在上一篇文章《MySQL常見加鎖場景分析》中,我們聊到行鎖是加在索引上的,但是複雜的 SQL 往往包含多個條件,涉及多個索引,找出 SQL 執行時使用了哪些索引對分析加鎖場景至關重要。
比如下面這樣的 SQL:
mysql> delete from t1 where id = 1 or val = 1
其中 id 和 val 都是索引,那麼執行時使用到了哪些索引,加了哪些鎖呢?為此,我們需要使用 explain 來獲取 MySQL 執行這條 SQL 的執行計劃。
什麼是執行計劃呢?簡單來說,就是 SQL 在數據庫中執行時的表現情況,通常用於 SQL 性能分析、優化和加鎖分析等場景,執行過程會在 MySQL 查詢過程中由解析器,預處理器和查詢優化器共同生成。
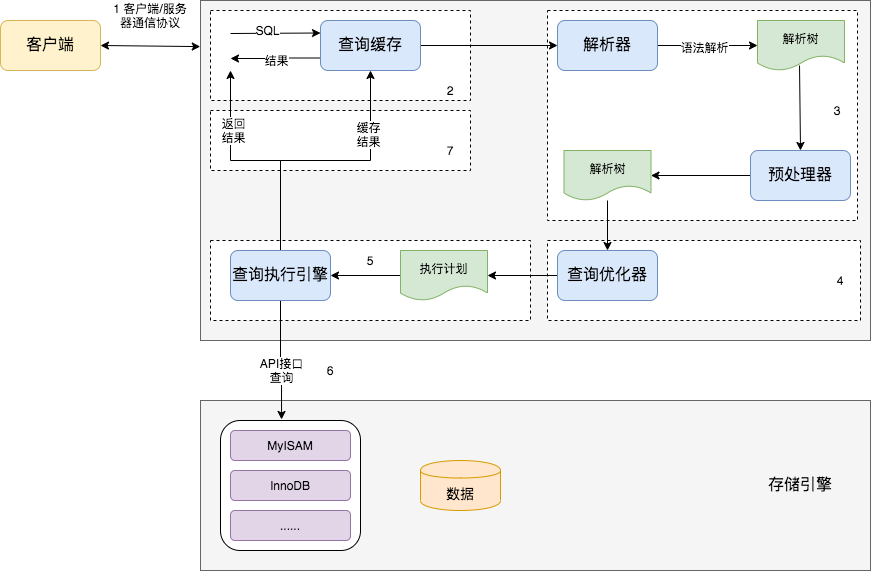
MySQL 查詢過程
如果能搞清楚 MySQL 是如何優化和執行查詢的,不僅對優化查詢一定會有幫助,還可以通過分析使用到的索引來判斷最終的加鎖場景。
下圖是MySQL執行一個查詢的過程。實際上每一步都比想象中的複雜,尤其優化器,更複雜也更難理解。本文只給予簡單的介紹。
MySQL查詢過程如下:
- 客戶端發送一條查詢給服務器。
- 服務器先檢查查詢緩存,如果命中了緩存,則立刻返回存儲在緩存中的結果。否則進入下一階段。
- 服務器端進行SQL解析、預處理,再由優化器生成對應的執行計劃。
- MySQL根據優化器生成的執行計劃,再調用存儲引擎的API來執行查詢。
- 將結果返回給客戶端。
執行計劃
MySQL會解析查詢,並創建內部數據結構(解析樹),並對其進行各種優化,包括重寫查詢、決定表的讀取順序、選擇合適的索引等。
用戶可通過關鍵字提示(hint)優化器,從而影響優化器的決策過程。也可以通過 explain 了解 數據庫是如何進行優化決策的,並提供一個參考基準,便於用戶重構查詢和數據庫表的 schema、修改數據庫配置等,使查詢盡可能高效。
下面,我們依次介紹 explain 中相關輸出參數,並以實際例子解釋這些參數的含義。
select_type
查詢數據的操作類型,有如下
- simple 簡單查詢,不包含子查詢或 union,如下圖所示,就是最簡單的查詢語句。
-
primary 是 SQL 中包含複雜的子查詢,此時最外層查詢標記為該值。
-
derived 是 SQL 中 from 子句中包含的子查詢被標記為該值,MySQL 會遞歸執行這些子查詢,把結果放在臨時表。下圖展示了上述兩種類型。
- subquery 是 SQL 在 select 或者 where 里包含的子查詢,被標記為該值。
- dependent subquery:子查詢中的第一個 select,取決於外側的查詢,一般是 in 中的子查詢。
-
union 是 SQL 在出現在 union 關鍵字之後的第二個 select ,被標記為該值;若 union 包含在 from 的子查詢中,外層select 被標記為 derived。
-
union result 從 union 表獲取結果的 select。下圖展示了 union 和 union result 的 SQL 案例。
- dependent union 也是 union 關鍵字之後的第二個或者後邊的那個 select 語句,和 dependent subquery 一樣,取決於外面的查詢。
type
表的連接類型,其性能由高到低排列為 system,const,eq_ref,ref,range,index 和 all。
- system 表示表只有一行記錄,相當於系統表。如下圖所示,因為 from 的子查詢派生的表只有一行數據,所以 primary 的表連接類型為 system。
- const 通過索引一次就找到,只匹配一行數據,用於常數值比較PRIMARY KEY 或者 UNIQUE索引。
-
eq_ref 唯一性索引掃描,對於每個索引鍵,表中只有一條記錄與之匹配,常用於主鍵或唯一索引掃描。對於每個來自前邊的表的行組合,從該表中讀取一行。它是除了 const 類型外最好的連接類型。
如下圖所示,對錶 t1 查詢的 type 是 ALL,表示全表掃描,然後 t1 中每一行數據都來跟 t2.id 這個主鍵索引進行對比,所以 t2 表的查詢就是 eq_ref。
- ref 非唯一性索引掃描,返回匹配某個單獨值的所有行,和 eq_ref 的區別是索引是非唯一索引,具體案例如下所示。
