摘要:LeNet-5是Yann LeCun在1998年設計的用於手寫数字識別的卷積神經網絡,當年美國大多數銀行就是用它來識別支票上面的手寫数字的,它是早期卷積神經網絡中最有代表性的實驗系統之一。可以說,LeNet-5就相當於編程語言入門中的“Hello world!”。
華為的昇騰訓練芯片一直是大家所期待的,目前已經開始提供公測,如何在昇騰訓練芯片上運行一個訓練任務,這是目前很多人都在采坑過程中,所以我寫了一篇指導文章,附帶上所有相關源代碼。注意,本文並沒有包含環境的安裝,請查看另外相關文檔。
環境約束:昇騰910目前僅配套TensorFlow 1.15版本。
基礎鏡像上傳之後,我們需要啟動鏡像命令,以下命令掛載了8塊卡(單機所有卡):
docker run -it –net=host –device=/dev/davinci0 –device=/dev/davinci1 –device=/dev/davinci2 –device=/dev/davinci3 –device=/dev/davinci4 –device=/dev/davinci5 –device=/dev/davinci6 –device=/dev/davinci7 –device=/dev/davinci_manager –device=/dev/devmm_svm –device=/dev/hisi_hdc -v /var/log/npu/slog/container/docker:/var/log/npu/slog -v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ -v /usr/local/Ascend/driver/tools/:/usr/local/Ascend/driver/tools/ -v /data/:/data/ -v /home/code:/home/local/code -v ~/context:/cache ubuntu_18.04-docker.arm64v8:v2 /bin/bash
設置環境變量並啟動手寫字訓練網絡:
#!/bin/bash
export LD_LIBRARY_PATH=/usr/local/lib/:/usr/local/HiAI/runtime/lib64
export PATH=/usr/local/HiAI/runtime/ccec_compiler/bin:$PATH
export CUSTOM_OP_LIB_PATH=/usr/local/HiAI/runtime/ops/framework/built-in/tensorflow
export DDK_VERSION_PATH=/usr/local/HiAI/runtime/ddk_info
export WHICH_OP=GEOP
export NEW_GE_FE_ID=1
export GE_AICPU_FLAG=1
export OPTION_EXEC_EXTERN_PLUGIN_PATH=/usr/local/HiAI/runtime/lib64/plugin/opskernel/libfe.so:/usr/local/HiAI/runtime/lib64/plugin/opskernel/libaicpu_plugin.so:/usr/local/HiAI/runtime/lib64/plugin/opskernel/libge_local_engine.so:/usr/local/H
iAI/runtime/lib64/plugin/opskernel/librts_engine.so:/usr/local/HiAI/runtime/lib64/libhccl.so
export OP_PROTOLIB_PATH=/usr/local/HiAI/runtime/ops/built-in/
export DEVICE_ID=2
export PRINT_MODEL=1
#export DUMP_GE_GRAPH=2
#export DISABLE_REUSE_MEMORY=1
#export DUMP_OP=1
#export SLOG_PRINT_TO_STDOUT=1
export RANK_ID=0
export RANK_SIZE=1
export JOB_ID=10087
export OPTION_PROTO_LIB_PATH=/usr/local/HiAI/runtime/ops/op_proto/built-in/
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/Ascend/fwkacllib/lib64/:/usr/local/Ascend/driver/lib64/common/:/usr/local/Ascend/driver/lib64/driver/:/usr/local/Ascend/add-ons/
export PYTHONPATH=$PYTHONPATH:/usr/local/Ascend/opp/op_impl/built-in/ai_core/tbe
export PATH=$PATH:/usr/local/Ascend/fwkacllib/ccec_compiler/bin
export ASCEND_HOME=/usr/local/Ascend
export ASCEND_OPP_PATH=/usr/local/Ascend/opp
export SOC_VERSION=Ascend910
rm -f *.pbtxt
rm -f *.txt
rm -r /var/log/npu/slog/*.log
rm -rf train_url/*
python3 mnist_train.py
以下訓練案例中我使用的lecun大師的LeNet-5網絡,先簡單介紹LeNet-5網絡:
LeNet5誕生於1994年,是最早的卷積神經網絡之一,並且推動了深度學習領域的發展。自從1988年開始,在多年的研究和許多次成功的迭代后,這項由Yann LeCun完成的開拓性成果被命名為LeNet5。
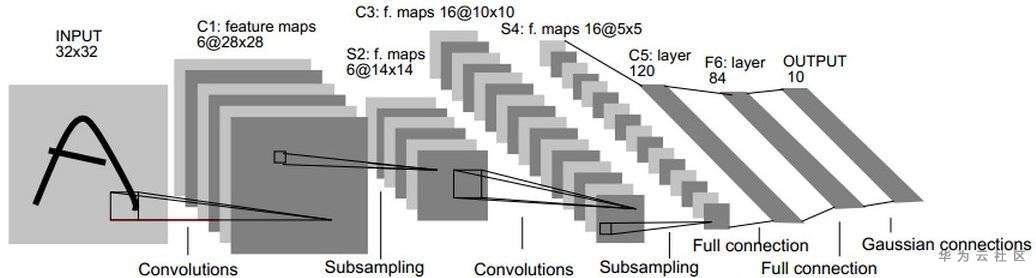
LeNet-5包含七層,不包括輸入,每一層都包含可訓練參數(權重),當時使用的輸入數據是32*32像素的圖像。下面逐層介紹LeNet-5的結構,並且,卷積層將用Cx表示,子採樣層則被標記為Sx,完全連接層被標記為Fx,其中x是層索引。
層C1是具有六個5*5的卷積核的卷積層(convolution),特徵映射的大小為28*28,這樣可以防止輸入圖像的信息掉出卷積核邊界。C1包含156個可訓練參數和122304個連接。
層S2是輸出6個大小為14*14的特徵圖的子採樣層(subsampling/pooling)。每個特徵地圖中的每個單元連接到C1中的對應特徵地圖中的2*2個鄰域。S2中單位的四個輸入相加,然後乘以可訓練係數(權重),然後加到可訓練偏差(bias)。結果通過S形函數傳遞。由於2*2個感受域不重疊,因此S2中的特徵圖只有C1中的特徵圖的一半行數和列數。S2層有12個可訓練參數和5880個連接。
層C3是具有16個5-5的卷積核的卷積層。前六個C3特徵圖的輸入是S2中的三個特徵圖的每個連續子集,接下來的六個特徵圖的輸入則來自四個連續子集的輸入,接下來的三個特徵圖的輸入來自不連續的四個子集。最後,最後一個特徵圖的輸入來自S2所有特徵圖。C3層有1516個可訓練參數和156 000個連接。
