目錄
一.ThreadLocal介紹
1.1 ThreadLocal的功能
1.2 ThreadLocal使用示例
二.源碼分析-ThreadLocal
2.1 ThreadLocal的類層級關係
2.2 ThreadLocal的屬性字段
2.3 創建ThreadLocal對象
2.4 ThreadLocal-set操作
2.5 ThreadLocal-get操作
2.6 ThreadLocal-remove操作
三.ThreadLocalMap類
3.0 線性探測算法解決hash衝突
3.1 Entry內部類
3.2 ThreadLocalMap的常量介紹
3.3 實例化ThreadLocalMap
3.4 ThreadLocalMap的set操作
3.5 清理陳舊Entry和rehash
四.總結
一.介紹ThreadLocal
1.1ThreadLocal的功能
我們知道,變量從作用域範圍進行分類,可以分為“全局變量”、“局部變量”兩種:
1.全局變量(global variable),比如類的靜態屬性(加static關鍵字),在類的整個生命周期都有效;
2.局部變量(local variable),比如在一個方法中定義的變量,作用域只是在當前方法內,方法執行完畢后,變量就銷毀(釋放)了;
使用全局變量,當多個線程同時修改靜態屬性,就容易出現併發問題,導致臟數據;而局部變量一般來說不會出現併發問題(在方法中開啟多線程併發修改局部變量,仍可能引起併發問題);
再看ThreadLocal,可以用來保存局部變量,只不過這個“局部”是指“線程”作用域,也就是說,該變量在該線程的整個生命周期中有效。
關於ThreadLocal的使用場景,可以查看ThreadLocal的使用場景分析。
1.2ThreadLocal的使用示例
ThreadLocal使用非常簡單。
package cn.ganlixin;
import org.junit.Test;
import java.util.Arrays;
import java.util.List;
public class TestThreadLocal {
private static class Goods {
public Integer id;
public List<String> tags;
}
@Test
public void testReference() {
Goods goods1 = new Goods();
goods1.id = 10;
goods1.tags = Arrays.asList("healthy", "cheap");
ThreadLocal<Goods> threadLocal = new ThreadLocal<>();
threadLocal.set(goods1);
Goods goods2 = threadLocal.get();
System.out.println(goods1); // cn.ganlixin.TestThreadLocal$Goods@1c655221
System.out.println(goods2); // cn.ganlixin.TestThreadLocal$Goods@1c655221
goods2.id = 100;
System.out.println(goods1.id); // 100
System.out.println(goods2.id); // 100
threadLocal.remove();
System.out.println(threadLocal.get()); // null
}
@Test
public void test2() {
// 一個線程中,可以創建多個ThreadLocal對象,多個ThreadLoca對象互不影響
ThreadLocal<String> threadLocal1 = new ThreadLocal<>();
ThreadLocal<String> threadLocal2 = new ThreadLocal<>();
// ThreadLocal存的值默認為null
System.out.println(threadLocal1.get()); // null
threadLocal1.set("this is value1");
threadLocal2.set("this is value2");
System.out.println(threadLocal1.get()); // this is value1
System.out.println(threadLocal2.get()); // this is value2
// 可以重寫initialValue進行設置初始值
ThreadLocal<String> threadLocal3 = new ThreadLocal<String>() {
@Override
protected String initialValue() {
return "this is initial value";
}
};
