君子知夫不全不粹之不足以為美也,
故誦數以貫之,
思索以通之,
為其人以處之,
除其害者以持養之;
出自荀子《勸學篇》
終於OTA的升級過程的詳解來了,之前的兩篇文章與主要是鋪墊,
OTA升級的一些基礎知識,那這邊文章就開始揭開OTA-recovery模式升級過程的神秘面紗,需要說明的是
以下重點梳理了本人認為的關鍵、核心的流程,其他如ui部分、簽名校驗部分我並未花筆墨去描述,主要
還是講升級的核心,其他都是枝枝恭弘=叶 恭弘恭弘=叶 恭弘。Android 10 recovery源碼分析,代碼來源路徑:
https://www.androidos.net.cn/android/10.0.0_r6/xref
本文所講的流程代碼路徑為:bootable/recovery/
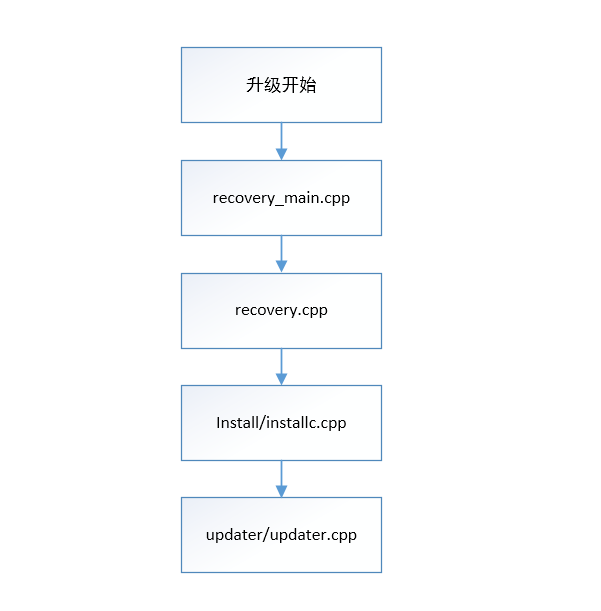
首先從文件層面說下升級功能的調用流程,說明如下:
recovery-main.cpp 升級的主入口
recovery.cpp 開始recovery升級的處理流程
install/install.cpp 執行升級的處理流程(調用updater)
updater/updater.cpp 完成升級的核心流程
1 主入口代碼為:recovery-main.cpp,main入口
1.1 日誌相關的工作準備
1 // We don't have logcat yet under recovery; so we'll print error on screen and log to stdout
2 // (which is redirected to recovery.log) as we used to do.
3 android::base::InitLogging(argv, &UiLogger);
4
5 // Take last pmsg contents and rewrite it to the current pmsg session.
6 static constexpr const char filter[] = "recovery/";
7 // Do we need to rotate?
8 bool do_rotate = false;
9
10 __android_log_pmsg_file_read(LOG_ID_SYSTEM, ANDROID_LOG_INFO, filter, logbasename, &do_rotate);
11 // Take action to refresh pmsg contents
12 __android_log_pmsg_file_read(LOG_ID_SYSTEM, ANDROID_LOG_INFO, filter, logrotate, &do_rotate);
13
14 time_t start = time(nullptr);
15
16 // redirect_stdio should be called only in non-sideload mode. Otherwise we may have two logger
17 // instances with different timestamps.
18 redirect_stdio(Paths::Get().temporary_log_file().c_str());
1.2 load_volume_table(); 加載系統分區信息,注意這裏並明白掛載分區
.mount_point = “/tmp”, .fs_type = “ramdisk”, .blk_device = “ramdisk”, .length = 0
mount_point — 掛載點 fs_type — 分區類型
blk_device — 設備塊名 length — 分區大小
1.3 掛載/cache分區,我們的升級命令都放在這個分區下
1 has_cache = volume_for_mount_point(CACHE_ROOT) != nullptr;
1.4 獲取升級的參數並寫BCB塊信息
std::vector<std::string> args = get_args(argc, argv);
if (!update_bootloader_message(options, &err)) {
LOG(ERROR) << "Failed to set BCB message: " << err;
}
a、讀取misc分區分區,並將recovery模式升級的標記寫到misc分區中,這樣做的目的是斷電續升,
升級中掉電之後,如果下次開機重啟,在bootloader中會讀取此標記,並重新進入到recovery模式中
update_bootloader_message函數完成此功能。
b、從/cache/recovery/command 中讀取升級參數,這裏recovery啟動進程是未帶入參數時,command
文件的接口其實有很詳細的解釋
* The arguments which may be supplied in the recovery.command file:
* --update_package=path - verify install an OTA package file
* --wipe_data - erase user data (and cache), then reboot
* --prompt_and_wipe_data - prompt the user that data is corrupt, with their consent erase user
* data (and cache), then reboot
* --wipe_cache - wipe cache (but not user data), then reboot
* --show_text - show the recovery text menu, used by some bootloader (e.g. http://b/36872519).
