一 OpenShift特性
1.1 OpenShift概述
Red Hat OpenShijft Container Platform (OpenShift)是一個容器應用程序平台,它為開發人員和IT組織提供了一個雲應用程序平台,用於在安全的、可伸縮的資源上部署新應用程序,而配置和管理開銷最小。
OpenShift構建於Red Hat Enterprise Linux、Docker和Kubernetes之上,為當今的企業級應用程序提供了一個安全且可伸縮的多租戶操作系統,同時還提供了集成的應用程序運行時和庫。
OpenShift帶來了健壯、靈活和可伸縮的特性。容器平台到客戶數據中心,使組織能夠實現滿足安全性、隱私性、遵從性和治理需求的平台。不願意管理自己的OpenShift集群的客戶可以使用Red Hat提供的公共雲平台OpenShift Online。
1.2 OpenShift特性
OpenShift容器平台和OpenShift Online都是基於OpenShift Origin開源軟件項目的,該項目本身使用了許多其他開源項目,如Docker和Kubernetes。
應用程序作為容器運行,容器是單個操作系統內的隔離分區。容器提供了許多與虛擬機相同的好處,比如安全性、存儲和網絡隔離,同時需要的硬件資源要少得多,啟動和終止也更快。OpenShift使用容器有助於提高平台本身及其承載的應用程序的效率、靈活性和可移植性。
OpenShift的主要特性如下:
- 自助服務平台:OpenShift允許開發人員使用Source-to-Image(S21)從模板或自己的源代碼管理存儲庫創建應用程序。系統管理員可以為用戶和項目定義資源配額和限制,以控制系統資源的使用。
- 多語言支持:OpenShift支持Java、Node.js、PHP、Perl以及直接來自Red Hat的Ruby。同時也包括來自合作夥伴和更大的Docker社區的許多其他代碼。MySQL、PostgreSQL和MongoDB數據庫。Red Hat還支持在OpenShift上本地運行的中間件產品,如Apache httpd、Apache Tomcat、JBoss EAP、ActiveMQ和Fuse。
- 自動化:OpenShift提供應用程序生命周期管理功能,當上游源或容器映像發生更改時,可以自動重新構建和重新部署容器。根據調度和策略擴展或故障轉移應用程序。
- 用戶界面:OpenShift提供用於部署和監視應用程序的web UI,以及用於遠程管理應用程序和資源的CLi。它支持Eclipse IDE和JBoss Developer Studio插件,以便開發人員可以繼續使用熟悉的工具,並支持REST APl與第三方或內部工具集成。
- 協作:OpenShift允許在組織內或與更大的社區共享項目。
- 可伸縮性和高可用性:OpenShift提供了容器多租戶和一個分佈式應用程序平台,其中包括彈性,以處理隨需增加的流量。它提供了高可用性,以便應用程序能夠在物理機器宕機等事件中存活下來。OpenShift提供了對容器健康狀況的自動發現和自動重新部署。
- 容器可移植性:在OpenShift中,應用程序和服務使用標準容器映像進行打包,組合應用程序使用Kubernetes進行管理。這些映像可以部署到基於這些基礎技術的其他平台上。
- 開源:沒有廠商鎖定。
- 安全性:OpenShift使用SELinux提供多層安全性、基於角色的訪問控制以及與外部身份驗證系統(如LDAP和OAuth)集成的能力。
- 動態存儲管理:OpenShift使用Kubernetes持久卷和持久卷聲明的方式為容器數據提供靜態和動態存儲管理
- 基於雲(或不基於雲):可以在裸機服務器、活來自多個供應商的hypervisor和大多數IaaS雲提供商上部署OpenShift容器平台。
- 企業級:Red Hat支持OpenShift、選定的容器映像和應用程序運行時。可信的第三方容器映像、運行時和應用程序由Red Hat認證。可以在OpenShift提供的高可用性的強化安全環境中運行內部或第三方應用程序。
- 日誌聚合和metrics:可以在中心節點收集、聚合和分析部署在OpenShift上的應用程序的日誌信息。OpenShift能夠實時收集關於應用程序的度量和運行時信息,並幫助不斷優化性能。
- 其他特性:OpenShift支持微服務體繫結構,OpenShift的本地特性足以支持DevOps流程,很容易與標準和定製的持續集成/持續部署工具集成。
