自動化任務簡介
假設我們要在10台linux服務器上安裝一個nginx服務,手動是如何做的?
# 第一步, ssh登錄NUM(1,n)服務器
# 第二步,輸入對應服務器密碼
# 第三步,執行命令: yum install nginx 循環操作n=10
# 第四步,執行命令: service nginx start
# 第五步,退出登錄
自動化任務執行的意義
# 意義一, 提升運維工作效率,減少一份工作成本
# 意義二, 提高準確度.
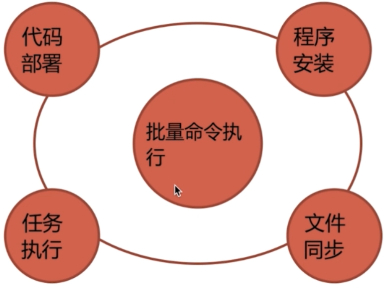
自動化任務執行的應用
# 應用一, 批量命令執行
# 應用二, 定時程序任務執行
# 應用三, 批量程序應用服務安裝
# 應用四, 批量配置文件同步
# 應用五, 批量代碼部署
ansible配置
ansible是python中的一套模塊,系統中的一套自動化工具,可以用作系統管理,自動化命令等任務
ansible優勢
# 1.ansible是python中的一套完整的自動化執行任務模塊
# 2.ansible的play_book模式,不用yaml配置,對於自動化任務執行一目瞭然.
# 3.自動化場景支持豐富
ansible配置文件
1. inventory
# 該參數表示資源清單inventory文件的位置,資源清單就是一些Ansible需要連接管理的主機列表
# inventory = /root/ansible/hosts
2. library
# Ansible的操作動作,無論是本地或遠程,都使用一小段代碼來執行,這小段代碼稱為模塊,這個library參數就是指向存放Ansible模塊的目錄
# library = /usr/share/ansible
3. forks
# 設置默認情況下Ansible最多能有多少個進程同時工作,默認設置最多5個進程并行處理。具體需要設置多少個,可以根據控制主機的性能和被管理節點的數量來確定。
# forks = 5
4. sudo_user
# 這是設置默認執行命令的用戶,也可以在playbook中重新設置這個參數
# sudo_user = root
# 注意: 新版本已經做了修改,如ansible2.4.1下已經為:
# default_sudo_user = root
5. remote_port
# 這是指定連接被關節點的管理端口,默認是22,除非設置了特殊的SSH端口,不然這個參數是不需要被修改的
# remote_port = 22
6. host_key_checking
# 這是設置是否檢查ssh主機的秘鑰,可以設置為True或者False
# host_key_checking = False
7. timeout
# 這是設置ssh連接的超時間隔,單位是秒
# timeout = 20
8. log_path
# ansible系統默認是不記錄日誌的,如果想把ansible系統的輸出記錄到指定地方,需要設置log_path來指定一個存儲Ansible日誌的文件
9. private_key_file
# 在使用ssh公鑰私鑰登錄系統時使用的秘鑰路徑
# private_key_file=/path/to/file.pem
ansible.cfg
[defaults]
inventory = /tmp/hosts
forks = 5
default_sudo_user = root
remote_port = 22
host_key_checking = Falsetimeout = 20
log_path = /var/log/ansible.log
#private_key_file=/tmp/file.pem
ansible安裝
# 1. 通過系統的方式,yum,apt,get等
# 2. 通過python的方式
# (推薦)python ./setup.py install
easy_install ansible
pip install ansible
Ansible基礎操作
當我們將Ansible安裝好以後,可以通過一些命令開始深入了解Ansible了.
我們最先展示的並非那強大的集配置,部署,自動化於一身的playbook.而是如何初始化.
遠程連接概述
在我們開始前要先理解Ansible如何通過SSH與遠程服務器連接是很重要的.
Ansible1.3及之後的版本默認會在本地的OpenSSH可用時會嘗試用其遠程通訊,這會啟用ControlPersist(一個性能特性),Kerberos,和在~/.ssh/config中的配置選項如 Jump Host setup.然而,當你使用Linux企業版6作為主控機(紅帽企業版及其衍生版如CentOS),其OpenSSH版本可能過於老舊無法支持ControIPersist,在這些操作系統中,Ansible將會退回並採用paramiko(由Python實現的高質量OpenSSH庫).如果你希望能夠使用像是Kerberized SSH之類的特性,煩請考慮使用Fedora,OS X,或Ubuntu作為你的主控機直到相關平台上有更新版本的OpenSSH可供使用,或者啟用Ansible的”accelerated mode”.
