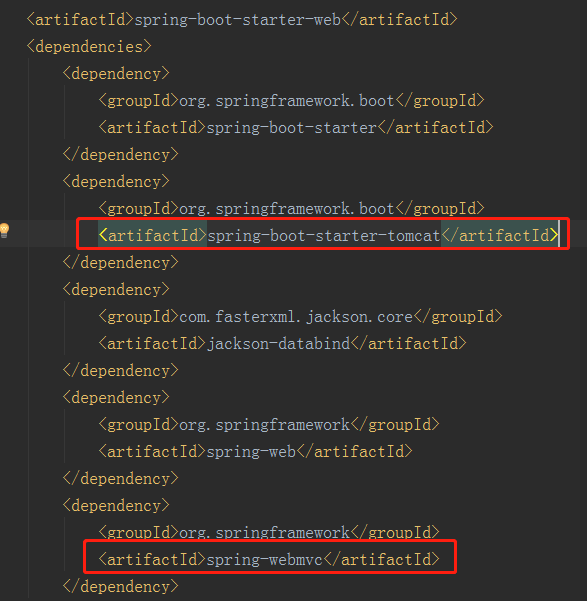
Spring Boot默認使用Tomcat作為嵌入式的Servlet容器,只要引入了spring-boot-start-web依賴,則默認是用Tomcat作為Servlet容器:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency>
Servlet容器的使用
默認servlet容器
我們看看spring-boot-starter-web這個starter中有什麼
核心就是引入了tomcat和SpringMvc,我們先來看tomcat
Spring Boot默認支持Tomcat,Jetty,和Undertow作為底層容器。如圖:
而Spring Boot默認使用Tomcat,一旦引入spring-boot-starter-web模塊,就默認使用Tomcat容器。
切換servlet容器
那如果我么想切換其他Servlet容器呢,只需如下兩步:
- 將tomcat依賴移除掉
- 引入其他Servlet容器依賴
引入jetty:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <exclusions> <exclusion> <!--移除spring-boot-starter-web中的tomcat--> <artifactId>spring-boot-starter-tomcat</artifactId> <groupId>org.springframework.boot</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <!--引入jetty--> <artifactId>spring-boot-starter-jetty</artifactId> </dependency>
Servlet容器自動配置原理
EmbeddedServletContainerAutoConfiguration
其中
EmbeddedServletContainerAutoConfiguration是嵌入式Servlet容器的自動配置類,該類在
spring-boot-autoconfigure.jar中的web模塊可以找到。
我們可以看到EmbeddedServletContainerAutoConfiguration被配置在spring.factories中,看過我前面文章的朋友應該知道SpringBoot自動配置的原理,這裏將EmbeddedServletContainerAutoConfiguration配置類加入到IOC容器中,接着我們來具體看看這個配置類:
@AutoConfigureOrder(Ordered.HIGHEST_PRECEDENCE) @Configuration @ConditionalOnWebApplication// 在Web環境下才會起作用 @Import(BeanPostProcessorsRegistrar.class)// 會Import一個內部類BeanPostProcessorsRegistrar public class EmbeddedServletContainerAutoConfiguration { @Configuration // Tomcat類和Servlet類必須在classloader中存在 // 文章開頭我們已經導入了web的starter,其中包含tomcat和SpringMvc // 那麼classPath下會存在Tomcat.class和Servlet.class @ConditionalOnClass({ Servlet.class, Tomcat.class }) // 當前Spring容器中不存在EmbeddedServletContainerFactory類型的實例 @ConditionalOnMissingBean(value = EmbeddedServletContainerFactory.class, search = SearchStrategy.CURRENT) public static class EmbeddedTomcat { @Bean public TomcatEmbeddedServletContainerFactory tomcatEmbeddedServletContainerFactory() { // 上述條件註解成立的話就會構造TomcatEmbeddedServletContainerFactory這個EmbeddedServletContainerFactory return new TomcatEmbeddedServletContainerFactory(); } } @Configuration @ConditionalOnClass({ Servlet.class, Server.class, Loader.class, WebAppContext.class }) @ConditionalOnMissingBean(value = EmbeddedServletContainerFactory.class, search = SearchStrategy.CURRENT) public static class EmbeddedJetty { @Bean public JettyEmbeddedServletContainerFactory jettyEmbeddedServletContainerFactory() { return new JettyEmbeddedServletContainerFactory(); } } @Configuration @ConditionalOnClass({ Servlet.class, Undertow.class, SslClientAuthMode.class }) @ConditionalOnMissingBean(value = EmbeddedServletContainerFactory.class, search = SearchStrategy.CURRENT) public static class EmbeddedUndertow { @Bean public UndertowEmbeddedServletContainerFactory undertowEmbeddedServletContainerFactory() { return new UndertowEmbeddedServletContainerFactory(); } } //other code... }
在這個自動配置類中配置了三個容器工廠的Bean,分別是:
-
TomcatEmbeddedServletContainerFactory
-
JettyEmbeddedServletContainerFactory
-
UndertowEmbeddedServletContainerFactory
這裏以大家熟悉的Tomcat為例,首先Spring Boot會判斷當前環境中是否引入了Servlet和Tomcat依賴,並且當前容器中沒有自定義的
