本文為作者原創,轉載請註明出處:
通常,我們用於調試的計算機無法遠程訪問位於局域網中的待調試設備。通過 ssh 的端口轉發(又稱 ssh 隧道)技術,可以實現這種遠程調試功能。
下文中,sshc 指 ssh 客戶端,sshd 指 ssh 服務器。
1. ssh 端口轉發模式簡介
ssh 客戶端運行於本地機器,它的作用是:登錄到目標機器並在目標機器上執行命令。它可以建立一個安全通道,為不安全網絡上兩個不受信任的主機提供安全的加密通信。X11 連接、任意 TCP 端口和 UNIX 域套接字也可以通過 ssh 安全通道進行轉發。
ssh 連接並登錄到指定的主機名(用戶名可選)。如果指定了命令,命令將在遠程主機上執行,而不是在本機 shell 里執行。
1.1 ssh 常用選項簡介
ssh 端口轉發相關的常用選項如下:
-C
請求壓縮所有數據(包括 stdin、stdout、stderr 和用於轉發的 X11、TCP 和 UNIX 域連接的數據)。壓縮算法與 gzip 使用的算法相同,壓縮級別由 ssh 協議版本 1 的 CompressionLevel 選項控制。在調製解調器線路和其他慢速連接上採用壓縮是可取的,但它會減慢快速網絡上的速度。
-f
請求 ssh 在執行命令之前轉到後台。如果用戶希望 ssh 在後台運行,但 ssh 需要用戶提供密碼或口令,使用 -f 選項就很有用,在用戶輸入密碼之後,ssh 就會轉入後台運行。這個選項隱含了 -n 選項的功能(-n 選項將 stdin 重定向到 /dev/null,從而避免後台進程讀 stdin)。在遠程站點上啟動 X11 程序的推薦方法是使用 “ssh -f host xterm” 。
如果 ExitOnForwardFailure 配置選項設置的是 “yes”,則使用 -f 選項啟動的 ssh 客戶端會等所有的遠程端口轉發建立成功后才將自己轉到後台運行。
-n
將 stdin 重定向到 /dev/null (實際上是為了防止後台進程從stdin讀取數據)。當 ssh 在後台運行時必須使用此選項。
一個常見的技巧是使用它在目標機器上運行 X11 程序。例如,ssh -n shadow.cs.hut.fi emacs & 將在 shadows.cs.hut.fi 上啟動 emacs 程序。X11 的連接將通過加密通道自動轉發。ssh 程序將在後台運行。(如果 ssh 需要請求密碼或口令,則此操作無效;參見-f選項。)
-N
不執行遠程命令。此選項用於只需要端口轉發功能時。
-g
允許遠程主機連接到本地轉發端口。如果用於多路復用連接,則必須在主進程上指定此選項。
-t
強制分配一個偽終端。在目標機上執行任意的基於屏幕的程序時(例如,實現菜單服務),分配偽終端很有用。使用多個 -t 選項則會強制分配終端,即使 ssh 沒有本地終端。
-T
禁止分配偽終端。
-L [bind_address:]port:host:hostport
-L [bind_address:]port:remote_socket
-L local_socket:host:hostport
-L local_socket:remote_socket
數據從本機轉發到遠程。本機上指定 TCP 端口或 UNIX 套接字的連接將被轉發到目標機上指定端口或套接字。
上述參數中,bind_address 指本地地址;port 指本地端口;local_socket 指本地 UNIX 套接字;host 指遠程主機地址;hostport 指遠程端口;remote_socket 指遠程 UNIX 套接字。
本地(ssh 客戶端)與遠程(ssh 服務端)建立一條連接,此連接的形式有四種:
本地 [bind_address:]port <====> 遠程 host:hostport
本地 [bind_address:]port <====> 遠程 remote_socket
本地 local_socket <====> 遠程 host:hostport
本地 local_socket <====> 遠程 remote_socket
位於本機的 ssh 客戶端會分配一個套接字來監聽本地 TCP 端口(port),此套接字可綁定本機地址(bind_address, 可選,本機不同網卡具有不同的 IP 地址)或本地 UNIX 套接字(local_socket)。每當一個連接建立於本地端口或本地套接字時,此連接就會通過安全通道進行轉發。
