Zookeeper分佈式過程協同技術 – 部署及設置
Zookeeper支持單機模式、偽集群模式、集群模式三種部署方式。演示部署環境為CentOS、jdk版本為1.8、Zookeeper版本為3.4.9。
單機模式
單機模式適合入門學習使用,只需要一台機器就可以輕鬆搭建Zookeeper服務用於學習和測試。
1. 進入官網下載Zookeeper的JAR包,下載地址:https://zookeeper.apache.org/releases.html。
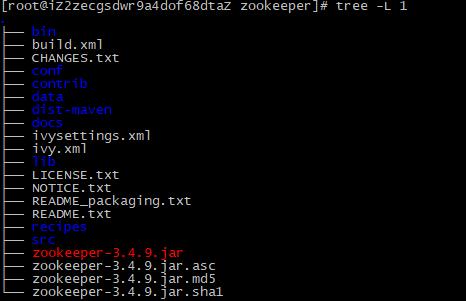
2. 解壓壓縮包,命令:tar -zxvf zookeeper-3.4.9.tar.gz,解壓后目錄格式如下。
3. 進入conf目錄,複製zoo_sample.cfg文件命名為zoo.cfg。這裏可以直接使用默認的參數,也可以根據自己的需要修改。
命令:cp zoo_sample.cfg zoo.cfg
主要配置參數說明
- clientPort
客戶端連接的服務器所監聽的TCP端口,默認情況下,服務器會監聽所有的網絡連接的這個端口,除非設置了clientPortAddress參數。客戶端口可以設置為任何值,不同的服務器可以設置不同的端口,默認端口號為2181。
- tickTime
tickTime的時長單位為毫秒,Zookeeper集群中使用的超時時間單位通過tickTime指定。tickTime設置了超時時間的下限值,因為最小的超時時間為一個tick時間,客戶端最小會話超時時間為2個tick時間。
tickTime的默認值是3000毫秒,更低的tickTime值可以更快地發現超時問題,但也導致更高的網絡流量和更高的CPU使用率。
- dataDir
dataDir用於配置內存數據庫保存的模糊快照目錄,如果某個服務器為集群中的一台,id文件也保存在該目錄下。
- dataLogDir
用於配置事務日誌的保存目錄。服務端在確認一個事務前必須將數據同步到存儲中,如果寫入磁盤過於忙碌會影響到寫入的吞吐能力。因此,比較好的方案是使用專用的日誌存儲設備,將dataLogDir目錄配置指向該設備。
- maxClientCnxns
允許每個IP地址發起socket連接的最大數量。Zookeeper通過流量控制和限制值來避免過載情況的發生。當某個IP地址的客戶端建立的連接數大於此值時,服務器會拒絕該IP地址新的連接。
- initLimit
對於追隨者最初連接到群首時的超時時間,單位為tick(tickTime)值的倍數。
當某個追隨者最初與群首建立連接時,它們之間會傳輸相當多的數據,尤其是追隨者落後整體很多時。配置initLimit參數值取決於群首與追隨者之間的網絡傳輸速度以及傳輸數據量的大小。
但是如果設置值過高,在首次連接到故障的服務器就會消耗更多的時間,同時還會消耗更多的恢復時間。因此在實際部署時,最好進行集群間的網絡基準測試來測試出你所期望的時間。
- syncLimit
對於追隨者與群首進行sync操作時的超時值,單位為tick(tickTime)值的倍數。
追隨者總是會稍落後於群首,如果群首與追隨者無法進行sync操作,而且超過了syncLimit的tick時間,就會放棄該追隨者。
- leaderServes
配置值為“yes”或“no”標誌,指示群首服務器是否為客戶端提供服務。擔任群首的服務器需要做很多工作,它需要與所有的追隨者進行通信並會執行所有的變更操作,這意味着群首的負載會比追隨者高很多,如果群首過載,整個系統都有可能受到影響。
4. 進入bin目錄,可以看到很多sh腳本文件,通過zkServer.sh來啟動zookeeper。
操作命令:
啟動命令:.zkServer.sh start
停止命令:.zkServer.sh stop
重啟命令:.zkServer.sh restart
狀態查看命令:.zkServer.sh status
啟動zookeeper服務后,通過status命令可以看到當前服務狀態、使用的配置文件、運行模式。
這樣Zookeeper的單機部署模式就已經初步完成了。如果需要修改JVM配置,可以修改zkServver.sh文件中的配置,在如下位置加入你需要的參數。
偽集群部署
偽集群部署指在一台機器上部署多個Zookeeper服務。
1. 首先將之前配置好的Zookeeper服務目錄另外複製兩份,命名為zookeeper-2和zookeeper-3。
2. 然後分別修改三份的zoo.cfg配置項,添加配置 server.x=[hostname]:n:n[:observer],示例如下。
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
Zookeeper服務器需要知道它們如何通信,配置文件中該形式的配置項就指定了服務器x的配置信息,其實x為服務器的ID值(一個整數)。當一個服務器啟動后,就會讀取data目錄下myid文件中的值,之後服務器就會使用這個值作為查找server.x項,通過該項中的數據配置服務器自己。如果需要連接到另外一個服務器y,就會使用server.y項配置信息來與這個服務器進行通信。
hostname為服務器在網絡中的名稱(ip或者主機名),同時後面跟着兩個端口號,第一個端口號用於事務的發送,第二個端口號用於群首選舉。如果最後一個字段標記了observer屬性(選填),服務器就會進入觀察者模式。
三份配置文件的myid和兩個配置端口號以及clientPort不可以重複,因為是在一台機器上部署,生產環境集群部署時可以忽略。最終的配置清單如下:
3. 分別添加myid文件,在data目錄下添加myid文件。
echo ‘1’ > data/myid
4. 分別啟動三個Zookeeper服務,啟動成功后通過status命令可以查看服務的狀態。可以看到目前集群里有一台leader和兩台follower。
集群部署
生產環境的集群部署步驟和偽集群部署並無太多差異,同樣是修改zoo.cfg配置文件並且添加Zookeeper集群信息,集群部署時,客戶端端口號、事務端口號、選舉端口號都可以保持一致。另外集群部署時需要充分考慮集群機器間的網絡情況來制定合理的超時時間設置。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案