System.out.println(threadLocal3.get()); // this is initial value
}
}
二.源碼分析-ThreadLocal
2.1ThreadLocal類層級關係
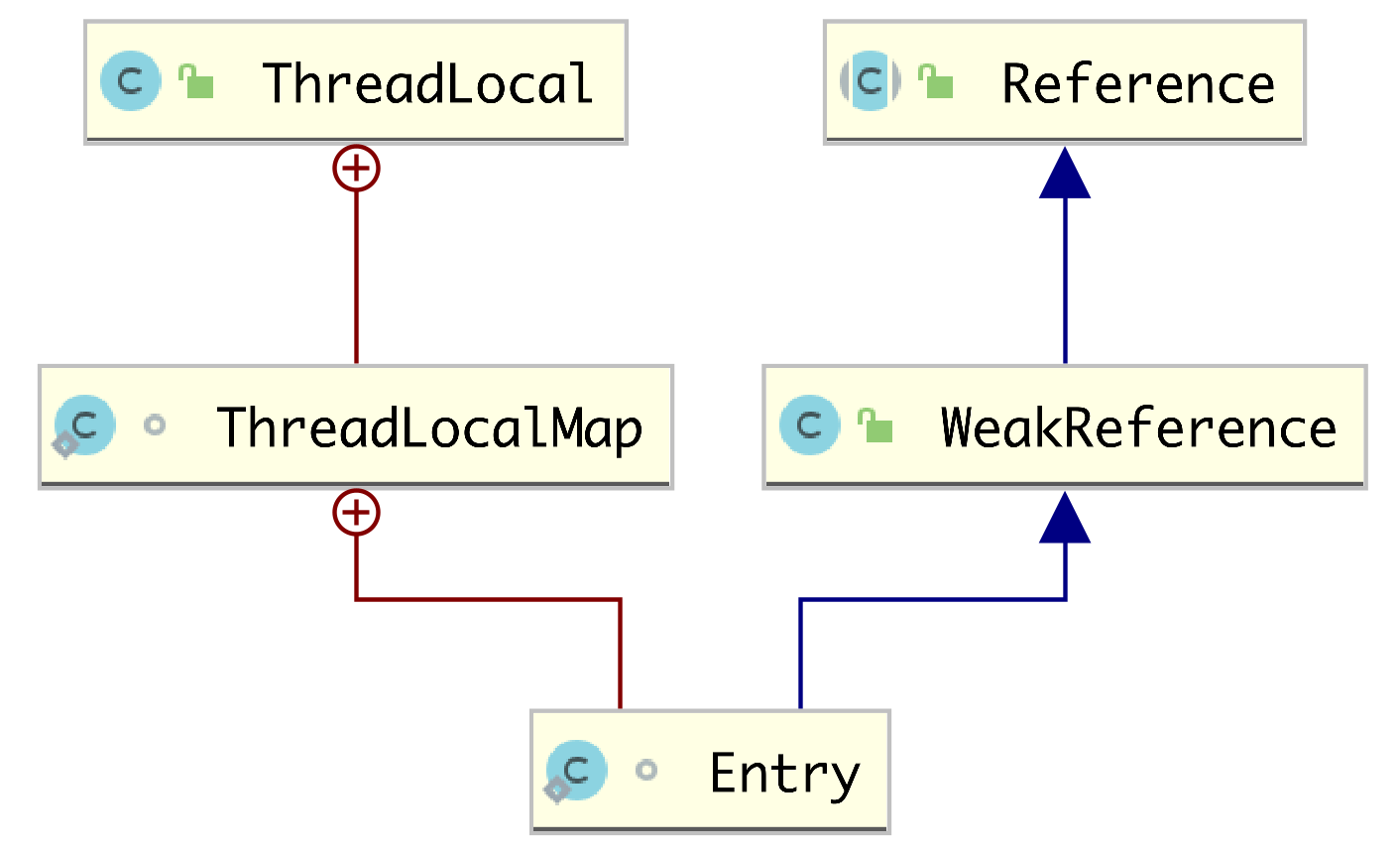
ThreadLocal類中有一個內部類ThreadLocalMap,這個類特別重要,ThreadLocal的各種操作基本都是圍繞ThreadLocalMap進行的。
對於ThreadLocalMap有來說,它內部定義了一個Entry內部類,有一個table屬性,是一個Entry數組,和HashMap有一些相似的地方,但是ThreadLocalMap和HashMap並沒有什麼關係。
先大概看一下內存關係圖,不理解也沒關係,看了後面的代碼應該就能理解了:
大概解釋一下,棧中的Thread ref(引用)堆中的Thread對象,Thread對象有一個屬性threadlocals(ThreadLocalMap類型),這個Map中每一項(Entry)的value是ThreadLocal.set()的值,而Map的key則是ThreadLocal對象。
下面在介紹源碼的時候,會從兩部分進行介紹,先介紹ThreadLocal的常用api,然後再介紹ThreadLocalMap,因為ThreadLocal的api內部其實都是在操作ThreadLocalMap,所以看源碼時一定要知道他們倆之間的關係。
2.2ThreadLocal的屬性
ThreadLocal有3個屬性,主要的功能就是生成ThreadLocal的hash值。
// threadLocalHashCode用來表示當前ThreadLocal對象的hashCode,通過計算獲得
private final int threadLocalHashCode = nextHashCode();
// 一個AtomicInteger類型的屬性,功能就是計數,各種操作都是原子性的,在併發時不會出現問題
private static AtomicInteger nextHashCode = new AtomicInteger();
// hash值的增量,不是隨便指定的,被稱為“黃金分割數”,能讓hash結果均衡分佈
private static final int HASH_INCREMENT = 0x61c88647;
/**
* 通過計算,為當前ThreadLocal對象生成一個HashCode
*/
private static int nextHashCode() {
// 獲取當前nextHashCode,然後遞增HASH_INCREMENT
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
2.3創建ThreadLocal對象
ThreadLocal類,只有一個無參構造器,如果需要是指默認值,則可以重寫initialValue方法:
public ThreadLocal() {}
/**
* 初始值默認為null,要設置初始值,只需要設置為方法返回值即可
*
* @return ThreadLocal的初始值
*/
protected T initialValue() {
return null;
}
需要注意的是initialValue方法並不會在創建ThreadLocal對象的時候設置初始值,而是延遲執行:當ThreadLocal直接調用get時才會觸發initialValue執行(get之前沒有調用set來設置過值),initialValue方法在後面還會介紹。
2.4ThreadLocal-set操作
下面這段代碼只給出了ThreadLocal的set代碼:
public void set(T value) {
// 獲取當前線程
Thread t = Thread.currentThread();
// 獲取當前線程的ThreadLocalMap屬性,ThreadLocal有一個threadLocals屬性(ThreadLocalMap類型)
ThreadLocalMap map = getMap(t);
if (map != null) {
// 如果當前線程有關聯的ThreadLocalMap對象,則調用ThreadLocalMap的set方法進行設置
map.set(this, value);
} else {
// 創建一個與當前線程關聯的ThreadLocalMap對象,並設置對應的value
createMap(t, value);
}
}
/**
* 獲取線程關聯的ThreadLocalMap對象
*/
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
/**
* 創建ThreadLocalMap
* @param t key為當前線程
* @param firstValue value為ThreadLocal.set的值
*/
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
