<clinit>() 方法完畢。如果在一個類的<clinit>() 方法中有很耗時的操作,那麼可能造成多個進程的阻塞。
比如對於如下代碼:
package com.yb.carton.controller;
/**
* Create by YSOcean
*/
public class ClassLoadInitTest {
static class Hello{
static {
if(true){
System.out.println(Thread.currentThread().getName() + "init");
while(true){}
}
}
}
public static void main(String[] args) {
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"start");
Hello h1 = new Hello();
System.out.println(Thread.currentThread().getName()+"run over");
}).start();
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"start");
Hello h2 = new Hello();
System.out.println(Thread.currentThread().getName()+"run over");
}).start();
}
}
View Code
運行結果如下:
線程1搶到了執行<clinit>() 方法,但是該方法是一個死循環,線程2將一直阻塞等待。
知道了類的初始化過程,那麼類的初始化何時被觸發呢?JVM大概規定了如下幾種情況:
①、當虛擬機啟動時,初始化用戶指定的類。
②、當遇到用以新建目標類實例的 new 指令時,初始化 new 指定的目標類。
③、當遇到調用靜態方法的指令時,初始化該靜態方法所在的類。
④、當遇到訪問靜態字段的指令時,初始化該靜態字段所在的類。
⑤、子類的初始化會觸發父類的初始化。
⑥、如果一個接口定義了 default 方法,那麼直接實現或間接實現該接口的類的初始化,會觸發該接口的初始化。
⑦、使用反射 API 對某個類進行反射調用時,會初始化這個類。
⑧、當初次調用 MethodHandle 實例時,初始化該 MethodHandle 指向的方法所在的類。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選