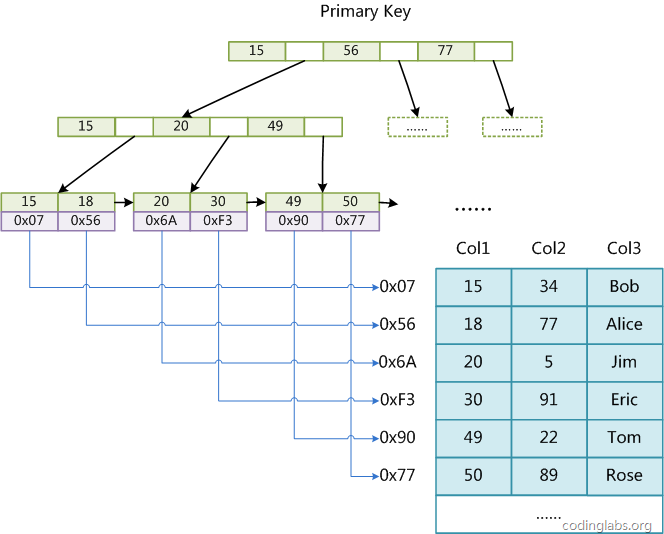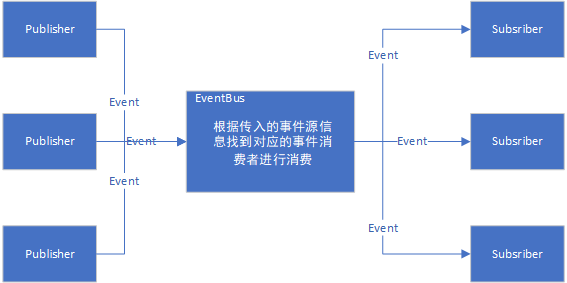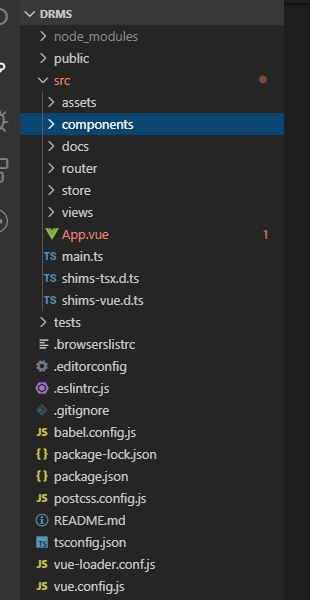
一年又要到年底了,vue3.0都已經出來了,我們也不能一直還停留在過去的js中,是時候學習並且在項目中使用一下Ts了。
如果說jsx是基於js的話,那麼tsx就是基於typescript的
廢話也不多說,讓我們開始寫一個Tsx形式的button組件,
ts真的不僅僅只有我們常常熟知的數據類型,還包括接口,類,枚舉,泛型,等等等,這些都是特別重要的
項目是基於vue-cli 3.0 下開發的,可以自己配置Ts,不會的話那你真的太難了
我們再compenonts中新建一個button文件夾,再建一個unit文件夾,button放button組件的代碼,unit,放一些公共使用模塊
我們再button文件夾下創建 ,index .tsx放的button源碼,index.less放的是樣式,css也是不可缺少的
分析一下button需要的一些東西
第一個當然是props,還有一個是點擊事件,所以我們第一步就定義一下這兩個類型
type ButtonProps = { tag: string, size: ButtonSize, type: ButtonType, text: String } type ButtonEvents = { onClick?(event: Event) :void } type ButtonSize = 'large' | 'normal' | 'small' | 'mini' type ButtonType = 'default' | 'primary' | 'info' | 'warning' | 'danger'
因為button是很簡單的組件,內部也沒有一些特別的狀態需要改變,所以我們用函數式組件的方式去寫(之後的render會用到這個方法)
function Button (h: CreateElement, props: ButtonProps, slots: DefaultSlots, ctx: RenderContext<ButtonProps>) { const { tag, size, type } = props let text console.log(slots) text = slots.default ? slots.default() : props.text function onClick (event: Event) { emit(ctx, 'click', event) } let classes = [size,type] return ( <tag onClick = {onClick} class = {classes} > {text} </tag> ) }
h 是一個預留參數,這裏並沒有用到 ,CreateElement 這個是vue從2.5之後提供的一個類型,也是為了方便在vue項目上使用ts
props 就是button組件的傳入的屬性,slots插槽,ctx,代表的是當前的組件,可以理解為當前rendercontext執行環境this
DefaultSlots是我們自定義的一個插槽類型
export type ScopedSlot<Props = any> = (props?: Props) => VNode[] | VNode | undefined; export type ScopedSlots = { [key: string]: ScopedSlot | undefined; }
插槽的內容我們都是需要從ctx中讀取的,默認插槽的key就是defalut,具名插槽就是具體的name
button放發內部還有一個具體的點擊事件,還有一個emit方法,從名字我們也可以看的出,他是粗發自定義事件的,我們這裏當然不能使用this.emit去促發,
所以我們需要單獨這個emit方法,我們知道組件內所以的自定義事件都是保存在listeners里的,我們從ctx中拿取到所以的listeners
import { RenderContext, VNodeData } from ‘vue’ // 從vue中引入一些類型
function emit (context: RenderContext, eventName: string, ...args: any[]) { const listeners = context.listeners[eventName] if (listeners) { if (Array.isArray(listeners)) { listeners.forEach(listener => { listener(...args) }) } else { listeners(...args) } }
這樣我們組件內部的事件觸發就完成了
我們的button肯定是有一些默認的屬性,所以,我們給button加上默認的屬性
Button.props = { text: String, tag: { type: String, default: 'button' }, type: { type: String, default: 'default' }, size: { type: String, default: 'normal' } }
我們定義一個通用的functioncomponent 類型
type FunctionComponent<Props=DefaultProps, PropsDefs = PropsDefinition<Props>> = { (h: CreateElement, Props:Props, slots: ScopedSlots, context: RenderContext<Props>): VNode |undefined, props?: PropsDefs }