二 OpenShift架構
2.1 OpenShift架構概述
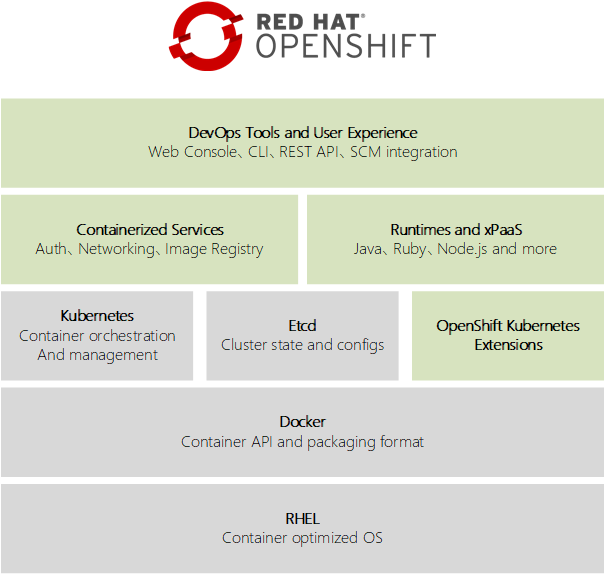
OpenShift容器平台是一組構建在Red Hat Enterprise Linux、Docker和Kubernetes之上的模塊化組件和服務。OpenShift增加了遠程管理、多租戶、增強的安全性、應用程序生命周期管理和面向開發人員的自服務接口。
OpenShift的架構:
- RHEL:基本操作系統是Red Hat Enterprise Linux;
- Docker:提供基本的容器管理API和容器image文件格式;
- Kubernetes:管理運行容器的主機集群(物理或虛擬主機)。它處理描述由多個資源組成的多容器應用程序的資源,以及它們如何互連;
- Etcd:一個分佈式鍵值存儲,Kubernetes使用它來存儲OpenShift集群中容器和其他資源的配置和狀態信息。
OpenShift在Docker + Kubernetes基礎設施之上添加了提供容器應用程序平台所需的更富豐的功能:
OpenShift-Kubernetes extensions:其它資源類型存儲在Etcd中,由Kubernetes管理。這些額外的資源類型形成OpenShift內部狀態和配置,以及由標準 Kubernetes管理的應用程序資源;
Containerized services:完成許多基礎設施功能,如網絡和授權。其中一些一直運行,另一些則按需啟動。OpenShift使用Docker和Kubernetes來實現大多數內部功能。即大多數OpenShift內部服務作為由Kubernetes管理的容器;
Runtimes and xPaaS:供開發人員使用的 base image,每個image都預配置了特定的runtime或db。xPaaS提供了一組用於JBoss中間件產品(如JBoss EAP和ActiveMQ)的 base image;
DevOps tools and user experience:OpenShift提供了Web UI和CLI管理工具,從而實現配置和監視應用程序、OpenShift服務和資源。Web和CLI工具都是由相同的REST api構建的,可供IDE和CI平台等外部工具使用。OpenShift 還可以訪問外部SCM存儲庫和容器registry,並將它們的構件引入OpenShift Cloud。
OpenShift不會向開發人員和系統管理員屏蔽Docker和Kubernetes的核心基礎設施。相反,它將它們用於內部服務,並允許將Docker和Kubernetes資源導入OpenShift集群,同時原始Docker和資源可以從OpenShift集群導出,並導入到其他基於docker的基礎設施中。
OpenShift添加到Docker + Kubernetes的主要價值是自動化開發工作流,因此應用程序的構建和部署在OpenShift集群中按照標準流程進行。開發者不需要知道底層Docker的細節。OpenShift接受應用程序,打包它,並將其作為容器啟動。
2.2 Master和nodes
OpenShift集群是一組節點服務器,它們運行容器,並由一組主服務器集中管理。服務器可以同時充當master和node,但是為了增加穩定性,這些角色通常是分開的。
OpenShift工作原理和交互視圖:
master節點運行OpenShift核心服務,如身份驗證,並未管理員提供API入口。
nodes節點運行包含應用程序的容器,容器又被分組成pod。
OpenShift master運行Kubernetes master服務和Etcd守護進程;
node運行Kubernetes kubelet和kube-proxy守護進程。
雖然在描述中通常沒有聲明,但實際上master本身也是node。
scheduler和management/replication是Kubernetes主服務,而Data Store是Etcd守護進程。
Kubernetes的調度單元是pod,它是一組共享虛擬網絡設備、內部IP地址、TCP/UDP端口和持久存儲的容器。pod可以是任何東西,從完整的企業應用程序(包括作為不同容器的每一層)到單個容器中的單個微服務。例如,一個pod,一個容器在Apache下運行PHP,另一個容器運行MySQL。
