1.最小生成樹介紹
什麼是最小生成樹?
最小生成樹(Minimum spanning tree,MST)是在一個給定的無向圖G(V,E)中求一棵樹T,使得這棵樹擁有圖G中的所有頂點,且所有邊都是來自圖G中的邊,並且滿足整棵樹的邊權值和最小。
2.prim算法
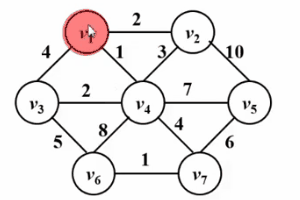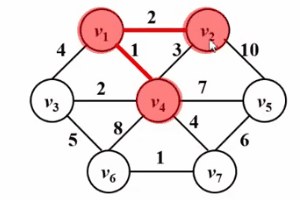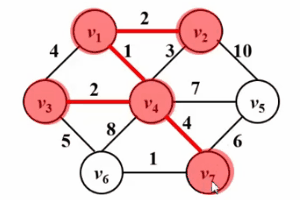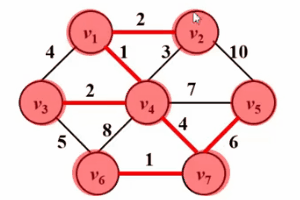
和Dijkstra算法很像!!請看如下Gif圖,prim算法的核心思想是對圖G(V,E)設置集合S,存放已被訪問的頂點,然後每次從集合V-S中選擇與集合S的最短距離最小的一個頂點(記為u),訪問並加入集合S。之後,令頂點u為中間點,優化所有從u能到達的頂點v與集合s之間的最短距離。這樣的操作執行n次,直到集合s中包含所有頂點。
不同的是,Dijkstra算法中的dist是從源點s到頂點w的最短路徑;而prim算法中的dist是從集合S到頂點w的最短路徑,以下是他們的偽碼描述對比,關於Dijkstra算法的詳細描述請
算法實現:
#include<iostream>
#include<vector>
#define INF 100000
#define MaxVertex 105
typedef int Vertex;
int G[MaxVertex][MaxVertex];
int parent[MaxVertex]; // 並查集
int dist[MaxVertex]; // 距離
int Nv; // 結點
int Ne; // 邊
int sum; // 權重和
using namespace std;
vector<Vertex> MST; // 最小生成樹
// 初始化圖信息
void build(){
Vertex v1,v2;
int w;
cin>>Nv>>Ne;
for(int i=1;i<=Nv;i++){
for(int j=1;j<=Nv;j++)
G[i][j] = 0; // 初始化圖
dist[i] = INF; // 初始化距離
parent[i] = -1; // 初始化並查集
}
// 初始化點
for(int i=0;i<Ne;i++){
cin>>v1>>v2>>w;
G[v1][v2] = w;
G[v2][v1] = w;
}
}
// Prim算法前的初始化
void IniPrim(Vertex s){
dist[s] = 0;
MST.push_back(s);
for(Vertex i =1;i<=Nv;i++)
if(G[s][i]){
dist[i] = G[s][i];
parent[i] = s;
}
}
// 查找未收錄中dist最小的點
Vertex FindMin(){
int min = INF;
Vertex xb = -1;
for(Vertex i=1;i<=Nv;i++)
if(dist[i] && dist[i] < min){
min = dist[i];
xb = i;
}
return xb;
}
void output(){
cout<<"被收錄順序:"<<endl;
for(Vertex i=1;i<=Nv;i++)
cout<<MST[i]<<" ";
cout<<"權重和為:"<<sum<<endl;
cout<<"該生成樹為:"<<endl;
for(Vertex i=1;i<=Nv;i++)
cout<<parent[i]<<" ";
}
void Prim(Vertex s){
IniPrim(s);
while(1){
Vertex v = FindMin();
if(v == -1)
break;
sum += dist[v];
dist[v] = 0;
MST.push_back(v);
for(Vertex w=1;w<=Nv;w++)
if(G[v][w] && dist[w])
if(G[v][w] < dist[w]){
dist[w] = G[v][w];
parent[w] = v;
}
}
}
int main(){
build();
Prim(1);
output();
return 0;
} 關於prim算法的更加詳細講解請
3.kruskal算法
Kruskal算法也可以用來解決最小生成樹的問題,其算法思想很容易理解,典型的邊貪心,其算法思想為:
- 在初始狀態時隱去圖中所有的邊,這樣圖中每個頂點都是一個單獨的連通塊,一共有n個連通塊
- 對所有邊按邊權從小到大進行排序
- 按邊權從小到大測試所有邊,如果當前測試邊所連接的兩個頂點不在同一個連通塊中,則把這條測試邊加入當前最小生成樹中,否則,將邊捨棄。
- 重複執行上一步驟,直到最小生成樹中的邊數等於總頂點數減一 或者測試完所有邊時結束;如果結束時,最小生成樹的邊數小於總頂點數減一,說明該圖不連通。
請看下面的Gif圖!
算法實現:
#include<iostream>
#include<string>
#include<vector>
#include<queue>
#define INF 100000
#define MaxVertex 105
typedef int Vertex;
int G[MaxVertex][MaxVertex];
int parent[MaxVertex]; // 並查集最小生成樹
int Nv; // 結點
int Ne; // 邊
int sum; // 權重和
using namespace std;
struct Node{
Vertex v1;
Vertex v2;
int weight; // 權重
// 重載運算符成最大堆
bool operator < (const Node &a) const
{
return weight>a.weight;
}
};
vector<Node> MST; // 最小生成樹
priority_queue<Node> q; // 最小堆
// 初始化圖信息
void build(){
Vertex v1,v2;
int w;
cin>>Nv>>Ne;
for(int i=1;i<=Nv;i++){
for(int j=1;j<=Nv;j++)
G[i][j] = 0; // 初始化圖
parent[i] = -1;
}
// 初始化點
for(int i=0;i<Ne;i++){
cin>>v1>>v2>>w;
struct Node tmpE;
tmpE.v1 = v1;
tmpE.v2 = v2;
tmpE.weight = w;
q.push(tmpE);
}
}
// 路徑壓縮查找
int Find(int x){
if(parent[x] < 0)
return x;
else
return parent[x] = Find(parent[x]);
}
// 按秩歸併
void Union(int x1,int x2){
if(parent[x1] < parent[x2]){
parent[x1] += parent[x2];
parent[x2] = x1;
}else{
parent[x2] += parent[x1];
parent[x1] = x2;
}
}
void Kruskal(){
// 最小生成樹的邊不到 Nv-1 條且還有邊
while(MST.size()!= Nv-1 && !q.empty()){
Node E = q.top(); // 從最小堆取出一條權重最小的邊
q.pop(); // 出隊這條邊
if(Find(E.v1) != Find(E.v2)){ // 檢測兩條邊是否在同一集合
sum += E.weight;
Union(E.v1,E.v2); // 並起來
MST.push_back(E);
}
}
}
void output(){
cout<<"被收錄順序:"<<endl;
for(Vertex i=0;i<Nv;i++)
cout<<MST[i].weight<<" ";
cout<<"權重和為:"<<sum<<endl;
for(Vertex i=1;i<=Nv;i++)
cout<<parent[i]<<" ";
cout<<endl;
}
int main(){
build();
Kruskal();
output();
return 0;
} 關於kruskal算法更詳細的講解
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選