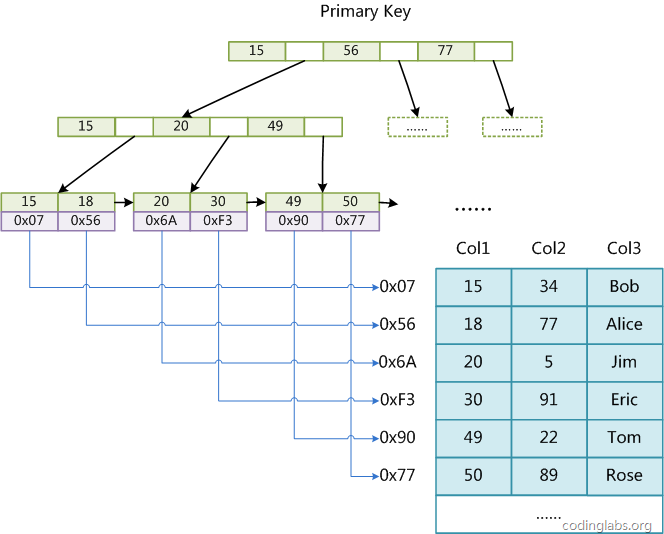
MyISAM引擎的B+Tree的索引
通過上圖可以直接的看出, 在MyISAM對B+樹的運用中明顯的特點如下:
- 所有的非恭弘=叶 恭弘子節點中存儲的全部是索引信息
- 在恭弘=叶 恭弘子節點中存儲的 value值其實是 數據庫中某行數據的index
MyISAM引擎 索引文件的查看:
在 /var/lib/mysql目錄中
.myd 即 my data , 數據庫中表的數據文件
.myi 即 my index , 數據庫中 索引文件
.log 即 mysql的日誌文件
InnoDB引擎 索引文件的查看:
同樣在 /var/lib/mysql 目錄下面
InnoDB引擎的B+Tree的索引
InnoDB的實現方式業內也稱其為聚簇索引, 什麼是聚簇索引呢? 就是相鄰的行的簡直被存儲到一起, 對比上面的兩幅圖片就會發現, 在InnDB中, B+樹的恭弘=叶 恭弘子節點中存儲的是數據行中的一行行記錄, 缺點: 因為索引文件被存放在硬盤上, 所以很占硬盤的空間
一般我們會在每一個表中添加一列 取名 id, 設置它為primary key , 即將他設置成主鍵, 如果使用的存儲引擎也是InnoDB的話, 底層就會建立起主鍵索引, 也是聚簇索引, 並且會自動按照id的大小為我們排好序,(因為它的一個有序的樹)
局部性原理
局部性原理是指CPU訪問存儲器時,無論是存取指令還是存取數據,所訪問的存儲單元都趨於聚集在一個較小的連續區域中。 更進一步說, 當我們通過程序向操作系統發送指令讓它讀取我們指定的數據時, 操作系統會一次性讀取一頁(centos 每頁4kb大小,InnoDB存儲引擎中每一頁16kb)的數據, 它遵循局部性理論, 猜測當用戶需要使用某個數據時, 用戶很可能會使用這個數據周圍的數據,故而進行一次
InnoDB的頁格式
什麼是頁呢? 簡單說,就是一條條數據被的存儲在磁盤上, 使用數據時需要先將數據從磁盤上讀取到內存中, InnoDB每次讀出數據時同樣會遵循 局部性原理, 而不是一條條讀取, 於是InnoDB將數據劃分成一個一個的頁, 以頁作為和磁盤之間交互的基本單位
通過如下sql, 可以看到,InnoDB中每一頁的大小是16kb
show global status like 'Innodb_page_size';
| 名稱 |
簡述 |
| File Header |
文件頭部, 存儲頁的一些通用信息 |
| Page Header |
頁面頭部, 存儲數據頁專有的信息 |
| Infinum + supremum |
最大記錄和最小記錄, 這是兩個虛擬的行記錄 |
| User Records |
用戶記錄, 用來實際存儲行記錄中的內容 |
| Free Space |
空閑空間, 頁中尚位使用的空間 |
| Page Directory |
頁面目錄, 存儲頁中某些記錄的位置 |
| File Tailer |
文件尾部 , 用來校驗頁是否完整 |
InnoDB的行格式 compact
每一頁中存儲的行數據越多. 整體的性能就會越強
compact的行格式如下圖所示
可以看到在行格式中在存儲真正的數據的前面會存儲一些其他信息, 這些信息是為了描述這條記錄而不得不添加的一些信息, 這些額外的信息就是上圖中的前三行
在mysql中char是固定長度的類型, 同時mysql還支持諸如像 varchar這樣可變長度的類型, 不止varchar , 想 varbinary text blob這樣的變長數據類型, 因為 變長的數據類型的列存儲的數據的長度是不固定的, 所以說我們在存儲真正的數據時, 也得將這些數據到底佔用了多大的長度也給保存起來
compact行格式會將值可以為NULL的列統一標記在 NULL標誌位中, 如果數據表中所有的字段都被標記上not null , 那麼就沒有NULL值列表
記錄頭信息, 顧名思義就是用來描述記錄頭中的信息, 記錄頭信息由固定的5個字節組成, 一共40位, 不同位代表的意思也不同, 如下錶
| 名稱 |
單位 bit |
簡介 |
| 預留位1 |
1 |
未使用 |
| 預留位2 |
1 |
未使用 |
| delete_mark |
1 |
標記改行記錄是否被刪除了 |
| min_rec_mark |
1 |
標記在 B+樹中每層的非恭弘=叶 恭弘子節點中最小的node |
| n_owned |
4 |
表示當前記錄擁有的記錄數 |
| heap_no |
13 |
表示當前記錄在堆中的位置 |
| record_type |
3 |