Kubernetes管理replicas來縮放pods。副本是一組共享相同定義的pod。
三 管理OpenShift
3.1 OpenShift項目及應用
除了Kubernetes的資源(如pods和services)之外,OpenShift還管理projects和users。一個projects對Kubernetes資源進行分組,以便用戶可以使用訪問權限。還可以為projects分配配額,從而限制了已定義的pod、volumes、services和其他資源。
OpenShift中沒有application的概念,OpenShift client提供了一個new-app命令。此命令在projects中創建資源,但它們都不是應用程序資源。這個命令是為標準開發人員工作流配置帶有公共資源的proiect的快捷方式。
OpenShift使用lables(標籤)對集群中的資源進行分類。默認情況下,OpenShift使用app標籤將相關資源分組到應用程序中。
3.2 使用Source-to-image構建映像
OpenShift允許開發人員使用標準源代碼管理倉庫(SCM)和集成開發環境(ide)來發布應用。
OpenShift中的source -to-lmage (S2I)流程從SCM倉庫中提取代碼,自動判斷所需的runtime,基於runtime啟動一個pod,在pod中編譯應用。
當編譯成功時,將在runtime image中添加層並形成新的image,推送進入OpenShift internal registry倉庫,接着基於這個image將創建新的pod,運行應用程序。
S2I可被視為已經內置到OpenShift中的完整的CI/CD管道。
CI/CD有不同的形式,根據具體場景表現不同。例如,可以使用外部CI工具(如Jenkins)啟動構建並運行測試,然後將新構建的映像標記為成功或失敗,將其推送到QA或生產。
3.2 管理OpenShift資源
OpenShift資源定義,如image、container、pod、service、builder、template等,都存儲在Etcd中,可以由OpenShift CLI, web控制台或REST API進行管理。
OpenShift的資源科通過JSON或YAML文件查看,並且在類似Git或版本控制的SCM中共享。OpenShift甚至可以直接從外部SCM檢索這些資源定義。
大多數OpenShift操作不需要實時響應,OpenShift命令和APIs通常創建或修改存儲在Etcd中的資源描述。Etcd然後通知OpenShift控制器,OpenShift控制器會就更改警告這些資源。
這些控制器採取行動,以便使得資源的最終態反應達到更改效果。例如,如果創建了一個新的pod資源,Kubernetes將在node上調度並啟動該pod,使用pod資源確定要使用哪個映像、要公開哪個端口,等等。或者一個模板被更改,從而指定應該有更多的pod來處理負載,OpenShift會安排額外的pod(副本)來滿足更新后的模板定義。
注意:雖然Docker和Kubernetes是OpenShift的底層,但是必須主要使用OpenShift CLi和OpenShift APls來管理應用程序和基礎設施。OpenShift增加了額外的安全和自動化功能,當直接使用Docker或Kubernetes命令和APls時,這些功能必須手動配置,或者根本不可用。因此強烈建議不要使用docker或Kubernetes的命令直接管理應用。
四 OpenShift網絡
4.1 OpenShift網絡概述
Docker網絡相對簡單,Docker創建一個虛擬內核橋接器(docker0網卡),並將每個容器網絡接口連接到它。
Docker本身沒有提供允許一個主機上的pod連接到另一個主機上的pod的方法。Docker也沒有提供嚮應用程序分配公共固定IP地址的方法,以便外部用戶可以訪問它。
但Kubernetes提供service和route資源來管理pods之間的網絡,以及從外部到pods的路由流量。service在不同pods之間提供負載均衡用於接收網絡請求,同時為service的所有客戶機(通常是其他pods)提供一個內部IP地址。
container和pods不需要知道其他pods在哪裡,它們只連接到service。route為service提供一個固定的惟一DNS名稱,使其對OpenShift集群之外的客戶端可見。
