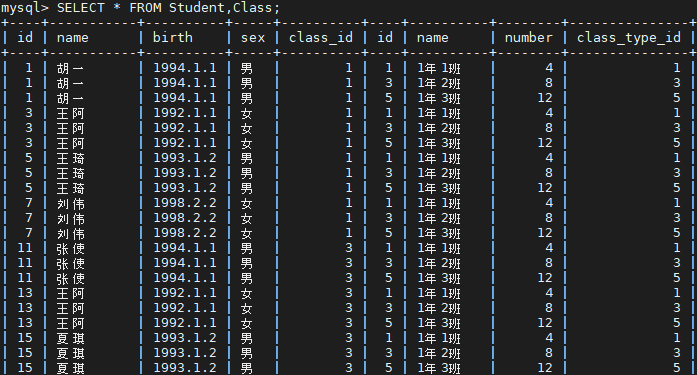
環境資訊中心外電;姜唯 翻譯;林大利 審校;稿源:Carbon Brief
根據發表在《自然通訊(Nature Communication)》的,當大氣中溫室氣體濃度升高,非洲伊波拉疫情爆發的威脅也將隨之增加。
隨著氣溫上升,蝙蝠和其他會將病毒傳播給人類的動物可能遷移到新的區域,進而帶來疾病。
新的模型顯示,如果人口繼續快速增加但發展緩慢且沒有相應的氣候行動,那麼到2070年,伊波拉疫情平均每10年就會爆發一次,今日的平均值是每17年一次。目前還不是疫區的西非和中非也可能受影響。
該研究的結論是,在當前的經濟增長速度和高碳排放水準下,高風險區域的總面積可能擴大五分之一。在更高的碳排放水準下,甚至可能擴大1/3。
作者們說,他們於2018年建立統計模型,成功預測了剛果民主共和國當前的疫情,目前伊波拉在當地已經奪走了兩千多條生命。
因此,他們認為,這份研究當為非洲(包括過去認為未受影響的地區)針對性的伊波拉疫苗計畫和醫療基礎設施的部署奠定基礎。
 獅子山共和國境內努力對抗伊波拉病毒蔓延的村民。 (CC BY-NC-ND 2.0)
獅子山共和國境內努力對抗伊波拉病毒蔓延的村民。 (CC BY-NC-ND 2.0)
伊波拉病毒於1976年首次被發現,2014年爆發疫情,造成西非成千上萬人喪生,在世界各地成為頭條新聞。
一般認為這種傳染病是透過所謂的「溢出物感染」從蝙蝠和其他動物宿主傳播給人類的,是一種人畜共通傳染病。所有人類會感染的傳染病中,有2/3是人畜共通傳染病。
伊波拉病毒一旦感染人類,就可經由直接接觸在人與人之間傳播。人類的症狀包括發燒、嘔吐,有時還包括內部和外部出血。平均死亡率約為50%。
由於伊波拉疫情可能造成重大傷亡,科學家們必須了解下一次伊波拉疫情可能在何時何地爆發,以便分配醫療資源。
但是,由於伊波拉自發現以來,確認的疫情暴發僅有23次,很難用傳統預測常見傳染病(如流感)的方法預測。
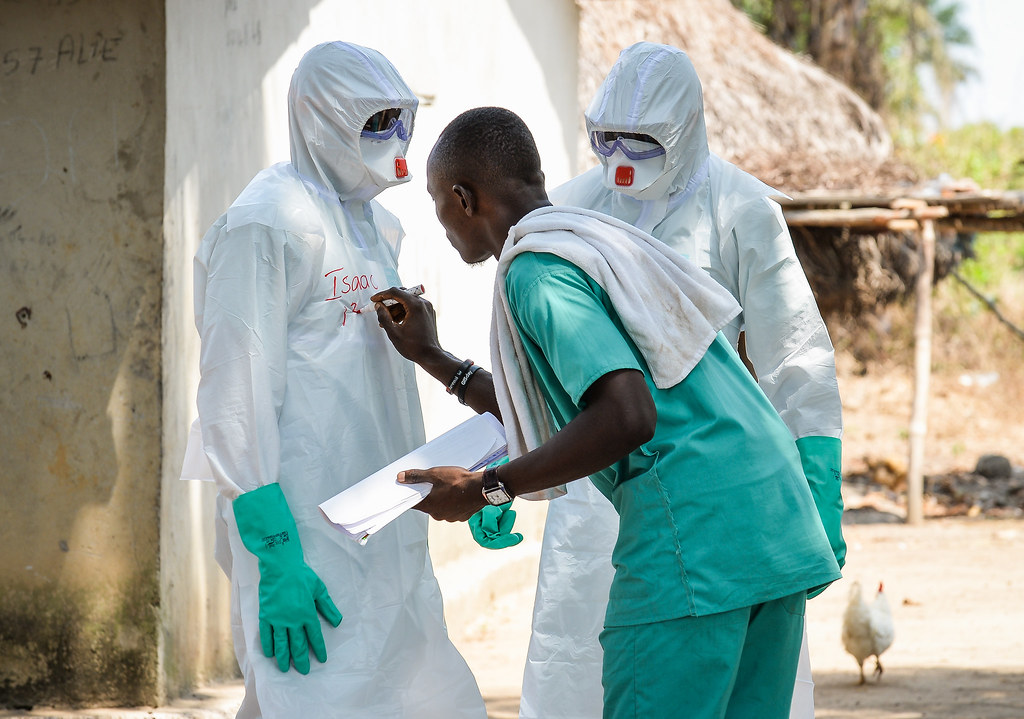 伊波拉防疫措施。來源: 。(CC BY 2.0)
伊波拉防疫措施。來源: 。(CC BY 2.0)
倫敦大學學院的雷丁(David Redding)博士、瓊斯(Kate Jones)博士及其團隊沒有用以前的爆發資料進行研究,而是「由下而上」建立伊波拉爆發的風險模型。
他們使用的資料包含許多因子,包括寄主分布、人口數、陸上交通、空中交通、以及土地利用類型。
該分析的一個關鍵要素是氣候變遷,它既能影響當地社會經濟發展,也可以影響疾病傳播,而且正如雷丁所說,「在我們的模型中,大部分氣候的影響來自於為攜帶疾病的物種提供更好的條件,從而擴大了其地理分布範圍。」