表示當前記錄的類型 , 0表示普通記錄, 1表示B+樹中非恭弘=叶 恭弘子節點記錄, 2表示最小記錄 ,3表示最大記錄 |
| next_record |
16 |
表示下一條記錄的相對位置 |
行溢出
在mysql中每一行, 能存儲的最大的字節數是65535個字節數, 此時我們使用下面的sql執行時就會出現行溢出現象
CREATE TABLE test ( c VARCHAR(65535) ) CHARSET=ascii ROW_FORMAT=Compact;
給varchar申請最大65535 , 再加上compact行格式中還有前面三個非數據列佔用內存,所以一準溢出, 如果不想溢出, 可以適當的將 65535 – 3
頁溢出
前面說了, InnoDB中數據的讀取按照頁為單位, 每一頁的大小是 16kb, 換算成字節就是16384個字節, 但是每行最多存儲 65535個字節啊, 也就是說一行數據可能需要好幾個頁來存儲
怎麼辦呢?
- compact行格式會在存儲真實數據的列中多存儲一部分數據, 這部分數據中存儲的就是下一頁的地址
- dynamic行格式 中直接存儲數據所在的地址, 換句話說就是數據都被存儲在了其他頁上
- compressed行格式會使用壓縮算法對行格式進行壓縮處理
一般我們都是將表中的id列設置為主鍵, 這就會形成主鍵索引, 於是我們需要注意了:
主鍵的佔用的空間越小,整體的檢索效率就會越高
為什麼這麼說呢? 這就可以結合頁的概念來解析, 在B+樹這種數據結果中, 恭弘=叶 恭弘子節點中用來存儲數據, 存儲數據的格式類似Key-value key就是索引值, value就是數據內容, 如果索引佔用的空間太大的話, 單頁16kb能存儲的索引就越小, 這就導致數據被分散在更多的頁上, 致使查詢的效率降低
建立索引的技巧
為某一列建立索引
給text表中的title列創建索引, 索引名字 my_index
alter table text add index my_index (title);
雖然建立索引能提升查詢的效率, 根據前人的經驗看, 這並不是一定的, 建立索引本身會直接消耗內存空間, 同時索, 插入,刪除, 這種寫操作就會打破B+樹的平衡面臨索引的重建, 一般出現如下兩種情況時,是不推薦建立索引的
- 表中的數據本身就很少
- 我們計算一下索引的選擇性很低
兼顧 – 索引的選擇性與前綴索引
所謂選擇性,其實就是說不重複出現的索引值(基數,Cardinality) 與 表中的記錄數的比值
即: 選擇性= 基數 / 記錄數
選擇性的取值範圍在(0,1]之間, 選擇性越接近1 , 說明建立索引的必要性就越強, 比如對sex列進行建立索引,這裏面非男即女, 如果對它建立索引的話, 其實是沒意義的, 還不如直接進行全表掃描來的快
如何使用sql計算選擇性呢? 嚴格遵循上面的公式
SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles;
count(基數/記錄數)
DISTINCT(title) / /count(*)
更詳細的例子看下面的連接
索引失效問題
注意事項
-
索引無法存儲null值
-
如果條件中有or, 即使條件中存在索引也不會使用索引,如果既想使用or,又想使用索引, 就給所有or條件控制的列加上索引
-
使用like查詢時, 如果以%開頭,肯定是進行全表掃描
-
使用like查詢時, 如果%在條件後面
- 對於主鍵索引, 索引失效
- 對於普通索引, 索引不失效
-
如果列的類型是字符串類型, 那麼一定要在條件中將數據用引號引起來,不然也會是索引失效
-
如果mysql認為全表掃描比用索引塊, 同樣不會使用索引
聯合索引
什麼是聯合索引
聯合索引, 也叫複合索引,說白了就是多個字段一起組合成一個索引
像下面這樣使用 id + title 組合在一起構成一個聯合索引
CREATE TABLE `text` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL,
`content` text NOT NULL,
PRIMARY KEY (`id`,`title`)
) ENGINE=InnoDB AUTO_INCREMENT=3691 DEFAULT CHARSET=utf8
- 如果我們像上圖那樣創建了索引,我們只要保證我們的 id+title 兩者結合起來全局唯一就ok
- 建立聯合索引同樣是需要進行排序的,排序的規則就是按照聯合索引所有列組成的字符串的之間的先後順序進行排序, 如a比b優先
左前原則
使用聯合索引進行查詢時一定要遵循左前綴原則, 什麼是左前綴原則呢? 就是說想讓索引生效的話,一定要添加上第一個索引, 只使用第二個索引進行查詢的話會導致索引失效