也可在配置文件中設置端口轉發功能。只有超級用戶可以轉發特權端口。
默認情況下,本地端口是根據 GatewayPorts 設置選項綁定的。但是,使用顯式的bind_address 可將連接綁定到指定地址。bind_address 值是 “localhost”時,表示僅監聽本機內部數據[TODO: 待驗證],值為空或“*”時,表示監聽本機所有網卡的監聽端口。
注意:localhost 是個域名,不是地址,它可以被配置為任意的 IP 地址,不過通常情況下都指向 127.0.0.1(ipv4)和 。127.0.0.1 這個地址通常分配給 loopback 接口。loopback 是一個特殊的網絡接口(可理解成虛擬網卡),用於本機中各個應用之間的網絡交互。
GatewayPorts 說明 (查閱 man sshd_config):指定是否允許遠程主機(ssh客戶端)連接到本機(ssh服務端)轉發端口。默認情況下,sshd(8)將遠程端口轉發綁定到環回地址,這將阻止其他遠程主機連接到本機轉發端口。GatewayPorts 也可設置為將將遠程端口轉發綁定到非環回地址,從而允許其他遠程主機連接到本機。GatewayPorts 值“no”,表示強制遠程端口轉發僅對本機可用;值“yes”,表示強制遠程端口轉發綁定到通配符地址;值“clientspecified”,表示允許客戶端選擇轉發綁定到的地址。默認是“no”。
-R [bind_address:]port:host:hostport
-R [bind_address:]port:local_socket
-R remote_socket:host:hostport
-R remote_socket:local_socket
此選項在本地機上執行,目標機上指定 TCP 端口或 UNIX 套接字的連接將被轉發到本機上指定端口或套接字。
上述參數中,bind_address 指遠程地址;port 指遠程端口;remote_socket 指遠程 UNIX 套接字;host 指本地地址;hostport 指本地端口;local_socket 指本地 UNIX 套接字。
工作原理:位於遠程的 ssh 服務端會分配一個套接字來監聽 TCP 端口或 UNIX 套接字。當目標機(服務端)上有新的連接建立時,此連接會通過安全通道進行轉發,本地機執行當前命令的進程收到此轉發的連接后,會在本機內部新建一條 ssh 連接,連接到當前選項中指定的端口或套接字。參 2.3 節分析。
也可在配置文件中設置端口轉發功能。只有超級用戶可以轉發特權端口。
默認情況下,目標機(服務端)上的 TCP 監聽套接字只綁定迴環接口。也可將目標機上的監聽套接字綁定指定的 bind_address 地址。bind_address 值為空或 “*” 時,表示目標機上的監聽套接字會監聽目標機上的所有網絡接口。僅當目標機上 GatewayPorts 設置選項使能時,通過此選項為目標機指定 bind_address 才能綁定成功(參考 sshd_config(5))。
如果 port 參數是 ‘0’,目標機(服務端)可在運行時動態分配監聽端口並通知本地機(客戶端),如果同時指定了 “-O forward” 選項,則動態分配的監聽端口會被打印在標準輸出上。
-D [bind_address:]port
指定本地“動態”應用程序級端口轉發。它的工作方式是分配一個套接字來監聽本地端口(可選綁定指定的 bind_address)。每當連接到此端口時,連接都通過安全通道進行轉發,然後使用應用程序協議確定將遠程計算機連接到何處。目前支持 SOCKS4 和 SOCKS5 協議,ssh 將充當 SOCKS 服務器。只有 root 用戶可以轉發特權端口。還可以在配置文件中指定動態端口轉發。
IPv6 地址可以通過將地址括在方括號中來指定。只有超級用戶可以轉發特權端口。默認情況下,本地端口是根據 GatewayPorts 設置選項進行綁定的。但是,可以使用顯式的 bind_address 將連接綁定到特定的地址。bind_address 值為 “localhost” 時表示監聽端口僅綁定為本地使用,而空地址或 “*” 表示監聽所有網絡接口的此端口。
1.2 ssh 端口轉發模式
ssh 的端口轉發有三種模式:
-
本地:ssh -C -f -N -g -L local_listen_port:remote_host:remote_port agent_user@agent_host