在Ansible1.2及之前的版本,默認將會使用paramiko,本地OpenSSH必須通過-c ssh或者配置文件中設定.
我們偶爾會遇到不支持SFTP的設備,雖然很少見,但有概率中獎,可以通過ansible配置文件切換至scp模式來與之連接.
說起遠程設備,Ansible會默認假定你使用SSH key(當然也推薦這種)但是密碼一樣可以,通過在需要的地方添加-ask-pass選項來啟用密碼驗證,如果使用了sudo特性,當sudo需要密碼時,也同樣適當的提供了-ask-sudo-pass選項.
也許這是常識,但也值得分享:任何管理系統受益於被管理的機器在主控機附近運行.如果在雲中運行,可以考慮在使用雲中的一台機器來運行Ansible.
作為一個進階話題,Ansible不止支持SSH來遠程連接.連接方式是插件化的而且還有許多本地化管理的選項諸如管理 chroot, lxc, 和 jail containers.一個叫做‘ansible-pull’的模式能夠反轉主控關係並使遠程系統通過定期從中央git目錄檢出 並 拉取 配置指令來實現背景連接通信
第一條命令(公鑰認證)
我們已經安裝ansible了,第一件事就是編輯或者創建/etc/ansible/hosts並在其中加入一個或多個遠程系統,我們的public SSH key必須在這些系統的authorized_keys中.
# 我們現在ansible控制機上主機名解析
tail /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
121.36.43.223 node1
120.77.248.31 node2
116.196.83.113 master
# 將解析過的主機名放到ansible配置文件裏面
tail -2 /etc/ansible/hosts
node1
node2
# ansible控制機生成公鑰並傳給需要被控制的機器上
ssh-copy-id node1
ssh-copy-id node2
# 因為考慮到安全問題,會有主機秘鑰的檢查,但如果在內網非常信任的服務器就沒必要了.
sed -i 's/# *StrictHostKeyChecking *ask/StrictHostKeyChecking no/g' /etc/ssh/ssh_config
# 然後我們就可以執行第一條命令來查看能ping通控制的所有節點.
ansible all -m ping
node1 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
node2 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
Ansible會像SSH那樣試圖用你的當前用戶名來連接你的遠程機器.要覆寫遠程用戶名,只需使用’-u’參數. 如果你想訪問 sudo模式,這裏也有標識(flags)來實現:
ansible all -m ping -u bruce
ansible all -m ping -u bruce --sudo
ansible all -m ping -u bruce --sudo --sudo-user batman
(如果你碰巧想要使用其他sudo的實現方式,你可以通過修改Ansible的配置文件來實現.也可以通過傳遞標識給sudo(如-H)來設置.) 現在對你的所有節點運行一個命令:
ansible all -a "/bin/echo hello"
node1 | CHANGED | rc=0 >>
hello
node2 | CHANGED | rc=0 >>
hello
公鑰認證
Ansible1.2.1及其之後的版本都會默認啟用公鑰認證
如果有個主機重新安裝並在“known_hosts”中有了不同的key,這會提示一個錯誤信息直到被糾正為止.在使用Ansible時,你可能不想遇到這樣的情況:如果有個主機沒有在“known_hosts”中被初始化將會導致在交互使用Ansible或定時執行Ansible時對key信息的確認提示.
如果你想禁用此項行為並明白其含義,你能夠通過編輯 /etc/ansible/ansible.cfg or ~/.ansible.cfg來實現:
[defaults]
host_key_checking = False
同樣注意在paramiko 模式中 公鑰認證 相當的慢.因此,當使用這項特性時,切換至’SSH’是推薦做法.
密碼認證
因為我們接下來要將存取的密碼放到主機清單甚至存到Mysql裏面,我們可以裝一個ssh_pass
apt-get install sshpass
我們將之前的公鑰.ssh目錄都刪掉,主機名解析不用管.
注意,刪除.ssh目錄過後記得關閉主機秘鑰檢查.