比如上面創建的聯合索引, 假如我們的查詢條件是 where id = ‘1’ 或者 where id = ‘1’ and title = ‘唐詩宋詞’ 索引都會不失效
但是如果我們不使用第一個索引id, 像這樣 where title = ‘唐詩’ , 結果就是導致索引失效
聯合索引的分組&排序
還是使用這個例子:
CREATE TABLE `text` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL,
`content` text NOT NULL,
PRIMARY KEY (`id`,`title`)
) ENGINE=InnoDB AUTO_INCREMENT=3691 DEFAULT CHARSET=utf8
demo1: 當我們像下面這樣寫sql時, 就會先按照id進行排序, 當id相同時,再按照title進行排序
select * form text order by id, title;
demo2: 當我們像下面這樣寫sql時, 就會先將id相同的劃分為一組, 再將title相同的劃分為一組
select id,title form text group by id, title;
demo3: ASC和DESC混用, 其實大家都知道底層使用B+樹, 本身就是有序的, 要是不加限制的話,默認就是ASC, 反而是混着使用就使得索引失效
select * form text order by id ASC, title DESC;
如何定位慢查詢
相關參數
| 名稱 |
簡介 |
| slow_query_log |
慢查詢的開啟狀態 |
| slow_query_log_file |
慢查詢日誌存儲的位置 |
| long_query_time |
查詢超過多少秒才記錄下來 |
常用sql
# 查看mysql是否開啟了慢查詢
show variables like 'slow_query_log';
# 將全局變量設置為ON
set global slow_query_log ='on';
# 查看慢查詢日誌存儲的位置
show variables like 'slow_query_log_file';
# 查看規定的超過多少秒才被算作慢查詢記錄下來
show variables like 'long_query_time';
show variables like 'long_query%';
# 超過一秒就記錄 , 每次修改這個配置都重新建立一次鏈接
set global long_query_time=1;
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益



 據稱,奧迪未來的超級跑車即是一款核動力汽車,代號Mesarthim F-Tron Quattro,由俄羅斯工程師操刀設計。外型前衛十足,頗有蝙蝠車的味道。 核動力主要部件核反應爐與離子發射器位於前後軸之間,旁邊是發熱裝置,產生的蒸汽進而驅動電機發電,動力電池安裝在前艙,使用四個輪轂電機驅動車輪前進,同時還有電機驅動離子發射器、冷凝器等,除了核燃料供給,其它整個系統構成一個閉環生態。
據稱,奧迪未來的超級跑車即是一款核動力汽車,代號Mesarthim F-Tron Quattro,由俄羅斯工程師操刀設計。外型前衛十足,頗有蝙蝠車的味道。 核動力主要部件核反應爐與離子發射器位於前後軸之間,旁邊是發熱裝置,產生的蒸汽進而驅動電機發電,動力電池安裝在前艙,使用四個輪轂電機驅動車輪前進,同時還有電機驅動離子發射器、冷凝器等,除了核燃料供給,其它整個系統構成一個閉環生態。  由於動力系統是個獨立部分,導致其它部件的安裝位置是個問題,為解決這個問題,工程師設計了一套叫做“Solid Cage”的獨立底盤,這個底盤是聚合物材料,可以3D列印出來,而且可以獨立拆卸。 除此以外,底盤上還有一個平底罐,裡面裝有磁流體,在有磁性的路面上行駛時,車子就會產生下壓力,過彎的時候能抵制側傾力,直行的時候抑制抬頭點頭。 雖然奧迪暫時沒有給出這款車具體推出時間表,總體來說還是值得稱讚的。 文章來源:蓋世汽車
由於動力系統是個獨立部分,導致其它部件的安裝位置是個問題,為解決這個問題,工程師設計了一套叫做“Solid Cage”的獨立底盤,這個底盤是聚合物材料,可以3D列印出來,而且可以獨立拆卸。 除此以外,底盤上還有一個平底罐,裡面裝有磁流體,在有磁性的路面上行駛時,車子就會產生下壓力,過彎的時候能抵制側傾力,直行的時候抑制抬頭點頭。 雖然奧迪暫時沒有給出這款車具體推出時間表,總體來說還是值得稱讚的。 文章來源:蓋世汽車