儘管究竟哪些動物能將伊波拉病毒傳給人類仍存在一些不確定性,最主要的嫌犯是大型狐蝠,而這種狐蝠常常被人類獵來吃。這些動物喜歡溫暖和潮濕的棲息地,隨著氣候變遷,高風險地區的棲息地還可能擴張。
分析中還納入了其他可能是傳染途徑的動物,如猿類和麂羚。
研究人員指出,從他們觀察到的結果看來,氣候的作用不如貧窮(後者與醫療保健的反應密切相關)和人口數。
但他們也發現,溢出物感染隨著溫室氣體濃度的增加而增加。雷丁說,「在我們的模型中,負面影響隨著排放增加越來越明顯。」
研究人員開發出一個可模擬西非流行的薩伊伊波拉病毒(Zaire Ebola virus, EBOV)人傳人和動物傳人的模型。
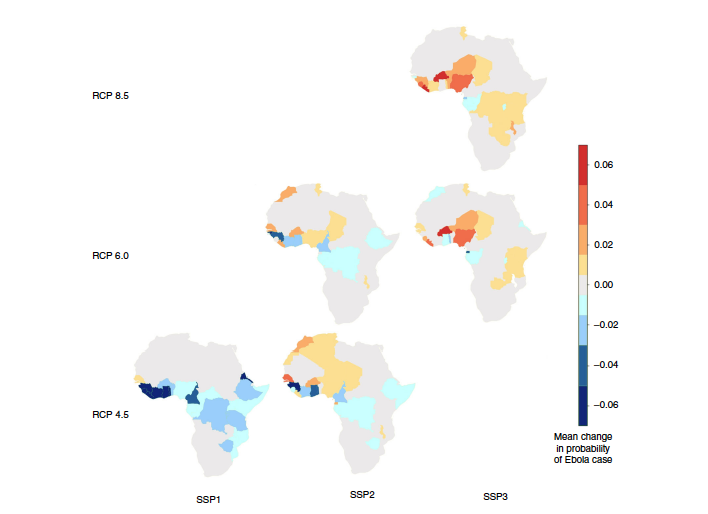 科學家用圖示說明在不同排放情境下的伊波拉病毒擴散風險。來源:
科學家用圖示說明在不同排放情境下的伊波拉病毒擴散風險。來源:
為了評估複雜的社會、經濟和氣候因素對非洲未來伊波拉病毒傳播的影響,研究團隊將氣候變遷情境中的代表濃度途徑(representative concentration pathways, RCPs)和共享社會經濟途徑(shared socio-economic pathways, SSPs)納入其模型。
RCPs代表不同程度的氣候行動導致溫室氣體濃度不斷升高的情境。SSP代表各種社會經濟發展情境,涉及全球社會、人口統計和經濟學的不同狀況。
接著,研究人員使用這些模型來預測到2070年非洲不同地區的伊波拉疫情風險變化。在大多數情境中,模擬結果顯示伊波拉發病率隨時間持續增加。
但是,在永續發展和氣候變遷大規模緩解的情境,伊波拉疫情風險普遍下降。
在現況條件下,模型預測,由溢出物感染引發的流行病大約每17年發生一次。流行病爆發在此定義為規模在1,500名患者以上的感染狀況。
團隊使用現況條件進行了約1,500次年度模擬,發現其中約有5.8%發生了疫情爆發。接著使用不同的條件組合重複此過程。
最大的增長發生在高排放、高人口增長和經濟發展緩慢的情況下(RCP6.0和SSP3),疫情幾乎每10年爆發一次。(論文的原始摘要寫道,在此情況下,疫情爆發的可能性比今日高出四倍,但是正確應是1.6倍。Carbon Brief與作者聯繫後確認了這一點。)
在最樂觀的情境下(假定排放量適中且發展迅速,即RCP4.5和SSP1),頻率下降到大約每30年一次。
模型也顯示,影響超過200萬人的「災難性疫情爆發」模式也很類似。目前這種事件預估每43年發生一次,但根據模擬,在高排放情境下,它們的發生頻率也將增加。