tail -3 /etc/hosts
121.36.43.223 node1
120.77.248.31 node2
116.196.83.113 master
tail -2 /etc/ansible/hosts
node1
node2
ansible all -m ping -k
# 並不是真的ping,只是檢查客戶端的22號端口是否提供工作.不指定用戶默認root用戶
# -k 輸入密碼
# -m 指定模塊
SSH password:
node1 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
node2 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
# 如果不想指定用戶名和密碼,避免ansible每次執行到相應主機都會要求輸入密碼.
tail -2 /etc/ansible/hosts
node1 ansible_ssh_user='root' ansible_ssh_pass='youmen'
node2 ansible_ssh_user='root' ansible_ssh_pass='youmen' ansible_ssh_port=22
ansible all -m ping
node1 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
node2 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
Ansible常用模塊
常用模塊
塊
| 模塊名 |
作用 |
用例 |
| command |
默認模塊 |
ansible webserver -a “/sbin/reboot” -f 10 |
| shell |
執行shell命令 |
ansible test -m shell -a “echo $HOSTNAME” |
| filetransfer |
文件傳輸 |
ansible test -m copy -a “src=/etc/hosts dest=/tmp/hosts” |
| managingpackages |
管理軟件包 |
ansible test -m yum -a “name=nginx state=present” |
| user and groups |
用戶和組 |
ansible test -m user -a “name=jeson password=123456” |
| Deploying |
部署模塊 |
ansible test -m git -a “repo=https://github.com/iopsgroup/imoocc dest=/opt/iops version=HEAD” |
| managingservices |
服務管理 |
ansible test -m service -a “name=nginx state=started” |
| BackgroundOperatiions |
後台運行 |
ansible test -B 3600 -a “/usr/bin/running_operation –do-stuff” |
| gatheringfacts |
搜集系統信息 |
ansible test -m setup |
playbook
playbook由YAML語言編寫,YAML參考了其他多種語言,包括: XML,C語言,Python,Perl以及电子郵件格式RFC2822,Clark Evans在2001年5月首次發表了這種語言,另外Ingy dt Net與Oren-Kiki也是這語言的共同設計者.
playbook的優勢
# 1. 功能比adhoc更全
# 2. 控制好依賴
# 3. 展現更直觀
# 4. 持久使用
ansible-playbook執行常用命令參數:
執行方式:ansible-playbook playbook.yml [options]
-u REMOTE_USER, --user=REMOTE_USER
# ssh 連接的用戶名
-k, --ask-pass
# ssh登錄認證密碼
-s, --sudo
# sudo 到root用戶,相當於Linux系統下的sudo命令
-U SUDO_USER, --sudo-user=SUDO_USER
# sudo 到對應的用戶
-K, --ask-sudo-pass
# 用戶的密碼(—sudo時使用)
-T TIMEOUT, --timeout=TIMEOUT
# ssh 連接超時,默認 10 秒
-C, --check
# 指定該參數后,執行 playbook 文件不會真正去執行,而是模擬執行一遍,然後輸出本次執行會對遠程主機造成的修改
-e EXTRA_VARS, --extra-vars=EXTRA_VARS
# 設置額外的變量如:key=value 形式 或者 YAML or JSON,以空格分隔變量,或用多個-e
-f FORKS, --forks=FORKS
# 進程併發處理,默認 5
-i INVENTORY, --inventory-file=INVENTORY
# 指定 hosts 文件路徑,默認 default=/etc/ansible/hosts
-l SUBSET, --limit=SUBSET
# 指定一個 pattern,對- hosts:匹配到的主機再過濾一次
--list-hosts
# 只打印有哪些主機會執行這個 playbook 文件,不是實際執行該 playbook
--list-tasks
# 列出該 playbook 中會被執行的 task
--private-key=PRIVATE_KEY_FILE
# 私鑰路徑
--step
# 同一時間只執行一個 task,每個 task 執行前都會提示確認一遍
--syntax-check
# 只檢測 playbook 文件語法是否有問題,不會執行該 playbook
-t TAGS, --tags=TAGS
# 當 play 和 task 的 tag 為該參數指定的值時才執行,多個 tag 以逗號分隔
--skip-tags=SKIP_TAGS
# 當 play 和 task 的 tag 不匹配該參數指定的值時,才執行
-v, --verbose
# 輸出更詳細的執行過程信息,-vvv可得到所有執行過程信息。
使用場景
yaml語法
- playbook配置
---
- hosts: 39.108.140.0
remote_user: root
vars:
touch_file: youmen.file
tasks:
- name: touch file
shell: "touch /tmp/{{touch_file}}"
yaml主要由三個部分組成:
> hosts部分:
# 使用hosts指示使用哪個主機或主機組來運行下面的tasks,
# 每個playbook都必須指定hosts,hosts也可以使用通配符格式。
# 主機或主機組在inventory清單中指定,可以使用系統默認的/etc/ansible/hosts,
# 也可以自己編輯,在運行的時候加上-i選項,指定清單的位置即可。
# 在運行清單文件的時候,--list-hosts選項會显示那些主機將會參与執行task的過程中。
> remote_user:指定遠端主機中的哪個用戶來登錄遠端系統,
# 在遠端系統執行task的用戶,可以任意指定,也可以使用sudo,
# 但是用戶必須要有執行相應task的權限。
> tasks:指定遠端主機將要執行的一系列動作。tasks的核心為ansible的模塊,
# 前面已經提到模塊的用法。tasks包含name和要執行的模塊,name是可選的,
# 只是為了便於用戶閱讀,不過還是建議加上去,模塊是必須的,同時也要給予模塊相應的參數。
執行
ansible-playbook -i /tmp/hosts --list-hosts ./f1.yaml
ansible-playbook ./f1.yaml
# 執行結果返回
# 紅色: 表示有task執行失敗或者提醒的信息
# 黃色: 表示執行了且改變了遠程主機狀態
# 綠色: 表示執行成功
yaml語法和數據結構
yaml語法
YAML格式是類似於JSON的文件格式,以便於人理解和閱讀,同時便於書寫,首先學習了解一下YAML的格式,對我們後面書寫playbook很有幫助.
