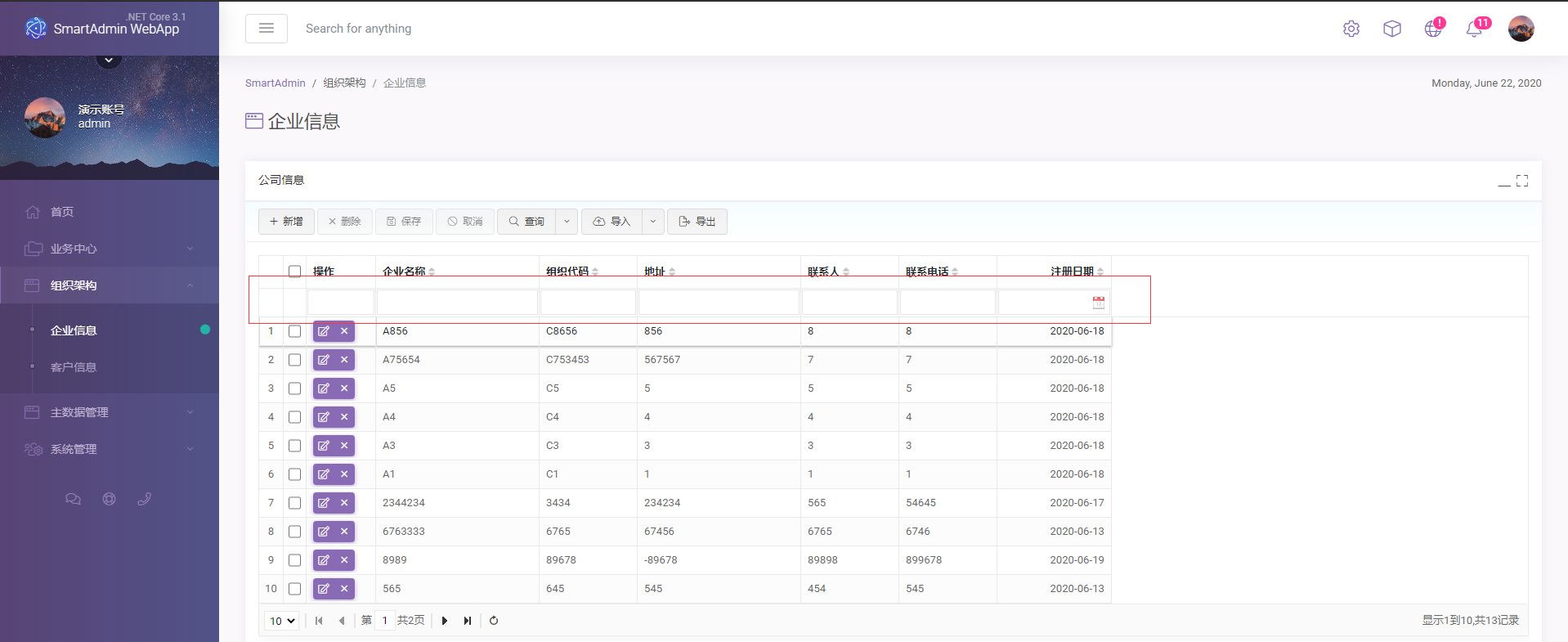
-之動態查詢,查詢邏輯封裝復用
基於領域驅動設計(DDD)超輕量級快速開發架構詳細介紹請看
https://www.cnblogs.com/neozhu/p/13174234.html
需求
- 配合EasyUI datagird filter實現多字段(任意字段)的篩選
- 根據業務需求篩選特定的狀態或條件,如:查看結案的訂單,最近30天的訂單,查看屬於我的訂單.等等,這些邏輯是固定也是可以被重用,但又不想每次寫相同的條件,那麼下面我會給我的解決方案.