模型還預測有爆發風險的區域會擴大。例如,在最樂觀的社會經濟和氣候情況下,有爆發風險的總面積與今天相比減少了近一半(分別是40萬平方公里和80萬平方公里)。
相比之下,在低度氣候變遷緩解和中度發展(RCP6.0和SSP2)情境下,該面積增加了20.5%;在更極端的情況(RCP8.5和SSP3)下,該面積進一步增加了34%。
值得注意的是,許多傳染病是透過環境傳播(例如水或土壤傳播),但伊波拉病毒是透過宿主之間的直接接觸傳播。這表示儘管蝙蝠和人類直接受到氣候變遷的影響,但病毒本身卻不太容易受氣候變遷影響。
該論文的結論是,因應氣候變遷的全球性承諾也許有助降低伊波拉病例。但是對於這種推測不應太樂觀,因為「證據顯示不太可能發生全面性的改變」。
「在中部和西部非洲減少貧困以及增加醫療資源,似乎是降低全球未來伊波拉疫情風險最現實的方法。」
除了準確地找出已知有伊波拉疫情的地區外,該模型還確定了尼日、迦納和肯亞等國家都很可能受小規模溢出物感染和伊波拉疫情影響,儘管這些國家從來沒傳出伊波拉疫情過。
Ebola epidemics will ‘increase with greenhouse gas concentrations’, study finds by Josh Gabbatiss
The threat of Ebola outbreaks across Africa will increase as levels of greenhouse gases in the atmosphere rise, according to new research.
With warming temperatures, bats and other animals that are thought to transmit the virus to humans are expected to move into new areas, bringing the disease with them.
The new modelling suggests that by 2070 epidemics could break out, on average, once every 10 years, if rapid population growth and slow development are accompanied by inaction on climate change. Under today’s conditions, the average is once every 17 years.