將本地機監聽端口 local_listen_port 上的數據轉發到遠程端口 remote_host:remote_port
-
遠程:ssh -C -f -N -g -R agent_listen_port:local_host:local_port agent_user@agent_host
將代理機監聽端口 agent_listen_port 上的數據轉發到本地端口 local_host:local_port
-
動態:ssh -C -f -N -g -D listen_port agent_user@agent_host
2. 利用 ssh 隧道建立遠程調試環境
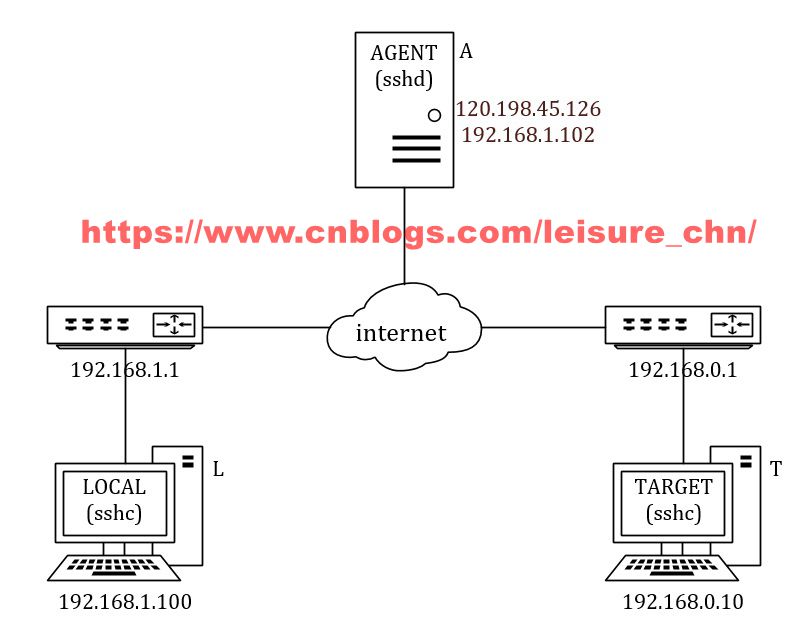
組網環境下設備角色如下:
代理機:把一個具有公網 IP 的中間服務器用作 ssh 代理,將這台代理機稱作代理 A(Agent)。
目標機:把待調試的目標機器稱作目標機 T(Target)。目標機通常是待調試的設備,處於局域網內,外網無法直接訪問內網中的設備。
本地機:把調試用的本地計算機稱作本地機 L(Local)。本地機通常也位於局域網內。
L 和 T 無法互相訪問,但 L 和 T 都能訪問 A。我們將 T 通過 ssh 連接到A,將 L 也通過 ssh 連接到A,A 用於轉發數據,這樣就能使用本地計算機 L 來訪問遠端設備 R。
2.1 目標機 T (sshc)
2.1.1 shell 中 T 連接 A
目標機 T 上的 sshc 連接代理機 A 上的 sshd:
ssh -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
這條命令的作用:
1. 建立一條 ssh 連接,T 上的 ssh 客戶端連接到 A 上的 ssh 服務器,A 的 IP 是 120.198.45.126,端口號是 10022,賬號是10022;
2. 如果有其他 ssh 客戶端連接到了 A 的 10022 端口上,則 A 會將這條連接轉發到 T,T 在內部建立新的連接,連接到本機 22 端口。
這條命令在 T 上執行。在 T 連接 A 這條命令里,T 是本地主機(local),A 是遠程主機(remote)。
解釋一下此命令各選項:
- -T 不分配偽終端;
- -f 使 ssh 進程在用戶輸入密碼之後轉入後台運行;
- -N 不執行遠程指令,即遠程主機(代理機A)不需執行指令,只作端口轉發;
- -g 允許遠程主機(代理機A)連接到本地轉發端口;
- -R 將遠程主機(代理機A)指定端口上的連接轉發到本機端口;
- frank@120.198.45.126
表示使用遠程主機 120.198.45.126 上的用戶 frank 來連接遠程主機;
- :10022:127.0.0.1:22
表示本機迴環接口(127.0.0.1,也可使用本機其他網絡接口的地址,比如以太網 IP 或 WiFi IP)的 22 端口連接到遠程主機的 10022 接口,因遠程主機 10022 綁定的地址為空,所以遠程主機會監聽其所有網絡接口的 10022 端口。
在目標機 shell 中查看連接是否建立:
root@localhost:~# ps | grep ssh
22850 root 2492 S ssh -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
22894 root 3500 S grep ssh
在目標機 shell 中關閉 ssh 連接:
kill -9 $(pidof ssh)
此時在目標機 T 和代理機 A 中查看 ssh 連接信息,兩端都可以看到 ssh 連接不存在了。
2.1.2 C 代碼中 T 連接 A 的處理
C 代碼中主要還是調用 2.1.1 節中的命令。但是由 C 代碼編譯生成的進程無法在命令行和用戶進行交互,因此要避免交互問題。
1. 避免首次連接時的 y/n(或yes/no) 詢問
如果是首次登錄代理機 A,本機(目標機 T)沒有 A 的信息,需用用戶手動輸入 y 之後才能繼續。打印如下:
root@localhost:~# ssh -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
Host '120.198.45.126' is not in the trusted hosts file.