需求1隻是一個偷懶的實現方式,因為datagrid自帶這個功能,但又不想根據具體的需求來畫查詢條件,如果需求必須要再datagrid上面做一塊查詢條件的輸入那目前只能在前端自己手工添加,在組織後傳入後台,暫時不在這裏討論
需求2可能不太好解釋,看完代碼就自然理解為什麼要這麼做了,這麼做的好處有哪些
具體實現的方式
默認情況下 datagrid 有幾列就可以對這幾列進行篩選,對於日期型的字段會採用between,選擇2個時間之間進行篩選,数字類型會提供大於小於等符號選擇,可以自行嘗試,其原理是datagrid 會根據datagrid 頭部輸入的值生成一個Json字符串發送後台請求數據
JSON:格式
filterRules: [
{field:field,op:op,value:value},
{field:field,op:op,value:value},
]
1 var filters = JsonConvert.DeserializeObject<IEnumerable<filterRule>>(filterRules);
2 foreach (var rule in filters)
3 {
4 if (rule.field == "Id" && !string.IsNullOrEmpty(rule.value) && rule.value.IsInt())
5 {
6 var val = Convert.ToInt32(rule.value);
7 switch (rule.op)
8 {
9 case "equal":
10 this.And(x => x.Id == val);
11 break;
12 case "notequal":
13 this.And(x => x.Id != val);
14 break;
15 case "less":
16 this.And(x => x.Id < val);
17 break;
18 case "lessorequal":
19 this.And(x => x.Id <= val);
20 break;
21 case "greater":
22 this.And(x => x.Id > val);
23 break;
24 case "greaterorequal":
25 this.And(x => x.Id >= val);
26 break;
27 default:
28 this.And(x => x.Id == val);
29 break;
30 }
31 }
32 if (rule.field == "Name" && !string.IsNullOrEmpty(rule.value))
33 {
34 this.And(x => x.Name.Contains(rule.value));
35 }
36 if (rule.field == "Code" && !string.IsNullOrEmpty(rule.value))
37 {
38 this.And(x => x.Code.Contains(rule.value));
39 }
40
41 if (rule.field == "Address" && !string.IsNullOrEmpty(rule.value))
42 {
43 this.And(x => x.Address.Contains(rule.value));
44 }
45
46 if (rule.field == "Contect" && !string.IsNullOrEmpty(rule.value))
47 {
48 this.And(x => x.Contect.Contains(rule.value));
49 }
50
51 if (rule.field == "PhoneNumber" && !string.IsNullOrEmpty(rule.value))
52 {
53 this.And(x => x.PhoneNumber.Contains(rule.value));
54 }
55
56 if (rule.field == "RegisterDate" && !string.IsNullOrEmpty(rule.value))
57 {
58 if (rule.op == "between")
59 {
60 var datearray = rule.value.Split(new char[] { '-' });
61 var start = Convert.ToDateTime(datearray[0]);
62 var end = Convert.ToDateTime(datearray[1]);
63
64 this.And(x => SqlFunctions.DateDiff("d", start, x.RegisterDate) >= 0);
65 this.And(x => SqlFunctions.DateDiff("d", end, x.RegisterDate) <= 0);
66 }
67 }
68 if (rule.field == "CreatedDate" && !string.IsNullOrEmpty(rule.value))
69 {
70 if (rule.op == "between")
71 {
72 var datearray = rule.value.Split(new char[] { '-' });
73 var start = Convert.ToDateTime(datearray[0]);
74 var end = Convert.ToDateTime(datearray[1]);
75
76 this.And(x => SqlFunctions.DateDiff("d", start, x.CreatedDate) >= 0);
77 this.And(x => SqlFunctions.DateDiff("d", end, x.CreatedDate) <= 0);
78 }
79 }
80
81
82 if (rule.field == "CreatedBy" && !string.IsNullOrEmpty(rule.value))
83 {
84 this.And(x => x.CreatedBy.Contains(rule.value));
85 }
86
87 if (rule.field == "LastModifiedDate" && !string.IsNullOrEmpty(rule.value))
88 {
89 if (rule.op == "between")
90 {
91 var datearray = rule.value.Split(new char[] { '-' });
92 var start = Convert.ToDateTime(datearray[0]);
93 var end = Convert.ToDateTime(datearray[1]);
94
95 this.And(x => SqlFunctions.DateDiff("d", start, x.LastModifiedDate) >= 0);
96 this.And(x => SqlFunctions.DateDiff("d", end, x.LastModifiedDate) <= 0);
97 }
98 }
99
100 if (rule.field == "LastModifiedBy" && !string.IsNullOrEmpty(rule.value))
101 {
102 this.And(x => x.LastModifiedBy.Contains(rule.value));
103 }
104
105 }
View Code
- 新的做法是動態根據field,op,value生成一個linq 表達式,不用再做繁瑣的判斷,這塊代碼也可以被其它項目使用,非常好用
namespace SmartAdmin
{
public static class PredicateBuilder
{
public static Expression<Func<T, bool>> FromFilter<T>(string filtergroup) {
Expression<Func<T, bool>> any = x => true;
if (!string.IsNullOrEmpty(filtergroup))
{
var filters = JsonSerializer.Deserialize<filter[]>(filtergroup);
foreach (var filter in filters)
{
if (Enum.TryParse(filter.op, out OperationExpression op) && !string.IsNullOrEmpty(filter.value))
{