如果想立即了解ThreadLocalMap的set方法,則可點此跳轉!
2.5ThreadLocal-get操作
前面說過“重寫ThreadLocal的initialValue方法來設置ThreadLocal的默認值,並不是在創建ThreadLocal的時候執行的,而是在直接get的時候執行的”,看了下面的代碼,就知道這句話的具體含義了,感覺設計很巧妙:
public T get() {
// 獲取當前線程
Thread t = Thread.currentThread();
// 獲取當前線程對象的threadLocals屬性
ThreadLocalMap map = getMap(t);
// 若當前線程對象的threadLocals屬性不為空(map不為空)
if (map != null) {
// 當前ThreadLocal對象作為key,獲取ThreadLocalMap中對應的Entry
ThreadLocalMap.Entry e = map.getEntry(this);
// 如果找到對應的Entry,則證明該線程的該ThreadLocal有值,返回值即可
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T) e.value;
return result;
}
}
// 1.當前線程對象的threadLocals屬性為空(map為空)
// 2.或者map不為空,但是未在map中查詢到以該ThreadLocal對象為key對應的entry
// 這兩種情況,都會進行設置初始值,並將初始值返回
return setInitialValue();
}
/**
* 設置ThreadLocal初始值
*
* @return 初始值
*/
private T setInitialValue() {
// 調用initialValue方法,該方法可以在創建ThreadLocal的時候重寫
T value = initialValue();
Thread t = Thread.currentThread();
// 獲取當前線程的threadLocals屬性(map)
ThreadLocalMap map = getMap(t);
if (map != null) {
// threadLocals屬性值不為空,則進行調用ThreadLocalMap的set方法
map.set(this, value);
} else {
// 沒有關聯的threadLocals,則創建ThreadLocalMap,並在map中新增一個Entry
createMap(t, value);
}
// 返回初始值
return value;
}
/**
* 初始值默認為null,要設置初始值,只需要設置為方法返回值即可
* 創建ThreadLocal設置默認值,可以覆蓋initialValue方法,initialValue方法不是在創建ThreadLocal時執行,而是這個時候執行
*
* @return ThreadLocal的初始值
*/
protected T initialValue() {
return null;
}
2.6ThreadLocal-remove操作
一般是在ThreadLocal對象使用完后,調用ThreadLocal的remove方法,在一定程度上,可以避免內存泄露;
/**
* 刪除當前線程中threadLocals屬性(map)中的Entry(以當前ThreadLocal為key的)
*/
public void remove() {
// 獲取當前線程的threadLocals屬性(ThreadLocalMap)
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null) {
// 調用ThreadLocalMap的remove方法,刪除map中以當前ThreadLocal為key的entry
m.remove(this);
}
}
三.ThreadLocalMap內部類
3.0 線性探測算法解決hash衝突
在介紹ThreadLocalMap的之前,強烈建議先了解一下線性探測算法,這是一種解決Hash衝突的方案,如果不了解這個算法就去看ThreadLocalMap的源碼就會非常吃力,會感到莫名其妙。
鏈接在此:利用線性探測法解決hash衝突
3.1Entry內部類
ThreadLocalMap是ThreadLocal的內部類,ThreadLocalMap底層使用數組實現,每一個數組的元素都是Entry類型(在ThreadLocalMap中定義的),源碼如下:
/**
* ThreadLocalMap中存放的元素類型,繼承了弱引用類
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
// key對應的value,注意key是ThreadLocal類型
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
ThreadLocalMap和HashMap類似,比較一下:
a:底層都是使用數組實現,數組元素類型都是內部定義,Java8中,HashMap的元素是Node類型(或者TreeNode類型),ThreadLocalMap中的元素類型是Entry類型;
b.都是通過計算得到一個值,將這個值與數組的長度(容量)進行與操作,確定Entry應該放到哪個位置;
c.都有初始容量、負載因子,超過擴容閾值將會觸發擴容;但是HashMap的初始容量、負載因子是可以更改的,而ThreadLocalMap的初始容量和負載因子不可修改;
注意Entry繼承自WeakReference類,在實例化Entry時,將接收的key傳給父類構造器(也就是WeakReference的構造器),WeakReference構造器又將key傳給它的父類構造器(Reference):
// 創建Reference對象,接受一個引用
Reference(T referent) {
this(referent, null);
}
// 設置引用
Reference(T referent, ReferenceQueue<? super T> queue) {
this.referent = referent;
this.queue = (queue == null) ? ReferenceQueue.NULL : queue;
}
關於Java的各種引用,可以參考:Java-強引用、軟引用、弱引用、虛引用
3.2ThreadLocalMap的常量介紹
// ThreadLocalMap的初始容量 private static final int INITIAL_CAPACITY = 16; // ThreadLocalMap底層存數據的數組 private Entry[] table; // ThreadLocalMap中元素的個數 private int size = 0; // 擴容閾值,當size達到閾值時會觸發擴容(loadFactor=2/3;newCapacity=2*oldCapacity) private int threshold; // Default to 0
3.3創建ThreadLocalMap對象
創建ThreadLocalMap,是在第一次調用ThreadLocal的set或者get方法時執行,其中第一次未set值,直接調用get時,就會利用ThreadLocal的初始值來創建ThreadLocalMap。
ThreadLocalMap內部類的源碼如下:
/**
* 初始化一個ThreadLocalMap對象(第一次調用ThreadLocal的set方法時創建),傳入ThreadLocal對象和對應的value
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 創建一個Entry數組,容量為16(默認)
table = new Entry[INITIAL_CAPACITY];
// 計算新增的元素,應該放到數組的哪個位置,根據ThreadLocal的hash值與初始容量進行"與"操作
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
// 創建一個Entry,設置key和value,注意Entry中沒有key屬性,key屬性是傳給Entry的父類WeakReference
table[i] = new Entry(firstKey, firstValue);
// 初始容量為1
size = 1;
// 設置擴容閾值
setThreshold(INITIAL_CAPACITY);
}
/**
* 設置擴容閾值,接收容量值,負載因子固定為2/3
*/
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
3.4 ThreadLocalMap的set操作
ThreadLocal的set方法,其實核心就是調用ThreadLocalMap的set方法,set方法的流程比較長
/**
* 為當前ThreadLocal對象設置value
*/
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
// 計算新元素應該放到哪個位置(這個位置不一定是最終存放的位置,因為可能會出現hash衝突)
int i = key.threadLocalHashCode & (len - 1);
// 判斷計算出來的位置是否被佔用,如果被佔用,則需要找出應該存放的位置
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
// 獲取Entry中key,也就是弱引用的對象
ThreadLocal<?> k = e.get();
// 判斷key是否相等(判斷弱引用的是否為同一個ThreadLocal對象)如果是,則進行覆蓋
if (k == key) {
e.value = value;
return;
}
// k為null,也就是Entry的key已經被回收了,當前的Entry是一個陳舊的元素(stale entry)