層S4是與S2類似,大小為2*2,輸出為16個5*5的特徵圖。S4層有32個可訓練參數和2000個連接。
層C5是具有120個大小為5*5的卷積核的卷積層。每個單元連接到S4的所有16個特徵圖上的5*5鄰域。這裏,因為S4的特徵圖大小也是5*5,所以C5的輸出大小是1*1。因此S4和C5之間是完全連接的。C5被標記為卷積層,而不是完全連接的層,是因為如果LeNet-5輸入變得更大而其結構保持不變,則其輸出大小會大於1*1,即不是完全連接的層了。C5層有48120個可訓練連接。
F6層完全連接到C5,輸出84張特徵圖。它有10164個可訓練參數。這裏84與輸出層的設計有關。
LeNet的設計較為簡單,因此其處理複雜數據的能力有限;此外,在近年來的研究中許多學者已經發現全連接層的計算代價過大,而使用全部由卷積層組成的神經網絡。
LeNet-5網絡訓練腳本是mnist_train.py,具體代碼:
import os
import numpy as np
import tensorflow as tf
import time
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
from npu_bridge.estimator import npu_ops #導入NPU算子庫
from tensorflow.core.protobuf.rewriter_config_pb2 import RewriterConfig #重寫tensorFlow里的配置,針對NPU的配置
batch_size = 100
learning_rate = 0.1
training_step = 10000
model_save_path = "./model/"
model_name = "model.ckpt"
def train(mnist):
x = tf.placeholder(tf.float32, [batch_size, mnist_inference.image_size, mnist_inference.image_size, mnist_inference.num_channels], name = 'x-input')
y_ = tf.placeholder(tf.float32, [batch_size, mnist_inference.num_labels], name = "y-input")
regularizer = tf.contrib.layers.l2_regularizer(0.001)
y = mnist_inference.inference(x, train = True, regularizer = regularizer) #推理過程
global_step = tf.Variable(0, trainable=False)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits = y, labels = tf.argmax(y_, 1)) #損失函數
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection("loss"))
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step = global_step) #優化器調用
saver = tf.train.Saver() #啟動訓練
#以下代碼是NPU所必須的代碼,開始配置參數
config = tf.ConfigProto(
allow_soft_placement = True,
log_device_placement = False)
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
#custom_op.parameter_map["profiling_mode"].b = True
#custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes("task_trace:training_trace")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
#配置參數結束
writer = tf.summary.FileWriter("./log_dir", tf.get_default_graph())
writer.close()
#參數初始化
with tf.Session(config = config) as sess:
tf.global_variables_initializer().run()
start_time = time.time()
for i in range(training_step):
xs, ys = mnist.train.next_batch(batch_size)
reshaped_xs = np.reshape(xs, (batch_size, mnist_inference.image_size, mnist_inference.image_size, mnist_inference.num_channels))
_, loss_value, step = sess.run([train_step, loss, global_step], feed_dict={x:reshaped_xs, y_:ys})
#每訓練10個epoch打印損失函數輸出日誌
if i % 10 == 0:
print("****************************++++++++++++++++++++++++++++++++*************************************\n" * 10)
print("After %d training steps, loss on training batch is %g, total time in this 1000 steps is %s." % (step, loss_value, time.time() - start_time))
#saver.save(sess, os.path.join(model_save_path, model_name), global_step = global_step)
print("****************************++++++++++++++++++++++++++++++++*************************************\n" * 10)
start_time = time.time()
def main():
mnist = input_data.read_data_sets('MNIST_DATA/', one_hot= True)
train(mnist)
if __name__ == "__main__":
main()
本文主要講述了經典卷積神經網絡之LeNet-5網絡模型和遷移至昇騰D910的實現,希望大家快來動手操作一下試試看!
點擊關注,第一時間了解華為雲新鮮技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※推薦評價好的iphone維修中心