var expression = GetCriteriaWhere<T>(filter.field, op, filter.value);
any = any.And(expression);
}
}
}
return any;
}
#region -- Public methods --
public static Expression<Func<T, bool>> GetCriteriaWhere<T>(Expression<Func<T, object>> e, OperationExpression selectedOperator, object fieldValue)
{
var name = GetOperand<T>(e);
return GetCriteriaWhere<T>(name, selectedOperator, fieldValue);
}
public static Expression<Func<T, bool>> GetCriteriaWhere<T, T2>(Expression<Func<T, object>> e, OperationExpression selectedOperator, object fieldValue)
{
var name = GetOperand<T>(e);
return GetCriteriaWhere<T, T2>(name, selectedOperator, fieldValue);
}
public static Expression<Func<T, bool>> GetCriteriaWhere<T>(string fieldName, OperationExpression selectedOperator, object fieldValue)
{
var props = TypeDescriptor.GetProperties(typeof(T));
var prop = GetProperty(props, fieldName, true);
var parameter = Expression.Parameter(typeof(T));
var expressionParameter = GetMemberExpression<T>(parameter, fieldName);
if (prop != null && fieldValue != null)
{
BinaryExpression body = null;
switch (selectedOperator)
{
case OperationExpression.equal:
body = Expression.Equal(expressionParameter, Expression.Constant(Convert.ChangeType(fieldValue, Nullable.GetUnderlyingType(prop.PropertyType)?? prop.PropertyType), prop.PropertyType));
return Expression.Lambda<Func<T, bool>>(body, parameter);
case OperationExpression.notequal:
body = Expression.NotEqual(expressionParameter, Expression.Constant(Convert.ChangeType(fieldValue, Nullable.GetUnderlyingType(prop.PropertyType) ?? prop.PropertyType), prop.PropertyType));
return Expression.Lambda<Func<T, bool>>(body, parameter);
case OperationExpression.less:
body = Expression.LessThan(expressionParameter, Expression.Constant(Convert.ChangeType(fieldValue, Nullable.GetUnderlyingType(prop.PropertyType) ?? prop.PropertyType), prop.PropertyType));
return Expression.Lambda<Func<T, bool>>(body, parameter);
case OperationExpression.lessorequal:
body = Expression.LessThanOrEqual(expressionParameter, Expression.Constant(Convert.ChangeType(fieldValue, Nullable.GetUnderlyingType(prop.PropertyType) ?? prop.PropertyType), prop.PropertyType));
return Expression.Lambda<Func<T, bool>>(body, parameter);
case OperationExpression.greater:
body = Expression.GreaterThan(expressionParameter, Expression.Constant(Convert.ChangeType(fieldValue, Nullable.GetUnderlyingType(prop.PropertyType) ?? prop.PropertyType), prop.PropertyType));
return Expression.Lambda<Func<T, bool>>(body, parameter);
case OperationExpression.greaterorequal:
body = Expression.GreaterThanOrEqual(expressionParameter, Expression.Constant(Convert.ChangeType(fieldValue, Nullable.GetUnderlyingType(prop.PropertyType) ?? prop.PropertyType), prop.PropertyType));
return Expression.Lambda<Func<T, bool>>(body, parameter);
case OperationExpression.contains:
var contains = typeof(string).GetMethod("Contains", new[] { typeof(string) });
var bodyLike = Expression.Call(expressionParameter, contains, Expression.Constant(Convert.ChangeType(fieldValue, Nullable.GetUnderlyingType(prop.PropertyType) ?? prop.PropertyType), prop.PropertyType));
return Expression.Lambda<Func<T, bool>>(bodyLike, parameter);
case OperationExpression.endwith:
var endswith = typeof(string).GetMethod("EndsWith",new[] { typeof(string) });
var bodyendwith = Expression.Call(expressionParameter, endswith, Expression.Constant(Convert.ChangeType(fieldValue, Nullable.GetUnderlyingType(prop.PropertyType) ?? prop.PropertyType), prop.PropertyType));
return Expression.Lambda<Func<T, bool>>(bodyendwith, parameter);
case OperationExpression.beginwith:
var startswith = typeof(string).GetMethod("StartsWith", new[] { typeof(string) });
var bodystartswith = Expression.Call(expressionParameter, startswith, Expression.Constant(Convert.ChangeType(fieldValue, Nullable.GetUnderlyingType(prop.PropertyType) ?? prop.PropertyType), prop.PropertyType));