- range 只檢查給定範圍的行,使用一個索引來選擇行,當使用 =, between, >, <, 和 in 等操作符,並使用常數比較關鍵列時。如下圖所示,其中 id 為唯一索引,而 val 是非唯一索引。
-
index 與 ALL 類型類似,唯一區別就是只遍歷索引樹讀取索引值,比 ALL 讀取所有數據行要稍微快一些,因為索引文件通常比數據文件小。這裏涉及 MySQL 的索引覆蓋
-
ALL 全表掃描,通常情況下性能很差,應該避免。
possible_keys,key 和 key_len
possible_key 列指出 MySQL 可能使用哪個索引在該表中查找。如果該列為 NULL,則沒有使用相關索引。需要檢查 where 子句條件來創建合適的索引提高查詢效率。
key 列显示 MySQL 實際決定使用的索引。如果沒有選擇索引,則值為 NULL。
key_len 显示 MySQL 決定使用索引的長度。如果鍵為 NULL,則本列也為 NULL,使用的索引長度,在保證精確度的情況下,越短越好。因為越短,索引文件越小,需要的 I/O次數也越少。
由上圖可以看出,對於 select * from t2 where id = 1 or val = 1這個語句,可以使用 PRIMARY 或者 idx_t2_val 索引,實際使用了 idx_t2_val 索引,索引的長度為5。
這些其實是我們分析加鎖場景最為關心的字段,後續文章會具體講解如何根據這些字段和其他工具一起判斷複雜 SQL 到底加了哪些鎖。
ref
ref 列表示使用其他表的哪個列或者常數來從表中選擇行。如下圖所示,從 t2 讀取數據時,要判斷 t2.id = t1.id,所以 ref 就是 mysql.t1.id
rows 和 filtered
rows 列显示 MySQL 認為它執行查詢時必須檢查的行數。
filtered 列表明了 SQL 語句執行后返回結果的行數占讀取行數的百分比,值越大越好。MySQL 會使用 Table Filter 來讀取出來的行數據進行過濾,理論上,讀取出來的行等於返回結果的行數時效率最高,過濾的比率越多,效率越低。
如上圖所示,t1表中有三條數據,rows 為 3,表示所有行都要讀取出來。根據 val = 3 這個 table filter 過濾,只返回一行數據,所以 filtered 比例為33.33%,
extra
包含不適合在其他列中显示但十分重要的額外信息。常見的值如下
-
using index 表示 select 操作使用了覆蓋索引,避免了訪問表的數據行,效率不錯。
-
using where 子句用於限制哪一行。也就是讀取數據后使用了 Table Filter 進行過濾。
如下圖所示,因為 id 和 val 都是有索引的,所以 select * 也是可以直接使用覆蓋索引讀取數據,所以 extra 中有 using index。而因為只使用 val 索引讀取了3行數據,還是通過 where 子句進行過濾,filtered為 55%,所以 extra 中使用了 using where。
- using filesort MySQL 會對數據使用一個外部的索引排序,而不是按照表內的索引順序進行讀取,若出現該值,應該優化 SQL 語句。如下圖所示,其中 val 列沒有索引,所以無法使用索引順序排序讀取。
-
using temporary 使用臨時表保存中間結果,比如,MySQL 在對查詢結果排序時使用臨時表,常用於 order by 和 group by,如果出現該值,應該優化 SQL。根據我的經驗,group by 一個無索引列,或者ORDER BY 或 GROUP BY 的列不是來自JOIN語句序列的第一個表,就會產生臨時表。
-
using join buffer 使用連接緩存。如下圖所示,展示了連接緩存和臨時表。關於連接緩存的內容,大家可以自行查閱,後續有時間在寫文章解釋。
- distinct 發現第一個匹配后,停止為當前的行組合搜索更多的行
後記
通過 explain 了解到 SQL 的執行計劃后,我們不僅可以了解 SQL 執行時使用的索引,判斷加鎖場景,還可以針對其他信息對 SQL 進行優化分析,比如將 type 類型從 index 優化到 ref 等。
個人博客,歡迎來玩
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?