EmbeddedServletContainerFactory的情況下,則創建Tomcat容器工廠。其他Servlet容器工廠也是同樣的道理。
EmbeddedServletContainerFactory
- 嵌入式Servlet容器工廠
public interface EmbeddedServletContainerFactory { EmbeddedServletContainer getEmbeddedServletContainer( ServletContextInitializer... initializers); }
內部只有一個方法,用於獲取嵌入式的Servlet容器。
該工廠接口主要有三個實現類,分別對應三種嵌入式Servlet容器的工廠類,如圖所示:
TomcatEmbeddedServletContainerFactory
以Tomcat容器工廠TomcatEmbeddedServletContainerFactory類為例:
public class TomcatEmbeddedServletContainerFactory extends AbstractEmbeddedServletContainerFactory implements ResourceLoaderAware { //other code... @Override public EmbeddedServletContainer getEmbeddedServletContainer( ServletContextInitializer... initializers) { //創建一個Tomcat Tomcat tomcat = new Tomcat(); //配置Tomcat的基本環節 File baseDir = (this.baseDirectory != null ? this.baseDirectory: createTempDir("tomcat")); tomcat.setBaseDir(baseDir.getAbsolutePath()); Connector connector = new Connector(this.protocol); tomcat.getService().addConnector(connector); customizeConnector(connector); tomcat.setConnector(connector); tomcat.getHost().setAutoDeploy(false); configureEngine(tomcat.getEngine()); for (Connector additionalConnector : this.additionalTomcatConnectors) { tomcat.getService().addConnector(additionalConnector); } prepareContext(tomcat.getHost(), initializers); //包裝tomcat對象,返回一個嵌入式Tomcat容器,內部會啟動該tomcat容器 return getTomcatEmbeddedServletContainer(tomcat); } }
首先會創建一個Tomcat的對象,並設置一些屬性配置,最後調用getTomcatEmbeddedServletContainer(tomcat)方法,內部會啟動tomcat,我們來看看:
protected TomcatEmbeddedServletContainer getTomcatEmbeddedServletContainer( Tomcat tomcat) { return new TomcatEmbeddedServletContainer(tomcat, getPort() >= 0); }
該函數很簡單,就是來創建Tomcat容器並返回。看看TomcatEmbeddedServletContainer類:
public class TomcatEmbeddedServletContainer implements EmbeddedServletContainer { public TomcatEmbeddedServletContainer(Tomcat tomcat, boolean autoStart) { Assert.notNull(tomcat, "Tomcat Server must not be null"); this.tomcat = tomcat; this.autoStart = autoStart; //初始化嵌入式Tomcat容器,並啟動Tomcat initialize(); } private void initialize() throws EmbeddedServletContainerException { TomcatEmbeddedServletContainer.logger .info("Tomcat initialized with port(s): " + getPortsDescription(false)); synchronized (this.monitor) { try { addInstanceIdToEngineName(); try { final Context context = findContext(); context.addLifecycleListener(new LifecycleListener() { @Override public void lifecycleEvent(LifecycleEvent event) { if (context.equals(event.getSource()) && Lifecycle.START_EVENT.equals(event.getType())) { // Remove service connectors so that protocol // binding doesn't happen when the service is // started. removeServiceConnectors(); } } }); // Start the server to trigger initialization listeners //啟動tomcat this.tomcat.start(); // We can re-throw failure exception directly in the main thread rethrowDeferredStartupExceptions(); try { ContextBindings.bindClassLoader(context, getNamingToken(context), getClass().getClassLoader()); } catch (NamingException ex) { // Naming is not enabled. Continue } // Unlike Jetty, all Tomcat threads are daemon threads. We create a // blocking non-daemon to stop immediate shutdown startDaemonAwaitThread(); } catch (Exception ex) { containerCounter.decrementAndGet(); throw ex; } } catch (Exception ex) { stopSilently(); throw new EmbeddedServletContainerException( "Unable to start embedded Tomcat", ex); } } } }