return Expression.Lambda<Func<T, bool>>(bodystartswith, parameter);
case OperationExpression.includes:
return Includes<T>(fieldValue, parameter, expressionParameter, prop.PropertyType);
case OperationExpression.between:
return Between<T>(fieldValue, parameter, expressionParameter, prop.PropertyType);
default:
throw new Exception("Not implement Operation");
}
}
else
{
Expression<Func<T, bool>> filter = x => true;
return filter;
}
}
public static Expression<Func<T, bool>> GetCriteriaWhere<T, T2>(string fieldName, OperationExpression selectedOperator, object fieldValue)
{
var props = TypeDescriptor.GetProperties(typeof(T));
var prop = GetProperty(props, fieldName, true);
var parameter = Expression.Parameter(typeof(T));
var expressionParameter = GetMemberExpression<T>(parameter, fieldName);
if (prop != null && fieldValue != null)
{
switch (selectedOperator)
{
case OperationExpression.any:
return Any<T, T2>(fieldValue, parameter, expressionParameter);
default:
throw new Exception("Not implement Operation");
}
}
else
{
Expression<Func<T, bool>> filter = x => true;
return filter;
}
}
public static Expression<Func<T, bool>> Or<T>(this Expression<Func<T, bool>> expr, Expression<Func<T, bool>> or)
{
if (expr == null)
{
return or;
}
return Expression.Lambda<Func<T, bool>>(Expression.OrElse(new SwapVisitor(expr.Parameters[0], or.Parameters[0]).Visit(expr.Body), or.Body), or.Parameters);
}
public static Expression<Func<T, bool>> And<T>(this Expression<Func<T, bool>> expr, Expression<Func<T, bool>> and)
{
if (expr == null)
{
return and;
}
return Expression.Lambda<Func<T, bool>>(Expression.AndAlso(new SwapVisitor(expr.Parameters[0], and.Parameters[0]).Visit(expr.Body), and.Body), and.Parameters);
}
#endregion
#region -- Private methods --
private static string GetOperand<T>(Expression<Func<T, object>> exp)
{
if (!( exp.Body is MemberExpression body ))
{
var ubody = (UnaryExpression)exp.Body;
body = ubody.Operand as MemberExpression;
}
var operand = body.ToString();
return operand.Substring(2);
}
private static MemberExpression GetMemberExpression<T>(ParameterExpression parameter, string propName)
{
if (string.IsNullOrEmpty(propName))
{
return null;
}
var propertiesName = propName.Split('.');
if (propertiesName.Count() == 2)
{
return Expression.Property(Expression.Property(parameter, propertiesName[0]), propertiesName[1]);
}
return Expression.Property(parameter, propName);
}
private static Expression<Func<T, bool>> Includes<T>(object fieldValue, ParameterExpression parameterExpression, MemberExpression memberExpression ,Type type)
{
var safetype= Nullable.GetUnderlyingType(type) ?? type;
switch (safetype.Name.ToLower())
{
case "string":
var strlist = (IEnumerable<string>)fieldValue;
if (strlist == null || strlist.Count() == 0)
{
return x => true;
}
var strmethod = typeof(List<string>).GetMethod("Contains", new Type[] { typeof(string) });
var strcallexp = Expression.Call(Expression.Constant(strlist.ToList()), strmethod, memberExpression);
return Expression.Lambda<Func<T, bool>>(strcallexp, parameterExpression);
case "int32":
var intlist = (IEnumerable<int>)fieldValue;
if (intlist == null || intlist.Count() == 0)
{
return x => true;
}
var intmethod = typeof(List<int>).GetMethod("Contains", new Type[] { typeof(int) });
var intcallexp = Expression.Call(Expression.Constant(intlist.ToList()), intmethod, memberExpression);
return Expression.Lambda<Func<T, bool>>(intcallexp, parameterExpression);
case "float":
var floatlist = (IEnumerable<float>)fieldValue;
if (floatlist == null || floatlist.Count() == 0)
{
return x => true;
}
var floatmethod = typeof(List<int>).GetMethod("Contains", new Type[] { typeof(int) });
var floatcallexp = Expression.Call(Expression.Constant(floatlist.ToList()), floatmethod, memberExpression);
return Expression.Lambda<Func<T, bool>>(floatcallexp, parameterExpression);