* --set_encrypted_filesystem=on|off - enables / diasables encrypted fs
* --just_exit - do nothing; exit and reboot
1.5 加載recovery_ui_ext.so,完成升級中與屏幕信息的显示,升級進度,升級結果等。這裏就不多說了。
static constexpr const char* kDefaultLibRecoveryUIExt = "librecovery_ui_ext.so";
// Intentionally not calling dlclose(3) to avoid potential gotchas (e.g. `make_device` may have
// handed out pointers to code or static [or thread-local] data and doesn't collect them all back
// in on dlclose).
void* librecovery_ui_ext = dlopen(kDefaultLibRecoveryUIExt, RTLD_NOW);
using MakeDeviceType = decltype(&make_device);
MakeDeviceType make_device_func = nullptr;
if (librecovery_ui_ext == nullptr) {
printf("Failed to dlopen %s: %s\n", kDefaultLibRecoveryUIExt, dlerror());
} else {
reinterpret_cast<void*&>(make_device_func) = dlsym(librecovery_ui_ext, "make_device");
if (make_device_func == nullptr) {
printf("Failed to dlsym make_device: %s\n", dlerror());
}
}
1.6 非fastboot模式升級就開始了recovery模式升級,start_recovery
ret = fastboot ? StartFastboot(device, args) : start_recovery(device, args);
2 進入 recovery.cpp
2.1 參數解析,這些參數其實就是來源於/cache/recovery/command, 上面已經通過get_arg,
讀取到了args中
2.2 界面的各種ui信息显示,點事電量的檢查等待輔助動作。
2.3 函數名為安裝升級包,其實還未真正開始進行升級包的安裝
1 status = install_package(update_package, should_wipe_cache, true, retry_count, ui);
2.4 安裝結束之後由finish_recovery()完成收尾工作,保存日誌、清除BCB中的標記,設備重啟。
1 static void finish_recovery() {
2 std::string locale = ui->GetLocale();
3 // Save the locale to cache, so if recovery is next started up without a '--locale' argument
4 // (e.g., directly from the bootloader) it will use the last-known locale.
5 if (!locale.empty() && has_cache) {
6 LOG(INFO) << "Saving locale \"" << locale << "\"";
7 if (ensure_path_mounted(LOCALE_FILE) != 0) {
8 LOG(ERROR) << "Failed to mount " << LOCALE_FILE;
9 } else if (!android::base::WriteStringToFile(locale, LOCALE_FILE)) {
10 PLOG(ERROR) << "Failed to save locale to " << LOCALE_FILE;
11 }
12 }
13
14 copy_logs(save_current_log, has_cache, sehandle);
15
16 // Reset to normal system boot so recovery won't cycle indefinitely.
17 std::string err;
18 if (!clear_bootloader_message(&err)) {
19 LOG(ERROR) << "Failed to clear BCB message: " << err;
20 }
21
22 // Remove the command file, so recovery won't repeat indefinitely.
23 if (has_cache) {
24 if (ensure_path_mounted(COMMAND_FILE) != 0 || (unlink(COMMAND_FILE) && errno != ENOENT)) {
25 LOG(WARNING) << "Can't unlink " << COMMAND_FILE;
26 }
27 ensure_path_unmounted(CACHE_ROOT);
28 }
29
30 sync(); // For good measure.
31 }
3 install/install.cpp
3.1 install.cpp其實就進入了安裝升級包的準備動作,剛上的install_package,是假的,這裏才是
really_install_package
1 really_install_package(path, &updater_wipe_cache, needs_mount, &log_buffer,
2 retry_count, &max_temperature, ui);
3.2 really_install_package 關鍵地方已加註釋
1 static int really_install_package(const std::string& path, bool* wipe_cache, bool needs_mount,
2 std::vector<std::string>* log_buffer, int retry_count,
3 int* max_temperature, RecoveryUI* ui) {
4 ui->SetBackground(RecoveryUI::INSTALLING_UPDATE);
5 ui->Print("Finding update package...\n");
6 // Give verification half the progress bar...
