1.簡介
今天我們緊接着上一篇繼續分享Appium自動化測試框架綜合實踐 – 代碼實現。到今天為止,大功即將告成;框架所需要的代碼實現都基本完成。
2.data數據封裝
2.1使用背景
在實際項目過程中,我們的數據可能是存儲在一個數據文件中,如txt,excel、csv文件類型。我們可以封裝一些方法來讀取文件中的數據來實現數據驅動。
2.2案例
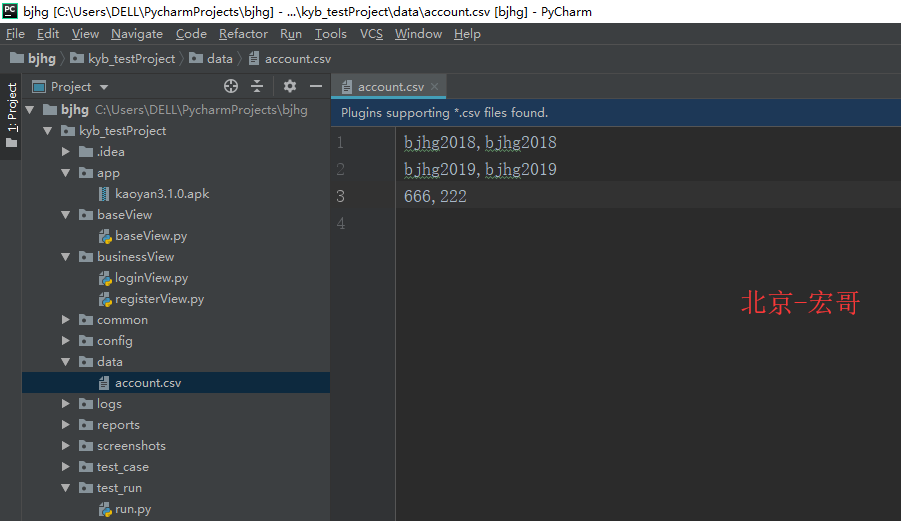
將測試賬號存儲在account.csv文件,內容如下:
account.csv
|
hg2018 |
hg2018 |
|
hg2019 |
zxw2019 |
|
666 |
222 |
參考代碼
2.3enumerate()簡介
enumerate()是python的內置函數
- enumerate在字典上是枚舉、列舉的意思
- 對於一個可迭代的(iterable)/可遍歷的對象(如列表、字符串),enumerate將其組成一個索引序列,利用它可以同時獲得索引和值
- enumerate多用於在for循環中得到計數。
2.4enumerate()使用
如果對一個列表,既要遍歷索引又要遍曆元素時,首先可以這樣寫:
參考代碼
list = ["這", "是", "一個", "測試","數據"] for i in range(len(list)): print(i,list[i])
上述方法有些累贅,利用enumerate()會更加直接和優美:
參考代碼
list1 = ["這", "是", "一個", "測試","數據"] for index, item in enumerate(list1): print(index,item)
3.數據讀取方法封裝
數據讀取方法也屬於公共方法,這裏我們首先實現一下,然後將其封裝到裡邊即可。
3.1數據讀取方法實現的參考代碼
import csv def get_csv_data(csv_file,line): with open(csv_file, 'r', encoding='utf-8-sig') as file: reader=csv.reader(file) for index, row in enumerate(reader,1): if index == line: return row csv_file='../data/account.csv' data=get_csv_data(csv_file,3) print(data)
3.2封裝
將其封裝在公共方法中,在其他地方用到的時候,直接導入調用即可。
4.utf-8與utf-8-sig兩種編碼格式的區別
UTF-8以字節為編碼單元,它的字節順序在所有系統中都是一樣的,沒有字節序的問題,也因此它實際上並不需要BOM(“ByteOrder Mark”)。但是UTF-8 with BOM即utf-8-sig需要提供BOM。
5.config文件配置
各種配置文件都放在這個目錄下。
5.1日誌文件配置
主要是一些日誌信息的配置。
log.config
參考代碼
[loggers] keys=root,infoLogger [logger_root] level=DEBUG handlers=consoleHandler,fileHandler [logger_infoLogger] handlers=consoleHandler,fileHandler qualname=infoLogger propagate=0 [handlers] keys=consoleHandler,fileHandler [handler_consoleHandler] class=StreamHandler level=INFO formatter=form02 args=(sys.stdout,) [handler_fileHandler] class=FileHandler level=INFO formatter=form01 args=('../logs/runlog.log', 'a') [formatters] keys=form01,form02 [formatter_form01] format=%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s [formatter_form02] format=%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s
6.測試用例封裝
這裏宏哥舉例給小夥伴們演示:封裝註冊和登錄兩個測試用例。
6.1測試用例執行開始結束操作封裝
測試用例執行開始和結束的封裝,其他模塊用到直接導入,調用即可。
myunit.py
參考代碼
# coding=utf-8 # 1.先設置編碼,utf-8可支持中英文,如上,一般放在第一行 # 2.註釋:包括記錄創建時間,創建人,項目名稱。 ''' Created on 2019-11-20 @author: 北京-宏哥 QQ交流群:707699217 Project:Appium自動化測試框架綜合實踐 - 代碼實現 ''' # 3.導入模塊 import unittest from kyb_testProject.common.desired_caps import appium_desired import logging from time import sleep class StartEnd(unittest.TestCase): def setUp(self): logging.info('=====setUp====') self.driver=appium_desired() def tearDown(self): logging.info('====tearDown====') sleep(5) self.driver.close_app()
6.2註冊用例