According to the analysis, published in , changing conditions may also affect regions of West and Central Africa that are not currently considered at risk.
The paper concludes that with current rates of economic growth and high emissions, the total epidemic-prone area could expand by a fifth. At even higher levels of emissions, it could expand by a third.
The scientists behind the work say their modelling, which was undertaken in 2018, has already successfully predicted the currently underway in the Democratic Republic of Congo that has claimed more than 2,000 lives.
With this in mind, they say the analysis should lay the groundwork for targeted Ebola vaccine programmes and healthcare infrastructure in Africa, including regions previously thought to be unaffected.
Modelling everything
First identified in 1976, Ebola around the world in 2014 when of epidemic proportions killed thousands of people in West Africa.
The viral disease is thought to pass to humans from bats and other animal hosts in so-called “spillover events”. It is one of the many “zoonotic”, or animal-borne, diseases that make up of all human infectious diseases.
Once spread to humans, Ebola can be transmitted from person to person through direct contact. in humans include fever, vomiting and sometimes both internal and external bleeding. The average fatality rate is around 50%.
Given its potential to inflict significant harm, it is vital that scientists understand when and where the next outbreak of Ebola is likely to strike so that medical resources can be directed accordingly.
However, as there have only been around 23 confirmed outbreaks since the disease was discovered, traditional methods used to predict common infections, such as flu, are difficult.
Instead of working from previous outbreak data, of , along with his colleague and their team, developed an outbreak risk model “from the bottom-up”.
They used data on a range of factors including host distribution, human population size, people’s movements by roads and air, and land use.
, who leads the group at the and was not involved in the study, tells Carbon Brief that combining all these factors into a model is “extremely complex”. “Therefore, I am impressed by this work,” he says.
One vital component of the analysis was climate change, which can influence disease spread both by affecting both local socioeconomic development and, as Redding tells Carbon Brief, the host species themselves:
“In our model most of the climate effects are through better conditions for the disease-carrying species, thus increasing their native geographical range.”
While there is still about precisely which animals pass Ebola on to humans, the prime suspects are large fruit bats that are often hunted . These creatures are known to prefer warm and wet habitats, which are expected to expand in the target regions as the climate changes.
Other animals thought to provide alternative routes for infection, such as apes and duiker antelopes, were also considered in the analysis.
The researchers note that climate played a less important role in their observed outcomes than poverty – which is closely tied with healthcare response – and human population size.
However, they also note that spillover events “increased with greenhouse gas concentrations”. Redding explains:
“There is a positive association in our model results with increasingly more negative impact with higher emission scenarios.”
Epidemic expansion
The researchers developed a model that simulated animal-to-human and human-to-human transmission of Zaire Ebola virus (EBOV), the strain responsible for the West African epidemic.
In order to gauge the impact of complex social, economic and climate factors on future Ebola transmission in Africa, the team then incorporated representative concentration pathways () and shared socio-economic pathways () into their modelling.
RCPs broadly represent scenarios with ever-higher levels of greenhouse gases resulting from different levels of climate action. SSPs are for various socioeconomic development scenarios, involving different outcomes for global society, demographics and economics.
(For more, see Carbon Brief’s recent on RCP8.5 and Carbon Brief’s SSP .)
The researchers then used these models to project changes in Ebola risk across different African regions by the year 2070.
Writing in their paper, they say their simulations suggest a “general, ongoing increase in Ebola incidence over time” for most scenarios.
However, for scenarios involving sustainable development and extensive climate mitigation, there was a general decrease in Ebola risk (the chart below gives an idea of changing risk in different scenario combinations).
Change in future risks of Ebola virus disease under different RCP and SSP scenarios. Each map represents mean change in “per grid cell probability” of an Ebola case from zero (yellow) to −0.06 (dark blue) and 0.06 (red), aggregated at a country level with data from the group’s model for 2070. Source: Redding et al. (2019)
Under current conditions, the models predict an epidemic resulting from a spillover event will occur roughly once every 17 years. An epidemic was defined as an outbreak involving more than 1,500 patients.