到這裏就啟動了嵌入式的Servlet容器,其他容器類似。
Servlet容器啟動原理
SpringBoot啟動過程
我們回顧一下前面講解的SpringBoot啟動過程,也就是run方法:
public ConfigurableApplicationContext run(String... args) { // 計時工具 StopWatch stopWatch = new StopWatch(); stopWatch.start(); ConfigurableApplicationContext context = null; Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>(); configureHeadlessProperty(); // 第一步:獲取並啟動監聽器 SpringApplicationRunListeners listeners = getRunListeners(args); listeners.starting(); try { ApplicationArguments applicationArguments = new DefaultApplicationArguments(args); // 第二步:根據SpringApplicationRunListeners以及參數來準備環境 ConfigurableEnvironment environment = prepareEnvironment(listeners,applicationArguments); configureIgnoreBeanInfo(environment); // 準備Banner打印器 - 就是啟動Spring Boot的時候打印在console上的ASCII藝術字體 Banner printedBanner = printBanner(environment); // 第三步:創建Spring容器 context = createApplicationContext(); exceptionReporters = getSpringFactoriesInstances( SpringBootExceptionReporter.class, new Class[] { ConfigurableApplicationContext.class }, context); // 第四步:Spring容器前置處理 prepareContext(context, environment, listeners, applicationArguments,printedBanner); // 第五步:刷新容器 refreshContext(context); // 第六步:Spring容器後置處理 afterRefresh(context, applicationArguments); // 第七步:發出結束執行的事件 listeners.started(context); // 第八步:執行Runners this.callRunners(context, applicationArguments); stopWatch.stop(); // 返回容器 return context; } catch (Throwable ex) { handleRunFailure(context, listeners, exceptionReporters, ex); throw new IllegalStateException(ex); } }
我們回顧一下第三步:創建Spring容器
public static final String DEFAULT_CONTEXT_CLASS = "org.springframework.context." + "annotation.AnnotationConfigApplicationContext"; public static final String DEFAULT_WEB_CONTEXT_CLASS = "org.springframework." + "boot.context.embedded.AnnotationConfigEmbeddedWebApplicationContext"; protected ConfigurableApplicationContext createApplicationContext() { Class<?> contextClass = this.applicationContextClass; if (contextClass == null) { try { //根據應用環境,創建不同的IOC容器 contextClass = Class.forName(this.webEnvironment ? DEFAULT_WEB_CONTEXT_CLASS : DEFAULT_CONTEXT_CLASS); } } return (ConfigurableApplicationContext) BeanUtils.instantiate(contextClass); }
創建IOC容器,如果是web應用,則創建
AnnotationConfigEmbeddedWebApplicationContext的IOC容器;如果不是,則創建AnnotationConfigApplicationContext的IOC容器;很明顯我們創建的容器是AnnotationConfigEmbeddedWebApplicationContext
,接着我們來看看
第五步,刷新容器
refreshContext(context);
private void refreshContext(ConfigurableApplicationContext context) { refresh(context); } protected void refresh(ApplicationContext applicationContext) { Assert.isInstanceOf(AbstractApplicationContext.class, applicationContext); //調用容器的refresh()方法刷新容器 ((AbstractApplicationContext) applicationContext).refresh(); }
容器刷新過程
調用抽象父類AbstractApplicationContext的refresh()方法;