7 ui->SetProgressType(RecoveryUI::DETERMINATE);
8 ui->ShowProgress(VERIFICATION_PROGRESS_FRACTION, VERIFICATION_PROGRESS_TIME);
9 LOG(INFO) << "Update location: " << path;
10
11 // Map the update package into memory.
12 ui->Print("Opening update package...\n");
13
14 if (needs_mount) {
15 if (path[0] == '@') {
16 ensure_path_mounted(path.substr(1));
17 } else {
18 ensure_path_mounted(path);
19 }
20 }
21
22 /* 將zip映射到內存中 */
23 auto package = Package::CreateMemoryPackage(
24 path, std::bind(&RecoveryUI::SetProgress, ui, std::placeholders::_1));
25 if (!package) {
26 log_buffer->push_back(android::base::StringPrintf("error: %d", kMapFileFailure));
27 return INSTALL_CORRUPT;
28 }
29
30 // Verify package.進行zip包進行簽名校驗
31 if (!verify_package(package.get(), ui)) {
32 log_buffer->push_back(android::base::StringPrintf("error: %d", kZipVerificationFailure));
33 return INSTALL_CORRUPT;
34 }
35
36 // Try to open the package.打開zip包
37 ZipArchiveHandle zip = package->GetZipArchiveHandle();
38 if (!zip) {
39 log_buffer->push_back(android::base::StringPrintf("error: %d", kZipOpenFailure));
40 return INSTALL_CORRUPT;
41 }
42
43 // Additionally verify the compatibility of the package if it's a fresh install.
44 if (retry_count == 0 && !verify_package_compatibility(zip)) {
45 log_buffer->push_back(android::base::StringPrintf("error: %d", kPackageCompatibilityFailure));
46 return INSTALL_CORRUPT;
47 }
48
49 // Verify and install the contents of the package.
50 ui->Print("Installing update...\n");
51 if (retry_count > 0) {
52 ui->Print("Retry attempt: %d\n", retry_count);
53 }
54 ui->SetEnableReboot(false);
55 int result =
56 /* 執行升級updater進程進行升級 */
57 try_update_binary(path, zip, wipe_cache, log_buffer, retry_count, max_temperature, ui);
58 ui->SetEnableReboot(true);
59 ui->Print("\n");
60
61 return result;
62 }
3.3 try_update_binary
從升級包中讀取元數據信息
1 ReadMetadataFromPackage(zip, &metadata)
3.4 從升級包中讀取updater進程
1 int SetUpNonAbUpdateCommands(const std::string& package, ZipArchiveHandle zip, int retry_count,
2 int status_fd, std::vector<std::string>* cmd) {
3 CHECK(cmd != nullptr);
4
5 // In non-A/B updates we extract the update binary from the package.
6 static constexpr const char* UPDATE_BINARY_NAME = "META-INF/com/google/android/update-binary";
7 ZipString binary_name(UPDATE_BINARY_NAME);
8 ZipEntry binary_entry;
9 if (FindEntry(zip, binary_name, &binary_entry) != 0) {
10 LOG(ERROR) << "Failed to find update binary " << UPDATE_BINARY_NAME;
11 return INSTALL_CORRUPT;
12 }
13
14 const std::string binary_path = Paths::Get().temporary_update_binary();
15 unlink(binary_path.c_str());
16 android::base::unique_fd fd(
17 open(binary_path.c_str(), O_CREAT | O_WRONLY | O_TRUNC | O_CLOEXEC, 0755));
18 if (fd == -1) {
19 PLOG(ERROR) << "Failed to create " << binary_path;
20 return INSTALL_ERROR;
21 }
22
23 int32_t error = ExtractEntryToFile(zip, &binary_entry, fd);
24 if (error != 0) {
25 LOG(ERROR) << "Failed to extract " << UPDATE_BINARY_NAME << ": " << ErrorCodeString(error);
26 return INSTALL_ERROR;
27 }
28
29 // When executing the update binary contained in the package, the arguments passed are:
30 // - the version number for this interface
31 // - an FD to which the program can write in order to update the progress bar.
32 // - the name of the package zip file.
33 // - an optional argument "retry" if this update is a retry of a failed update attempt.