if (k == null) {
// 用新元素替換掉陳舊元素,同時也會清理其他陳舊元素,防止內存泄露
replaceStaleEntry(key, value, i);
return;
}
}
// map中沒有ThreadLocal對應的key,或者說沒有找到陳舊的Entry,則創建一個新的Entry,放入數組中
tab[i] = new Entry(key, value);
// ThreadLocalMap的元素數量加1
int sz = ++size;
// 先清理map中key為null的Entry元素,該Entry也應該被回收掉,防止內存泄露
// 如果清理出陳舊的Entry,那麼就判斷是否需要擴容,如果需要的話,則進行rehash
if (!cleanSomeSlots(i, sz) && sz >= threshold) {
rehash();
}
}
上面最後幾行代碼涉及到清理陳舊Entry和rehash,這兩塊的代碼在下面。
3.5清理陳舊Entry和rehash
陳舊的Entry,是指Entry的key為null,這種情況下,該Entry是不可訪問的,但是卻不會被回收,為了避免出現內存泄漏,所以需要在每次get、set、replace時,進行清理陳舊的Entry,下面只給出一部分代碼:
/**
* 清理map中key為null的Entry元素,該Entry也應該被回收掉,防止內存泄露
*
* @param i 新Entry插入的位置
* @param n 數組中元素的數量
* @return 是否有陳舊的entry的清除
*/
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
} while ((n >>>= 1) != 0);
return removed;
}
private void rehash() {
// 清除底層數組中所有陳舊的(stale)的Entry,也就是key為null的Entry
// 同時每清除一個Entry,就對其後面的Entry重新計算hash,獲取新位置,使用線性探測法,重新確定最終位置
expungeStaleEntries();
// 清理完陳舊Entry后,判斷是否需要擴容
if (size >= threshold - threshold / 4) {
// 擴容時,容量變為舊容量的2倍,再進行rehash,並使用線性探測發確定Entry的新位置
resize();
}
}
在rehash的時候,涉及到“線性探測法”,是一種用來解決hash衝突的方案,可以查看利用線性探測法解決hash衝突了解詳情。
3.6ThreadLocalMap-remove操作
remove操作,是調用ThreadLocal.remove()方法時,刪除當前線程的ThreadLocalMap中該ThreadLocal為key的Entry。
/**
* 移除當前線程的threadLocals屬性中key為ThreadLocal的Entry
*
* @param key 要移除的Entry的key(ThreadLocal對象)
*/
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
// 計算出該ThreadLocal對應的key應該存放的位置
int i = key.threadLocalHashCode & (len - 1);
// 找到指定位置,開始按照線性探測算法進行查找到該Thread的Entry
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
// 如果Entry的key相同
if (e.get() == key) {
// 調用WeakReference的clear方法,Entry的key是弱引用,指向ThreadLocal,現在將key指向null
// 則該ThreadLocal對象在會在下一次gc時,被垃圾收集器回收
e.clear();
// 將該位置的Entry中的value置為null,於是value引用的對象也會被垃圾收集器回收(不會造成內存泄漏)
// 同時內部會調整Entry的順序(開放探測算法的特點,刪除元素後會重新調整順序)
expungeStaleEntry(i);
return;
}
}
}
四.總結
在學習ThreadLocal類源碼的過程還是受益頗多的:
1.ThreadLocal的使用場景;
2.initialValue的延遲執行;
3.HashMap使用鏈表+紅黑樹解決hash衝突,ThreadLocalMap使用線性探測算法(開放尋址)解決hash衝突
另外,ThreadLocal還有一部分內容,是關於弱引用和內存泄漏的問題,可以參考:分析ThreadLocal的弱引用與內存泄漏問題-Java8。
原文地址:https://www.cnblogs.com/-beyond/p/13093032.html
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?