default:
return x => true;
}
}
private static Expression<Func<T, bool>> Between<T>(object fieldValue, ParameterExpression parameterExpression, MemberExpression memberExpression, Type type)
{
var safetype = Nullable.GetUnderlyingType(type) ?? type;
switch (safetype.Name.ToLower())
{
case "datetime":
var datearray = ( (string)fieldValue ).Split(new char[] { '-' }, StringSplitOptions.RemoveEmptyEntries);
var start = Convert.ToDateTime(datearray[0] + " 00:00:00", CultureInfo.CurrentCulture);
var end = Convert.ToDateTime(datearray[1] + " 23:59:59", CultureInfo.CurrentCulture);
var greater = Expression.GreaterThan(memberExpression, Expression.Constant(start, type));
var less = Expression.LessThan(memberExpression, Expression.Constant(end, type));
return Expression.Lambda<Func<T, bool>>(greater, parameterExpression)
.And(Expression.Lambda<Func<T, bool>>(less, parameterExpression));
case "int":
case "int32":
var intarray = ( (string)fieldValue ).Split(new char[] { '-' }, StringSplitOptions.RemoveEmptyEntries);
var min = Convert.ToInt32(intarray[0] , CultureInfo.CurrentCulture);
var max = Convert.ToInt32(intarray[1], CultureInfo.CurrentCulture);
var maxthen = Expression.GreaterThan(memberExpression, Expression.Constant(min, type));
var minthen = Expression.LessThan(memberExpression, Expression.Constant(max, type));
return Expression.Lambda<Func<T, bool>>(maxthen, parameterExpression)
.And(Expression.Lambda<Func<T, bool>>(minthen, parameterExpression));
case "decimal":
var decarray = ( (string)fieldValue ).Split(new char[] { '-' }, StringSplitOptions.RemoveEmptyEntries);
var dmin = Convert.ToDecimal(decarray[0], CultureInfo.CurrentCulture);
var dmax = Convert.ToDecimal(decarray[1], CultureInfo.CurrentCulture);
var dmaxthen = Expression.GreaterThan(memberExpression, Expression.Constant(dmin, type));
var dminthen = Expression.LessThan(memberExpression, Expression.Constant(dmax, type));
return Expression.Lambda<Func<T, bool>>(dmaxthen, parameterExpression)
.And(Expression.Lambda<Func<T, bool>>(dminthen, parameterExpression));
case "float":
var farray = ((string)fieldValue).Split(new char[] { '-' }, StringSplitOptions.RemoveEmptyEntries);
var fmin = Convert.ToDecimal(farray[0], CultureInfo.CurrentCulture);
var fmax = Convert.ToDecimal(farray[1], CultureInfo.CurrentCulture);
var fmaxthen = Expression.GreaterThan(memberExpression, Expression.Constant(fmin, type));
var fminthen = Expression.LessThan(memberExpression, Expression.Constant(fmax, type));
return Expression.Lambda<Func<T, bool>>(fmaxthen, parameterExpression)
.And(Expression.Lambda<Func<T, bool>>(fminthen, parameterExpression));
case "string":
var strarray = ( (string)fieldValue ).Split(new char[] { '-' }, StringSplitOptions.RemoveEmptyEntries);
var smin = strarray[0];
var smax = strarray[1];
var strmethod = typeof(string).GetMethod("Contains");
var mm = Expression.Call(memberExpression, strmethod, Expression.Constant(smin, type));
var nn = Expression.Call(memberExpression, strmethod, Expression.Constant(smax, type));
return Expression.Lambda<Func<T, bool>>(mm, parameterExpression)
.Or(Expression.Lambda<Func<T, bool>>(nn, parameterExpression));
default:
return x => true;
}
}
private static Expression<Func<T, bool>> Any<T, T2>(object fieldValue, ParameterExpression parameterExpression, MemberExpression memberExpression)
{
var lambda = (Expression<Func<T2, bool>>)fieldValue;
var anyMethod = typeof(Enumerable).GetMethods(BindingFlags.Static | BindingFlags.Public)
.First(m => m.Name == "Any" && m.GetParameters().Count() == 2).MakeGenericMethod(typeof(T2));
var body = Expression.Call(anyMethod, memberExpression, lambda);
return Expression.Lambda<Func<T, bool>>(body, parameterExpression);
}
private static PropertyDescriptor GetProperty(PropertyDescriptorCollection props, string fieldName, bool ignoreCase)
{
if (!fieldName.Contains('.'))