34 *cmd = {
35 binary_path,
36 std::to_string(kRecoveryApiVersion),
37 std::to_string(status_fd),
38 package,
39 };
40 if (retry_count > 0) {
41 cmd->push_back("retry");
42 }
43 return 0;
44 }
3.5 創建管道,這裏子進程關閉了讀端,父進程關閉了寫端,這樣就是保證從單向的信息通信,從
子進程傳入信息到父進程中。
1 android::base::Pipe(&pipe_read, &pipe_write, 0)
3.6 創建子進程,在子進程中運行update-binary進程
1 if (pid == 0) {
2 umask(022);
3 pipe_read.reset();
4
5 // Convert the std::string vector to a NULL-terminated char* vector suitable for execv.
6 auto chr_args = StringVectorToNullTerminatedArray(args);
7 /* chr_args[0] 其實就是升級包中的 META-INF/com/google/android/update-binary */
8 execv(chr_args[0], chr_args.data());
9 // We shouldn't use LOG/PLOG in the forked process, since they may cause the child process to
10 // hang. This deadlock results from an improperly copied mutex in the ui functions.
11 // (Bug: 34769056)
12 fprintf(stdout, "E:Can't run %s (%s)\n", chr_args[0], strerror(errno));
13 _exit(EXIT_FAILURE);
14 }
3.7 recovery獲取子進程的信息並显示,進度、ui_print 等等。
1 FILE* from_child = android::base::Fdopen(std::move(pipe_read), "r");
2 while (fgets(buffer, sizeof(buffer), from_child) != nullptr)
4 execv執行升級進程之後,工作在updater/updater.cpp中完成。
4.1 這裏的主要核心就是構造腳本解析器對updater-script中的命令進行執行,至於這個腳本解析器
是如何構造的,如何執行的, 其實我也搞的不是很清楚。
4.2 安裝升級包的核心程序就是Configure edify’s functions. 中的那些註冊回調函數
1 int main(int argc, char** argv) {
2 // Various things log information to stdout or stderr more or less
3 // at random (though we've tried to standardize on stdout). The
4 // log file makes more sense if buffering is turned off so things
5 // appear in the right order.
6 setbuf(stdout, nullptr);
7 setbuf(stderr, nullptr);
8 // We don't have logcat yet under recovery. Update logs will always be written to stdout
9 // (which is redirected to recovery.log).
10 android::base::InitLogging(argv, &UpdaterLogger);
11 if (argc != 4 && argc != 5) {
12 LOG(ERROR) << "unexpected number of arguments: " << argc;
13 return 1;
14 }
15 /* 支持的版本檢查 */
16 char* version = argv[1];
17 if ((version[0] != '1' && version[0] != '2' && version[0] != '3') || version[1] != '\0') {
18 // We support version 1, 2, or 3.
19 LOG(ERROR) << "wrong updater binary API; expected 1, 2, or 3; got " << argv[1];
20 return 2;
21 }
22 // Set up the pipe for sending commands back to the parent process.
23 int fd = atoi(argv[2]);
24 FILE* cmd_pipe = fdopen(fd, "wb");
25 setlinebuf(cmd_pipe);
26 // Extract the script from the package.
27 /* 從包中提取腳本 */
28 const char* package_filename = argv[3];
29 MemMapping map;
30 if (!map.MapFile(package_filename)) {
31 LOG(ERROR) << "failed to map package " << argv[3];
32 return 3;
33 }
34 ZipArchiveHandle za;
35 int open_err = OpenArchiveFromMemory(map.addr, map.length, argv[3], &za);
36 if (open_err != 0) {
37 LOG(ERROR) << "failed to open package " << argv[3] << ": " << ErrorCodeString(open_err);
38 CloseArchive(za);
39 return 3;
40 }
41 ZipString script_name(SCRIPT_NAME);
42 ZipEntry script_entry;
43 int find_err = FindEntry(za, script_name, &script_entry);
44 if (find_err != 0) {
45 LOG(ERROR) << "failed to find " << SCRIPT_NAME << " in " << package_filename << ": "
46 << ErrorCodeString(find_err);
47 CloseArchive(za);
48 return 4;
49 }
50 std::string script;
51 script.resize(script_entry.uncompressed_length);
52 int extract_err = ExtractToMemory(za, &script_entry, reinterpret_cast<uint8_t*>(&script[0]),
53 script_entry.uncompressed_length);
54 if (extract_err != 0) {
55 LOG(ERROR) << "failed to read script from package: " << ErrorCodeString(extract_err);
56 CloseArchive(za);
57 return 5;
58 }
59 // Configure edify's functions.