AbstractApplicationContext
1 public void refresh() throws BeansException, IllegalStateException { 2 synchronized (this.startupShutdownMonitor) { 3 /** 4 * 刷新上下文環境 5 */ 6 prepareRefresh(); 7 8 /** 9 * 初始化BeanFactory,解析XML,相當於之前的XmlBeanFactory的操作, 10 */ 11 ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory(); 12 13 /** 14 * 為上下文準備BeanFactory,即對BeanFactory的各種功能進行填充,如常用的註解@Autowired @Qualifier等 15 * 添加ApplicationContextAwareProcessor處理器 16 * 在依賴注入忽略實現*Aware的接口,如EnvironmentAware、ApplicationEventPublisherAware等 17 * 註冊依賴,如一個bean的屬性中含有ApplicationEventPublisher(beanFactory),則會將beanFactory的實例注入進去 18 */ 19 prepareBeanFactory(beanFactory); 20 21 try { 22 /** 23 * 提供子類覆蓋的額外處理,即子類處理自定義的BeanFactoryPostProcess 24 */ 25 postProcessBeanFactory(beanFactory); 26 27 /** 28 * 激活各種BeanFactory處理器,包括BeanDefinitionRegistryBeanFactoryPostProcessor和普通的BeanFactoryPostProcessor 29 * 執行對應的postProcessBeanDefinitionRegistry方法 和 postProcessBeanFactory方法 30 */ 31 invokeBeanFactoryPostProcessors(beanFactory); 32 33 /** 34 * 註冊攔截Bean創建的Bean處理器,即註冊BeanPostProcessor,不是BeanFactoryPostProcessor,注意兩者的區別 35 * 注意,這裏僅僅是註冊,並不會執行對應的方法,將在bean的實例化時執行對應的方法 36 */ 37 registerBeanPostProcessors(beanFactory); 38 39 /** 40 * 初始化上下文中的資源文件,如國際化文件的處理等 41 */ 42 initMessageSource(); 43 44 /** 45 * 初始化上下文事件廣播器,並放入applicatioEventMulticaster,如ApplicationEventPublisher 46 */ 47 initApplicationEventMulticaster(); 48 49 /** 50 * 給子類擴展初始化其他Bean 51 */ 52 onRefresh(); 53 54 /** 55 * 在所有bean中查找listener bean,然後註冊到廣播器中 56 */ 57 registerListeners(); 58 59 /** 60 * 設置轉換器 61 * 註冊一個默認的屬性值解析器 62 * 凍結所有的bean定義,說明註冊的bean定義將不能被修改或進一步的處理 63 * 初始化剩餘的非惰性的bean,即初始化非延遲加載的bean 64 */ 65 finishBeanFactoryInitialization(beanFactory); 66 67 /** 68 * 通過spring的事件發布機制發布ContextRefreshedEvent事件,以保證對應的監聽器做進一步的處理 69 * 即對那種在spring啟動后需要處理的一些類,這些類實現了ApplicationListener<ContextRefreshedEvent>, 70 * 這裏就是要觸發這些類的執行(執行onApplicationEvent方法) 71 * spring的內置Event有ContextClosedEvent、ContextRefreshedEvent、ContextStartedEvent、ContextStoppedEvent、RequestHandleEvent 72 * 完成初始化,通知生命周期處理器lifeCycleProcessor刷新過程,同時發出ContextRefreshEvent通知其他人 73 */ 74 finishRefresh(); 75 } 76 77 finally { 78 79 resetCommonCaches(); 80 } 81 } 82 }
我們看第52行的方法:
protected void onRefresh() throws BeansException { }
很明顯抽象父類AbstractApplicationContext中的onRefresh是一個空方法,並且使用protected修飾,也就是其子類可以重寫onRefresh方法,那我們看看其子類AnnotationConfigEmbeddedWebApplicationContext中的onRefresh方法是如何重寫的,AnnotationConfigEmbeddedWebApplicationContext又繼承EmbeddedWebApplicationContext,如下:
public class AnnotationConfigEmbeddedWebApplicationContext extends EmbeddedWebApplicationContext {
那我們看看其父類EmbeddedWebApplicationContext 是如何重寫onRefresh方法的:
EmbeddedWebApplicationContext
@Override protected void onRefresh() { super.onRefresh(); try { //核心方法:會獲取嵌入式的Servlet容器工廠,並通過工廠來獲取Servlet容器 createEmbeddedServletContainer(); } catch (Throwable ex) { throw new ApplicationContextException("Unable to start embedded container", ex); } }
在createEmbeddedServletContainer方法中會獲取嵌入式的Servlet容器工廠,並通過工廠來獲取Servlet容器:
1 private void createEmbeddedServletContainer() { 2 EmbeddedServletContainer localContainer = this.embeddedServletContainer; 3 ServletContext localServletContext = getServletContext(); 4 if (localContainer == null && localServletContext == null) { 5 //先獲取嵌入式Servlet容器工廠 6 EmbeddedServletContainerFactory containerFactory = getEmbeddedServletContainerFactory(); 7 //根據容器工廠來獲取對應的嵌入式Servlet容器 8 this.embeddedServletContainer = containerFactory.getEmbeddedServletContainer(getSelfInitializer()); 9 } 10 else if (localServletContext != null) { 11 try { 12 getSelfInitializer().onStartup(localServletContext); 13 } 14 catch (ServletException ex) { 15 throw new ApplicationContextException("Cannot initialize servlet context",ex); 16 } 17 } 18 initPropertySources(); 19 }
關鍵代碼在第6和第8行,先獲取Servlet容器工廠,然後根據容器工廠來獲取對應的嵌入式Servlet容器
獲取Servlet容器工廠
protected EmbeddedServletContainerFactory getEmbeddedServletContainerFactory() { //從Spring的IOC容器中獲取EmbeddedServletContainerFactory.class類型的Bean String[] beanNames = getBeanFactory().getBeanNamesForType(EmbeddedServletContainerFactory.class); //調用getBean實例化EmbeddedServletContainerFactory.class return getBeanFactory().getBean(beanNames[0], EmbeddedServletContainerFactory.class); }
我們看到先從Spring的IOC容器中獲取EmbeddedServletContainerFactory.class類型的Bean,然後調用getBean實例化EmbeddedServletContainerFactory.class,大家還記得我們第一節Servlet容器自動配置類EmbeddedServletContainerAutoConfiguration中注入Spring容器的對象是什麼嗎?當我們引入spring-boot-starter-web這個啟動器后,會注入TomcatEmbeddedServletContainerFactory這個對象到Spring容器中,所以這裏獲取到的Servlet容器工廠是TomcatEmbeddedServletContainerFactory,然後調用
TomcatEmbeddedServletContainerFactory的getEmbeddedServletContainer方法獲取Servlet容器,並且啟動Tomcat,大家可以看看文章開頭的getEmbeddedServletContainer方法。
大家看一下第8行代碼獲取Servlet容器方法的參數getSelfInitializer(),這是個啥?我們點進去看看
private ServletContextInitializer getSelfInitializer() { //創建一個ServletContextInitializer對象,並重寫onStartup方法,很明顯是一個回調方法 return new ServletContextInitializer() { public void onStartup(ServletContext servletContext) throws ServletException { EmbeddedWebApplicationContext.this.selfInitialize(servletContext); } }; }
創建一個ServletContextInitializer對象,並重寫onStartup方法,很明顯是一個回調方法,這裏給大家留一點疑問:
- ServletContextInitializer對象創建過程是怎樣的?
- onStartup是何時調用的?
- onStartup方法的作用是什麼?
ServletContextInitializer是 Servlet 容器初始化的時候,提供的初始化接口。這裏涉及到Servlet、Filter實例的註冊,我們留在下一篇具體講
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※專營大陸快遞台灣服務
※台灣快遞大陸的貨運公司有哪些呢?





 停車場充電設施建設協調會由中國國家發改委基礎產業司副司長鄭劍主持,就2016年第二批城市停車場項目配建充電基礎設施問題,與安徽、江蘇、江西、陝西、浙江、湖北、上海、大連、廈門等地方發展改革委、充電基礎設施服務企業和國家電網公司進行交流座談。 據國家能源局電力司初步統計,截至今年6月底,中國全國已建成公共充電樁8.1萬個,比去年底增長65%;隨車建成私人充電樁超過5萬個,比去年底增長約12%。1-6月全國新能源汽車充電量超過6億kWh,替代燃油約20萬噸,電動汽車的發展對能源結構調整和城市環境提升貢獻明顯。 為新能源汽車的推廣和應用創造良好的環境,國家能源局相關部門加快了推動充電樁政策規劃的落實,組織起草加快居民區充電基礎設施建設的檔。該文件有望7月份出臺,將有效推進居民區和工作場所建樁工作,合理優化公共充電樁佈局,提高公共充電樁利用率。 文章來源:中國發展網
停車場充電設施建設協調會由中國國家發改委基礎產業司副司長鄭劍主持,就2016年第二批城市停車場項目配建充電基礎設施問題,與安徽、江蘇、江西、陝西、浙江、湖北、上海、大連、廈門等地方發展改革委、充電基礎設施服務企業和國家電網公司進行交流座談。 據國家能源局電力司初步統計,截至今年6月底,中國全國已建成公共充電樁8.1萬個,比去年底增長65%;隨車建成私人充電樁超過5萬個,比去年底增長約12%。1-6月全國新能源汽車充電量超過6億kWh,替代燃油約20萬噸,電動汽車的發展對能源結構調整和城市環境提升貢獻明顯。 為新能源汽車的推廣和應用創造良好的環境,國家能源局相關部門加快了推動充電樁政策規劃的落實,組織起草加快居民區充電基礎設施建設的檔。該文件有望7月份出臺,將有效推進居民區和工作場所建樁工作,合理優化公共充電樁佈局,提高公共充電樁利用率。 文章來源:中國發展網