開始註冊用例代碼邏輯的實現。
test_register.py
參考代碼
# coding=utf-8 # 1.先設置編碼,utf-8可支持中英文,如上,一般放在第一行 # 2.註釋:包括記錄創建時間,創建人,項目名稱。 ''' Created on 2019-11-20 @author: 北京-宏哥 QQ交流群:707699217 Project:Appium自動化測試框架綜合實踐 - 代碼實現 ''' # 3.導入模塊 from kyb_testProject.common.myunit import StartEnd from kyb_testProject.businessView.registerView import RegisterView import logging,random,unittest class RegisterTest(StartEnd): def test_user_register(self): logging.info('======test_user_register======') r=RegisterView(self.driver) username = 'bjhg2019' + 'fly' + str(random.randint(1000, 9000)) password = 'bjhg2020' + str(random.randint(1000, 9000)) email = 'bjhg' + str(random.randint(1000, 9000)) + '@163.com' self.assertTrue(r.register_action(username,password,email)) if __name__ == '__main__': unittest.main()
6.3登錄用例
開始登錄用例代碼邏輯的實現。
test_login.py
參考代碼
# coding=utf-8 # 1.先設置編碼,utf-8可支持中英文,如上,一般放在第一行 # 2.註釋:包括記錄創建時間,創建人,項目名稱。 ''' Created on 2019-11-13 @author: 北京-宏哥 QQ交流群:707699217 Project:Appium自動化測試框架綜合實踐 - 代碼實現 ''' # 3.導入模塊 from kyb_testProject.common.myunit import StartEnd from kyb_testProject.businessView.loginView import LoginView import unittest import logging class TestLogin(StartEnd): csv_file='../data/account.csv' @unittest.skip('test_login_zxw2018') def test_login_zxw2018(self): logging.info('======test_login_zxw2018=====') l=LoginView(self.driver) data=l.get_csv_data(self.csv_file,2) l.login_action(data[0],data[1]) self.assertTrue(l.check_loginStatus()) # @unittest.skip('skip test_login_zxw2017') def test_login_zxw2017(self): logging.info('======test_login_zxw2017=====') l=LoginView(self.driver) data = l.get_csv_data(self.csv_file, 1) l.login_action(data[0], data[1]) self.assertTrue(l.check_loginStatus()) @unittest.skip('test_login_error') def test_login_error(self): logging.info('======test_login_error=====') l = LoginView(self.driver) data = l.get_csv_data(self.csv_file, 3) l.login_action(data[0], data[1]) self.assertTrue(l.check_loginStatus(),msg='login fail!') if __name__ == '__main__': unittest.main()
7.小結
到此,Appium自動化測試框架就差下一篇就全部完成了,聰明的你都懂了嗎???嘿嘿!慢慢地來吧。
下節預告
下一篇,講解執行測試用例,生成測試報告,以及自動化平台,請關注宏哥,敬請期待!!!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※台灣海運大陸貨務運送流程
※兩岸物流進出口一站式服務