60 /* 註冊updater-script中的回調函數 這裏主要是一些斷言函數 abort assert*/
61 RegisterBuiltins();
62 /* 這裏主要是一些安裝升級包的函數 主要是對有文件系統的分區來說*/
63 RegisterInstallFunctions();
64 /* 這裏主要註冊對裸分區進行升級的函數 */
65 RegisterBlockImageFunctions();
66 RegisterDynamicPartitionsFunctions();
67 RegisterDeviceExtensions();
68 // Parse the script.
69 std::unique_ptr<Expr> root;
70 int error_count = 0;
71 int error = ParseString(script, &root, &error_count);
72 if (error != 0 || error_count > 0) {
73 LOG(ERROR) << error_count << " parse errors";
74 CloseArchive(za);
75 return 6;
76 }
77 sehandle = selinux_android_file_context_handle();
78 selinux_android_set_sehandle(sehandle);
79 if (!sehandle) {
80 fprintf(cmd_pipe, "ui_print Warning: No file_contexts\n");
81 }
82 // Evaluate the parsed script.
83 UpdaterInfo updater_info;
84 updater_info.cmd_pipe = cmd_pipe;
85 updater_info.package_zip = za;
86 updater_info.version = atoi(version);
87 updater_info.package_zip_addr = map.addr;
88 updater_info.package_zip_len = map.length;
89 State state(script, &updater_info);
90 if (argc == 5) {
91 if (strcmp(argv[4], "retry") == 0) {
92 state.is_retry = true;
93 } else {
94 printf("unexpected argument: %s", argv[4]);
95 }
96 }
97 std::string result;
98 bool status = Evaluate(&state, root, &result);
99 if (!status) {
100 if (state.errmsg.empty()) {
101 LOG(ERROR) << "script aborted (no error message)";
102 fprintf(cmd_pipe, "ui_print script aborted (no error message)\n");
103 } else {
104 LOG(ERROR) << "script aborted: " << state.errmsg;
105 const std::vector<std::string> lines = android::base::Split(state.errmsg, "\n");
106 for (const std::string& line : lines) {
107 // Parse the error code in abort message.
108 // Example: "E30: This package is for bullhead devices."
109 if (!line.empty() && line[0] == 'E') {
110 if (sscanf(line.c_str(), "E%d: ", &state.error_code) != 1) {
111 LOG(ERROR) << "Failed to parse error code: [" << line << "]";
112 }
113 }
114 fprintf(cmd_pipe, "ui_print %s\n", line.c_str());
115 }
116 }
117 // Installation has been aborted. Set the error code to kScriptExecutionFailure unless
118 // a more specific code has been set in errmsg.
119 if (state.error_code == kNoError) {
120 state.error_code = kScriptExecutionFailure;
121 }
122 fprintf(cmd_pipe, "log error: %d\n", state.error_code);
123 // Cause code should provide additional information about the abort.
124 if (state.cause_code != kNoCause) {
125 fprintf(cmd_pipe, "log cause: %d\n", state.cause_code);
126 if (state.cause_code == kPatchApplicationFailure) {
127 LOG(INFO) << "Patch application failed, retry update.";
128 fprintf(cmd_pipe, "retry_update\n");
129 } else if (state.cause_code == kEioFailure) {
130 LOG(INFO) << "Update failed due to EIO, retry update.";
131 fprintf(cmd_pipe, "retry_update\n");
132 }
133 }
134 if (updater_info.package_zip) {
135 CloseArchive(updater_info.package_zip);
136 }
137 return 7;
138 } else {
139 fprintf(cmd_pipe, "ui_print script succeeded: result was [%s]\n", result.c_str());
140 }
141 if (updater_info.package_zip) {
142 CloseArchive(updater_info.package_zip);
143 }
144 return 0;
145 }
以上就是基於Android的OTA的Recovery模式升級流程。我這裏主要是梳理整個升級流程的主要,
很多地方還是寫的不夠細,望讀者理解,我認為比較核心與關鍵的地方有以下幾點吧
- 主系統與recovery升級系統,升級消息的傳遞通過cache;
- 主系統中fork子進程進行升級進程的執行,並通過pipe管道進行信息交互;
- updater中使用命令與執行的分離,命令在updater-script中,執行在update-binary中;
- 升級程序通過升級包帶入的,那麼核心升級流程是每次都有機會變更或者優化的,
- 這樣就比那些將升級流程預置在系統中的要靈活的很多;
長按二維碼關注【嵌入式C部落】,獲取更多編程資料及精華文章
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!

![Java性能分析神器–VisualVM Launcher[1]](https://www.3chy2.com.tw/wp-content/uploads/2020/06/453a176c2843190b79353da18dcdcab5.jpg)