PropsDefinition<T> 這個是vue內部提供的,對 props的約束定義
不管怎麼樣我們最終返回的肯定是一個對象,我們把這個類型也定義一下
ComponentOptions<Vue> 這個也是vue內部提供的
interface DrmsComponentOptions extends ComponentOptions<Vue> { functional?: boolean; install?: (Vue: VueConstructor) => void; }
最終生成一個組件對象
function transformFunctionComponent (fn:FunctionComponent): DrmsComponentOptions { return { functional: true, // 函數時組件,這個屬性一定要是ture,要不render方法,第二個context永遠為underfine props: fn.props, model: fn.model, render: (h, context): any => fn(h, context.props, unifySlots(context), context) } }
unifySlots 是讀取插槽的內容
// 處理插槽的內容 export function unifySlots (context: RenderContext) { // use data.scopedSlots in lower Vue version const scopedSlots = context.scopedSlots || context.data.scopedSlots || {} const slots = context.slots() Object.keys(slots).forEach(key => { if (!scopedSlots[key]) { scopedSlots[key] = () => slots[key] } }) return scopedSlots }
當然身為一個組件,我們肯定是要提供全局注入接口,並且能夠按需導入
所以我們給組件加上名稱和install方法,install 是 vue.use() 方法使用的,這樣我們能全部註冊組件
export function CreateComponent (name:string) { return function <Props = DefaultProps, Events = {}, Slots = {}> ( sfc:DrmsComponentOptions | FunctionComponent) { if (typeof sfc === 'function') { sfc = transformFunctionComponent(sfc) } sfc.functional = true sfc.name = 'drms-' + name sfc.install = install return sfc } }
index.tsx 中的最後一步,導出這個組件
export default CreateComponent('button')<ButtonProps, ButtonEvents>(Button)
還少一個install的具體實現方法,加上install方法,就能全局的按需導入了
function install (this:ComponentOptions<Vue>, Vue:VueConstructor) { const { name } = this Vue.component(name as string, this) }
最終實現的效果圖,事件的話也是完全ok的,這個我也是測過的
代碼參考的是vant的源碼:
該代碼已經傳到git: dev分支應該是代碼全的,master可能有些並沒有合併
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步”網站設計“幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益




 停車場充電設施建設協調會由中國國家發改委基礎產業司副司長鄭劍主持,就2016年第二批城市停車場項目配建充電基礎設施問題,與安徽、江蘇、江西、陝西、浙江、湖北、上海、大連、廈門等地方發展改革委、充電基礎設施服務企業和國家電網公司進行交流座談。 據國家能源局電力司初步統計,截至今年6月底,中國全國已建成公共充電樁8.1萬個,比去年底增長65%;隨車建成私人充電樁超過5萬個,比去年底增長約12%。1-6月全國新能源汽車充電量超過6億kWh,替代燃油約20萬噸,電動汽車的發展對能源結構調整和城市環境提升貢獻明顯。 為新能源汽車的推廣和應用創造良好的環境,國家能源局相關部門加快了推動充電樁政策規劃的落實,組織起草加快居民區充電基礎設施建設的檔。該文件有望7月份出臺,將有效推進居民區和工作場所建樁工作,合理優化公共充電樁佈局,提高公共充電樁利用率。 文章來源:中國發展網
停車場充電設施建設協調會由中國國家發改委基礎產業司副司長鄭劍主持,就2016年第二批城市停車場項目配建充電基礎設施問題,與安徽、江蘇、江西、陝西、浙江、湖北、上海、大連、廈門等地方發展改革委、充電基礎設施服務企業和國家電網公司進行交流座談。 據國家能源局電力司初步統計,截至今年6月底,中國全國已建成公共充電樁8.1萬個,比去年底增長65%;隨車建成私人充電樁超過5萬個,比去年底增長約12%。1-6月全國新能源汽車充電量超過6億kWh,替代燃油約20萬噸,電動汽車的發展對能源結構調整和城市環境提升貢獻明顯。 為新能源汽車的推廣和應用創造良好的環境,國家能源局相關部門加快了推動充電樁政策規劃的落實,組織起草加快居民區充電基礎設施建設的檔。該文件有望7月份出臺,將有效推進居民區和工作場所建樁工作,合理優化公共充電樁佈局,提高公共充電樁利用率。 文章來源:中國發展網