To arrive at this conclusion, the team ran around 1,500 yearly simulations using present day conditions and found that epidemics occurred in approximately 5.8% of them. This process was then repeated using different sets of conditions.
The greatest increase occurs in a scenario with high emissions, high population growth and slow economic development (RCP6.0 and SSP3), with epidemics expected to occur nearly once every 10 years.
(The likelihood of epidemics occurring under these conditions compared to present day was incorrectly described as four times more likely, instead of 1.6 times more likely, in the paper’s original abstract. The authors confirmed this after Carbon Brief contacted them about the discrepancy.)
Under the most optimistic of the scenarios they used – which assumes moderate emissions and high development (RCP4.5 and SSP1) – the occurrence drops to roughly once every 30 years.
A similar pattern is expected to play out for “catastrophic epidemics” affecting more than two million people. These events are currently predicted to take place once every 43 years, but the modelling suggests they will increase in frequency under high-emissions scenarios.
The models also predict an expansion in the area at risk from outbreaks. For example, under the most optimistic socioeconomic and climate scenario, the total area where epidemics could start decreased by nearly half compared to present day (0.4m square kilometres, km2, compared to 0.8m km2).
In comparison, in a scenario involving low climate mitigation and “middle of the road” development (RCP6.0 and SSP2), this area increased by 20.5%, Under a more extreme scenario (RCP8.5 and SSP3) this increased further, by 34%.
Disease and climate
While the links between climate and Ebola, Redding and his co-authors think this is the first attempt to model future transmission of the disease that takes climate change into account.
Baylis says there has been extensive work exploring direct links between changing climate and the spread of disease – for example, in the Kenyan highlands and malaria risk.
However, while work from his own group has suggested of infectious diseases are susceptible to climate, he says identifying these links can be challenging:
“Attribution is difficult, because we are really saying that climate change increases the probability of an event, but extreme events are expected even without climate change.”
It is worth noting that while many infectious diseases are transmitted via the environment (by way of water or soil, for example), Ebola moves via direct contact between hosts. This means while bats and humans are affected directly by the changing climate, the virus itself is less susceptible to a changing climate.
The paper concludes that global commitments to tackle climate change may drive down Ebola cases. However, it is not optimistic about this outcome, noting “evidence suggests a wholesale change is unlikely”:
“Efforts to decrease poverty in Central and Western Africa with a concomitant increase in healthcare resources, therefore, would appear to be the most realistic approach to reducing future Ebola virus disease risk globally.”
Future response
Besides accurately identifying the known endemic area for Ebola, the modelling also identifies countries such as Nigeria, Ghana and Kenya as vulnerable to both small spillovers and epidemics of Ebola, despite never having been the source of such outbreaks before.
The team says their approach “somewhat contradict[s] analyses based on current case data”.
According to Baylis, the team’s validation of past outbreaks using the new approach increases confidence in future predictions, but notes the models are still “likely constrained by the quality of our knowledge of Ebola hosts, which is not high”.
Besides identifying a “much larger” area within Africa that is vulnerable to spillover events, the team also incorporated information about airline routes and concluded that China, Russia, India, the US and many European countries were at risk of importing the disease.
According to Redding, their work “acts as a call” for both a better understanding of where Ebola outbreaks could hit, plus the need for cooperation between wealthier and poorer countries to improve healthcare resources in preparation. He concludes:
“Such an approach is a no-lose situation as better containment facilities and barrier nursing, for example, could protect nations and their neighbours against many different future disease outbreaks, not just Ebola.”
※ 全文及圖片詳見:()
※ 論文資料:Redding, D. et al. (2019) Impacts of environmental and socio-economic factors on emergence and epidemic potential of Ebola in Africa, Nature Communications,
作者
如果有一件事是重要的,如果能為孩子實現一個願望,那就是人類與大自然和諧共存。
於特有生物研究保育中心服務,小鳥和棲地是主要的研究對象。是龜毛的讀者,認為龜毛是探索世界的美德。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化