(ssh-rsa fingerprint md5 86:09:0c:1b:fd:0b:02:8c:29:62:7f:ff:70:1b:64:f5)
Do you want to continue connecting? (y/n)
如果 T 上有 A 的信息,可通過執行刪除操作:rm ~/.ssh/known_hosts 再進行上述測試。
如果是在 C 代碼中執行登錄命令,進程在後台自動運行,是無法和用戶進行交互的。為了避免交互動作,應該禁止 ssh 發出 y/n 的詢問。
如果 ssh 客戶端是 dropbear ssh,則添加 -y 參數,如下:
ssh -y -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
如果 ssh 客戶端是 openssh,則添加 -o StrictHostKeyChecking=no 選項,如下:
ssh -o "StrictHostKeyChecking no" -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
2. 避免輸入登錄密碼
避免由用戶手動輸入登錄密碼有如下方法:
1) 用 ssh-copy-id 把本地主機的公鑰複製到遠程主機的authorized_keys文件上,登錄不需要輸入密碼。
2) 用 expect 調用 shell 腳本,向 shell 腳本發送密碼。這種方式是模擬鍵盤輸入。
3) 如果是 openssh,則用 sshpass 向 ssh 命令行傳遞密碼。如果是 dropbear,則通過 DROPBEAR_PASSWORD 環境變量向 ssh 命令行傳遞密碼。
我們採用第 3 種方法。
假如代理機 A 上用戶 frank 密碼是 123456,則最終 C 代碼里應執行的指令如下:
# openssh
sshpass -p '123456' ssh -o "StrictHostKeyChecking no" -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
# dropbear
DROPBEAR_PASSWORD='123456' ssh -y -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
dropbear 無法接收 DROPBEAR_PASSWORD 變量傳遞密碼的處理方法:
dropbear 包含 ssh 客戶端和 ssh 服務器,體積小巧,常用於嵌入式設備。dropbear ssh 無法接收 sshpass 傳入的密碼信息。但 dropbear ssh 可以通過環境變量 DROPBEAR_PASSWORD 傳入密碼信息。openwrt 從某一版開始,通過打補丁的方式禁用了 DROPBEAR_PASSWORD 選項,我們可以找到對應的補丁,開啟 DROPBEAR_PASSWORD 選項,再重新編譯生成 dropbear。如下:
修改 dropbear patch 文件(如下路徑位於 openwrt 源碼根目錄):
vim package/network/services/dropbear/patches/120-openwrt_options.patch
將如下幾行刪除:
@@ -226,7 +226,7 @@ much traffic. */
* note that it will be provided for all "hidden" client-interactive
* style prompts - if you want something more sophisticated, use
* SSH_ASKPASS instead. Comment out this var to remove this functionality.*/
-#define DROPBEAR_PASSWORD_ENV "DROPBEAR_PASSWORD"
+/*#define DROPBEAR_PASSWORD_ENV "DROPBEAR_PASSWORD"*/
/* Define this (as well as ENABLE_CLI_PASSWORD_AUTH) to allow the use of
* a helper program for the ssh client. The helper program should be
重新編譯生成 dropbear,並替換設備里已安裝的 dropbear。
#define DEFAULT_SSH_AGENT_HOST "120.198.45.126"
#define DEFAULT_SSH_AGENT_PORT "10022"
#define DEFAULT_SSH_AGENT_USER "ssha_debug"
#define DEFAULT_SSH_AGENT_PASSWD "220011ssha"
int login_to_ssh_agent(const char *host, const char *port, const char *user, const char *passwd)
{
// openssh client:
// sshpass -p '123456' ssh -o "StrictHostKeyChecking no" -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
// dropbear ssh clent:
// DROPBEAR_PASSWORD='123456' ssh -y -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
char cmd[256];
snprintf(cmd, sizeof(cmd), "DROPBEAR_PASSWORD='%s' ssh -y -T -f -N -g -R :%s:127.0.0.1:22 %s@%s",
(passwd != NULL) ? passwd : DEFAULT_SSH_AGENT_PASSWD,
(port != NULL) ? port : DEFAULT_SSH_AGENT_PORT,
(user != NULL) ? user : DEFAULT_SSH_AGENT_USER,
(host != NULL) ? host : DEFAULT_SSH_AGENT_HOST);
printf("login to ssh agent: \n%s\n", cmd);
system(cmd);
return 0;
}
2.2 代理機 A (sshd)
在 /etc/ssh/sshd_config 中添加如下幾行后重啟 ssh 服務:
GatewayPorts yes
UseDNS no
GSSAPIAuthentication no
目標機 T 發起連接后,在代理機 A 上查詢目標機 T 是否連接成功:
sudo netstat -anp | grep 10022
打印形如:
tcp 0 0 0.0.0.0:10022 0.0.0.0:* LISTEN 8264/sshd: frank
tcp6 0 0 :::10022 :::* LISTEN 8264/sshd: frank
上述打印中,8264 就是和目標機 T 保持連接的 sshd 進程號,如需關閉當前連接重新建立一個新的連接,則先在代理機 A 上執行:
kill -9 8264
然後再執行 2.1 節的指令,就會建立一次新的代理連接。
為了安全,我們可以專門新建一個用戶,僅用於 ssh 端口轉發功能,不能在 shell 中使用此用戶登錄。如下創建一個 ssha_debug 的用戶,無 shell 登錄權限。然後為此用戶創建密碼。注意系統中 nologin 文件的位置,不同系統可能路徑不同。
sudo useradd ssha_debug -M -s /usr/sbin/nologin
sudo passwd ssha_debug
2.3 本地機 L (sshc)
2.3.1 本地機 L 登錄目標機 T
有三種方式:
1. 在本地機 L 上通過 ssh 登錄代理機 A,在 A 的 shell 中再登錄目標機 T
代理服務器的公網 ip 是 120.198.45.126,內網 ip 是 192.168.1.102。
1) 先使用 ssh(SecureCRT 或 OpenSSH 命令行) 登錄上代理服務器的 shell。如果調試機在內網,既可登錄代理機的外網 ip,也可登錄其內網 ip。
2) 在代理機的 shell 中執行如下命令登錄遠程設備:
ssh -p 10022 root@127.0.0.1 -vvv
注意,此命令中用戶 root 及其密碼是遠程設備上的賬戶。
如果提示 Host key 認證失敗之類的信息,請按提示執行如下命令:
ssh-keygen -f "/home/frank/.ssh/known_hosts" -R [127.0.0.1]:10022
也可直接刪除當前用戶目錄下的 .ssh/known_hosts 文件。
然後重新執行登錄設備操作。
建議優先使用此方法。
2. 在本地機 L 上使用 ssh 命令登錄目標機 T
Win 10 系統默認安裝有 OpenSSH 客戶端。可以在調試機 Windows 命令行中執行:
ssh -p 10022 root@120.198.45.126 -vvv
對於本地計算機來說,待調試的設備 ip 地址不可見。本機登錄到代理機 120.198.45.126 的轉發端口 10022,通過代理機轉發功能,本地機能成功登錄到遠程設備上。注意,此命令中用戶 root 及其密碼是設備上的賬戶,不是 SSH 代理服務器上的賬戶。
如果出現認證失敗之類的信息。可刪除 C:/Users/當前用戶/.ssh/known_hosts 文件,然後再試。
3. 在本地機 L 上使用 SecureCRT 工具登錄目標機 T
也可以直接使用 SecureCRT 軟件,設置好代理機的 ip(120.198.45.126) 和端口號(10022),填上設備的登錄用戶和登錄密碼。
不建議使用此方法。因為連接過程太長或連接失敗的話,無法看到錯誤提示信息。
2.3.2 查看代理機 A 打印信息
在 L 執行登錄 T 之前查看打印信息:
frank@SERVER:~$ sudo netstat -anp | grep 10022
tcp 0 0 0.0.0.0:10022 0.0.0.0:* LISTEN 106438/sshd: frank
tcp6 0 0 :::10022 :::* LISTEN 106438/sshd: frank
在 L 執行登錄 T 之後查看打印信息:
frank@SERVER:~$ sudo netstat -anp | grep 10022
tcp 0 0 0.0.0.0:10022 0.0.0.0:* LISTEN 106438/sshd: frank
tcp 0 0 192.168.1.102:10022 120.229.163.51:27027 ESTABLISHED 106438/sshd: frank
tcp6 0 0 :::10022 :::* LISTEN 106438/sshd: frank