以下為playbook常用到的YAML格式
# 大小寫敏感
# 使用縮緊表示層級關係(只能空格不能使用tab)
# yaml文件以"---"作為文檔的開始
# 在同一行中,#之後的內容表示註釋,類似於shell,python和ruby.
# YAML中的列表元素以"-"開頭,然後緊跟着一個空格,後面為元素內容,就像這樣
- apple
- orange
等價於JSON的這種格式
[
"apple",
"orange"
]
# 同一個列表中的元素應該保持相同的縮進,否則會被當做錯誤處理.
# play中hosts,variables,roles,tasks等對象的表示方法都是鍵值中間以":"分割表示,":"後面還要增加一個空格.
變量定義方式
變量名可以為字母,数字以及下劃線
playbook里的變量
1. playbook的yaml文件中定義變量賦值
> 2. --exxtra-vars執行參數賦給變量
> 3. 在文件中定義變量
> 4. 註冊變量
# register關鍵字可以存儲指定命令的輸出結果到一個自定義的變量中.
---
- hosts: database
remote_user: root
vars:
touch_file: youmen_file
tasks:
- name: get date
command: date
register: date_output
- name: touch
shell: "touch /tmp/{{touch_file}}"
- name: echo date_output
shell: "echo {{date_output.stdout}}>/tmp/{{touch_file}}"
數據結構
yaml支持的數據結構
字典
{name:jeson}
列表
- Apple
- Mango
- Orange
純量: 数字,布爾,字符串
條件判斷
循環
| 循環類型 |
關鍵字 |
|
| 標準循環 |
with_items |
|
| 嵌套循環 |
with_nested |
|
| 遍歷字典 |
with_dict |
|
| 并行遍歷列表 |
with_together |
|
| 遍歷列表和索引 |
with_indexed_items |
|
| 遍歷文件列表的內容 |
with_file |
|
| 遍歷目錄文件 |
with_fileglog |
|
| 重試循環 |
until |
|
| 查找第一個匹配文件 |
with_first_found |
|
| 隨機選擇 |
with_random_choice |
|
| 在序列中循環 |
with_sequence |
|
條件循環語句復用
種類一, 標準循環
---
- hosts: nginx
tasks:
- name: add serveral users
user: name={{ item.name }} state=present groups={{ item.groups }}
with_items:
- { name: 'testuser1',groups: 'wheel' }
- { name: 'testuser2',groups: 'root' }
種類二, 遍歷字典
---
- hosts: nginx
remote_user: root
tasks:
- name: add serveral users
user: name={{ item.key }} state=present groups={{ item.value }}
with_dict:
{ 'testuser3':'wheel','testuser4':'root' }
種類三, 遍歷目錄中內容
---
- hosts: nginx
remote_user: root
tasks:
- file: dest=/tmp/aa state=directory
- copy: src={{ item }} dest=/tmp/bb owner=root mode=600
with_fileglob:
- aa/*n
條件語句結合循環語句使用場景
---
- hosts: nginx
remote_user: root
tasks:
- debug: msg="{{ item.key }} is the winner"
with_dict: {'jeson':{'english':60,'chinese':30},'tom':{'english':20,'chinese':30}}
when: item.value.english >= 10
異常
異常處理和相關操作
異常處理
1.忽略錯誤
默認會檢查命令和模塊的返回狀態,遇到錯誤就中斷playbook的執行
加入參數: ignore_errors: yes
Example
- hosts: nginx
remote_user: root
tasks:
- name: ignore false
command: /bin/false
ignore_errors: yes
- name: touch a file
file: path=/tmp/test22 state=touch mode=0700 owner=root group=root
2. tags標籤處理
---
- hosts: nginx
remote_user: root
tasks:
- name: get process
shell: touch /tmp/change_test2
changed_when: false
打標籤
意義: 通過tags和任務對象進行捆綁,控制部分或者指定的task執行
# 打標籤
# 對一個對象打一個標籤
# 對一個對象打多個標籤
# 打標籤的對象包括: 單個task任務,include對象,roles對象等.
標籤使用
-t : 執行指定的tag標籤任務
--skip-tags: 執行 --skip-tags之外的標籤任務
- 自定義change狀態
---
- hosts: nginx
remote_user: root
tasks:
- name: get process
shell: ps -ef |wc -l
register: process_count
failed_when: process_count > 3
- name: touch a file
file: path=/tmp/test1 state=touch mode=0700 owner=root group=root
roles角色和場景演練
使用roles角色
include的用法
include_tasks/include: 動態的包含tasks任務列表執行
什麼是roles
是一種利用在大型playbook中的劇本配置模式,在這自己特定結構
為什麼需要用到roles
和面向對象開發思想相似
利用於大型的項目任務中,盡可能的將公共的任務,變量等內容獨立
劇本結構和設計思路
ansible官方網站的建議playbook劇本結構如下:
production # 正式環境的inventory文件
staging #測試環境用得inventory文件
group_vars/ # 機器組的變量文件
group1
group2
host_vars/ #執行機器成員的變量
hostname1
hostname2
================================================
site.yml # 主要的playbook劇本
webservers.yml # webserver類型服務所用的劇本
dbservers.yml # 數據庫類型的服務所用的劇本
roles/
webservers/ #webservers這個角色相關任務和自定義變量
tasks/
main.yml
handlers/
main.yml
vars/
main.yml
dbservers/ #dbservers這個角色相關任務和定義變量
...
common/ # 公共的
tasks/
main.yml
handlers/
main.yml # handlers file.
vars/ # 角色所用到的變量
main.yml #
===============================================
templates/ #
ntp.conf.j2 # 模版文件
files/ # 用於上傳存放文件的目錄
bar.txt
foo.sh
meta/ # 角色的依賴
main.yml
場景演練
Nginx工程方式的編譯安裝
# 劇本分解
ansible.cfg
- files # 存放上傳文件
- index.html
- nginx # 系統init中,控制nginx啟動腳本
- nginx-1.12.2.tar.gz # nginx的安裝包文件
production # 線上的主機配置文件
roles # roles角色執行
- apache
- common
tasks
main.yml
vars
main.yml
meta
nginx
- handlers 通過notify觸發
main.yml
- tasks
- basic.yml
- main.yml
- nginx.yml
- vars
= main.yml
tasks
staging 線下測試環境使用的主機配置文件
- templates 模板(配置,html)
- nginx1.conf nginx的自定義conf文件
webserver.yaml web服務相關主執行文件
Ansible的核心類介紹
| 核心類 |
用途 |
所在的模塊路徑 |
| DataLoader |
用於讀取yaml,json格式的文件 |
ansible.parsing.dataloader |
| Play |
存儲執行hosts的角色信息 |
ansible.playbook.play |
| TaskQueueManager |
ansible底層用到的任務隊列 |
ansible.executor.task_queue_manager |
| PlaybookExecutor |
核心累執行playbook劇本 |
ansible.executor.playbook_executor |
| CallbackBase |
狀態回調,各種成功失敗的狀態 |
ansible.plugins.callback |
| InventoryManager |
用於導入inventory文件 |
ansible.inventory.manager |
| VariableManager |
用於存儲各類變量信息 |
ansible.vars.manager |
| Host,Group |
用於操作單個主機或者主機組信息 |
ansible.inventory.host |
InventoryManager
用來管理主機和主機組信息
from ansible.parsing.dataloader import DataLoader
from ansible.inventory.manager import InventoryManager
# InventoryManager類
loader = DataLoader()
InventoryManager(loader=loader,sources=['youmen_hosts'])
# 1. 添加主機到指定主機組 add_host()
# 2. 查看主機組資源get_groups_dict()
# 3. 獲取指定的主機對象get_host()
# VariableManager類
# loader: 實例對象
# inventory: 調用InventoryManager返回的實例對象.
VariableManager(loader=loader,inventory=inventory)
# 查看主機變量方法 get_vars()
# 設置主機變量方法set_host_variable()
# 添加擴展變量extra_vars
ad-hoc模式調用場景
ansible -m command -a "ls /tmp" testgroup -i /etc/ansible/hosts -f 5
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化