Kubernetes service和route資源需要外部(功能)插件支持。service需要軟件定義的網絡(SDN),它將在不同主機上的pod之間提供通信,route需要轉發或重定向來自外部客戶端的包到服務內部IP。
OpenShift提供了一個基於Open vSwitch的SDN,路由由分佈式HAProxy farm提供。
五 OpenShift持久性存儲
5.1 永久存儲
pod可以在一個節點上停止,並隨時在另一個節點上重新啟動。同時pod的默認存儲是臨時存儲,通過對於類似數據庫需要永久保存數據的應用不適合。
Kubernetes為管理容器的外部持久存儲提供了一個框架。Kubernetes提供了PersistentVolume資源,它可以在本地或網絡中定義存儲。pod資源可以使用PersistentVolumeClaim資源來訪問對應的持久存儲卷。
Kubernetes還指定了一個PersistentVolume資源是否可以在pod之間共享,或者每個pod是否需要具有獨佔訪問權的自己PersistentVolume。當pod移動到另一個節點時,它將保持與相同的PersistentVolumeClaim和PersistentVolumne資源的關聯。這意味着pod的持久存儲數據跟隨它,而不管它將在哪個節點上運行。
OpenShift向Kubernetes提供了多種VolumeProvider,如NFS、iSCSI、FC、Gluster或OpenStack Cinder。
OpenShift還通過StorageClass資源為應用程序提供動態存儲。使用動態存儲,可以選擇不同類型的後端存儲。後面存儲根據應用程序的需要劃分為不同的“tiers”。例如,可以定義一個名為“fast”的存儲類和另一個名為“slow”的存儲類,前者使用更高速的後端存儲,後者提供普通的存儲。當請求存儲時,最終用戶可以指定一個Persistentvolumeclaim,並使用一個註釋指定他們所需的StorageClass。
六 OpenShift高可用
6.1 OpenShift高可用概述
OpenShift平台集群的高可用性(HA)有兩個不同的方面:
OpenShift基礎設施本身的HA(即主機);
以及在OpenShift集群中運行的應用程序的HA。
默認情況下,OpenShift為master提供了完全支持的本機HA機制。
對於應用程序或“pods”,如果pod因任何原因丟失,Kubernetes將調度另一個副本,將其連接到服務層和持久存儲。如果整個節點丟失,Kubernetes會為它所有的pod安排替換節點,最終所有的應用程序都會重新可用。pod中的應用程序負責它們自己的狀態,因此它們需要自己維護應用程序狀態(如HTTP會話複製或數據庫複製)。
七 Image Streams
7.1 Image Streams
要在OpenShift中創建一個新的應用程序,除了應用程序源代碼之外,還需要一個base image(S2I builder image)。如果源代碼或image任何一個更新,就會生成一個新的image,並且基於此新image創建新的pod,同時替換舊的pod。
即當應用程序代碼發生更改時,容器映像需要更新,但如果構建器映像發生更改,則部署的pod也需要更新。
Image Streams包括由tag標識的大量的image。應用程序是針對Image Streams構建的。Image Streams可用於在創建新image時自動執行操作。構建和部署可以監視Image Streams,以便在添加新image時接收通知,並分別執行構建或部署。
OpenShift默認情況下提供了幾個Image Streams,包括許多流行的runtime和frameworks。
Image Streams tag是指向Image Streams中的image的別名。通常縮寫為istag。它包含一個image歷史記錄,表示為tag曾經指向的所有images的堆棧。
每當使用特定的istag標記一個新的或現有的image時,它都會被放在歷史堆棧的第一個位置(標記為latest)。之前tag再次指向舊的image。同時允許簡單的回滾,使標籤再次指向舊的image。 本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
※聚甘新