可以看到,上述第二行是 L 執行登錄命令后新出現的打印信息。表示新建立了一條 L 到 A 的 ssh 連接。
L 端的外網地址 120.229.163.51:27027 連接到 A 上的 192.168.1.102:10022,L 通常位於局域網內、具有一個內網地址,120.229.163.51 可能是 L 連接的路由器的公網 IP。
這條連接建立后,A 將這條連接轉發到 R。
2.3.3 查看目標機 T 打印信息
在 L 執行登錄 T 之前查看打印信息:
root@localhost:~# netstat -anp | grep 22
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 917/sshd
tcp 0 0 192.168.202.140:47989 120.198.45.126:22 ESTABLISHED 9452/ssh
tcp 0 0 192.168.202.140:22 192.168.202.100:64737 ESTABLISHED 2041/sshd
tcp 0 0 :::22 :::* LISTEN 917/sshd
在 L 執行登錄 T 之後查看打印信息:
root@localhost:~# netstat -anp | grep 22
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 917/sshd
tcp 0 0 192.168.202.140:47989 120.198.45.126:22 ESTABLISHED 9452/ssh
tcp 0 0 192.168.202.140:51732 192.168.202.140:22 ESTABLISHED 9452/ssh
tcp 0 0 192.168.202.140:22 192.168.202.140:51732 ESTABLISHED 9579/sshd
tcp 0 0 :::22 :::* LISTEN 917/sshd
可以看到,上述第 3 行和第 4 行是登錄之後新增加的打印信息。
第 2 行,表示 T 上的 ssh 客戶端連接到了 A 上的 ssh 服務端,進程號是 9452。第 3 行,表示進程 9452 收到了 A 轉發來的 ssh 連接后,在本機內部建立新的 ssh 連接,使用 51732 端口號作為 ssh 客戶端,連接到本機 22 端口,22 端口是 sshd 端口。第 4 行,表示本機新啟動一個 sshd 進程,來接收 sshc 的連接。
這樣,L 到 T 的 ssh 通路徹底打通了。A 將來自 L 的連接轉發到 R,R 在內部啟動了 sshd 來處理來自 L 的請求,通過 A 的代理作用,實現了 L 上的 sshc 和 T 上的 sshd 的交互。
3. 典型使用場景步驟總結
上文已涵蓋詳細使用方法,但篇幅太長。此處簡單總結使用步驟如下:
3.1 在代理機 A 上執行
使用 SecureCRT 登錄代理機 A。代理機外網 ip 120.198.45.126,內網 ip 192.168.1.102,端口 22。如果本地機與代理機在同一個局域網裡,使用代理機的內網 ip 登錄即可。
在代理機 shell 中查看是否有未關閉的 ssh 隧道:
sudo netstat -anp | grep 10022
若打印形如:
tcp 0 0 0.0.0.0:10022 0.0.0.0:* LISTEN 8264/sshd: frank
tcp6 0 0 :::10022 :::* LISTEN 8264/sshd: frank
則表示有未關閉的 ssh 隧道連接。執行如下命令可關閉連接。
kill -9 8264
3.2 在目標機 T 上執行
使用遠程應用程序接口或者在遠程設備 T 上做一些特殊操作,觸發 T 執行如下兩條指令之一:
# openssh
sshpass -p '123456' ssh -y -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
# dropbear
DROPBEAR_PASSWORD='123456' ssh -y -T -f -N -g -R :10022:127.0.0.1:22 frank@120.198.45.126
3.3 在本地機 L 上執行
在本地機 L 上執行如下指令,登錄遠程目標機 T:
ssh -vvv -p 10022 root@120.198.45.126
另外一種變通的方式是,在本地機先通過 ssh 登錄上代理機 A 的 shell。然後在 A 的 shell 中執行如下指令:
ssh -vvv -p 10022 root@127.0.0.1
4. 注意事項
1. 確保代理機 A 所在的網絡防火牆不屏蔽 10022 端口
2. 確保代理機 A 上 /etc/ssh/sshd_config 配置文件設置正確
3. 關閉 ssh 隧道既可在代理機 A 上進行(關閉相應的 sshd 進程),也可在目標機 T 上進行(關閉相應的 ssh 進程)
4. 每次只能訪問一台目標機。如果想同時訪問多台,可以代理機上設置多個轉發端口,每條連接使用一個端口進行轉發
5. 為保證安全,打開 ssh 隧道時盡量使用無登錄權限的用戶,並且此用戶的密碼建議經常更新
5. 參考資料
[1] 阮一峰,
[2]
[3]
6. 修改記錄
2019-11-20 V1.0 初稿
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※台灣海運大陸貨務運送流程
※兩岸物流進出口一站式服務