{
return props.Find(fieldName, ignoreCase);
}
var fieldNameProperty = fieldName.Split('.');
return props.Find(fieldNameProperty[0], ignoreCase).GetChildProperties().Find(fieldNameProperty[1], ignoreCase);
}
#endregion
}
internal class SwapVisitor : ExpressionVisitor
{
private readonly Expression from, to;
public SwapVisitor(Expression from, Expression to)
{
this.from = from;
this.to = to;
}
public override Expression Visit(Expression node) => node == from ? to : base.Visit(node);
}
public enum OperationExpression
{
equal,
notequal,
less,
lessorequal,
greater,
greaterorequal,
contains,
beginwith,
endwith,
includes,
between,
any
}
}
View Code
1 public async Task<JsonResult> GetData(int page = 1, int rows = 10, string sort = "Id", string order = "asc", string filterRules = "")
2 {
3 try
4 {
5 var filters = PredicateBuilder.FromFilter<Company>(filterRules);
6 var total = await this.companyService
7 .Query(filters)
8 .AsNoTracking()
9 .CountAsync()
10 ;
11 var pagerows = (await this.companyService
12 .Query(filters)
13 .AsNoTracking()
14 .OrderBy(n => n.OrderBy(sort, order))
15 .Skip(page - 1).Take(rows)
16 .SelectAsync())
17 .Select(n => new
18 {
19 Id = n.Id,
20 Name = n.Name,
21 Code = n.Code,
22 Address = n.Address,
23 Contect = n.Contect,
24 PhoneNumber = n.PhoneNumber,
25 RegisterDate = n.RegisterDate.ToString("yyyy-MM-dd HH:mm:ss")
26 }).ToList();
27 var pagelist = new { total = total, rows = pagerows };
28 return Json(pagelist);
29 }
30 catch(Exception e) {
31 throw e;
32 }
33
34 }
配合使用的代碼
- 對於固定查詢邏輯的封裝和復用,當然除了復用還可以明顯的提高代碼的可讀性.
public class OrderSalesQuery : QueryObject<Order>
{
public decimal Amount { get; set; }
public string Country { get; set; }
public DateTime FromDate { get; set; }
public DateTime ToDate { get; set; }
public override Expression<Func<Order, bool>> Query()
{
return (x =>
x.OrderDetails.Sum(y => y.UnitPrice) > Amount &&
x.OrderDate >= FromDate &&
x.OrderDate <= ToDate &&
x.ShipCountry == Country);
}
}
查看訂單的銷售情況,條件 金額,國家,日期
var orderRepository = new Repository<Order>(this);
var orders = orderRepository
.Query(new OrderSalesQuery(){
Amount = 100,
Country = "USA",
FromDate = DateTime.Parse("01/01/1996"),
ToDate = DateTime.Parse("12/31/1996" )
})
.Select();
調用查詢方法
public class CustomerLogisticsQuery : QueryObject<Customer>
{
public CustomerLogisticsQuery FromCountry(string country)
{
Add(x => x.Country == country);
return this;
}
public CustomerLogisticsQuery LivesInCity(string city)
{
Add(x => x.City == city);
return this;
}
}
客戶查詢 根據國家和城市查詢
public class CustomerSalesQuery : QueryObject<Customer>
{
public CustomerSalesQuery WithPurchasesMoreThan(decimal amount)
{
Add(x => x.Orders
.SelectMany(y => y.OrderDetails)
.Sum(z => z.UnitPrice * z.Quantity) > amount);
return this;
}
public CustomerSalesQuery WithQuantitiesMoreThan(decimal quantity)
{
Add(x => x.Orders
.SelectMany(y => y.OrderDetails)
.Sum(z => z.Quantity) > quantity);
return this;
}
}
客戶的銷售情況,金額和數量
var customerRepository = new Repository<Customer>(this);
var query1 = new CustomerLogisticsQuery()
.LivesInCity("London");
var query2 = new CustomerSalesQuery()
.WithPurchasesMoreThan(100)
.WithQuantitiesMoreThan(10);
customerRepository
.Query(query1.And(query2))
.Select()
.Dump();
復用上面的定義的查詢方法
以上這些都是改項目提供的方法,非常的好用
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化