所有知識體系文章,GitHub已收錄,歡迎Star!再次感謝,願你早日進入大廠!
GitHub地址: https://github.com/Ziphtracks/JavaLearningmanual
MySQL存儲過程
一、存儲過程
1.1 什麼是存儲過程
存儲過程(Stored Procedure)是在大型數據庫系統中,一組為了完成特定功能的SQL 語句集,它存儲在數據庫中,一次編譯后永久有效,用戶通過指定存儲過程的名字並給出參數(如果該存儲過程帶有參數)來執行它。存儲過程是數據庫中的一個重要對象。在數據量特別龐大的情況下利用存儲過程能達到倍速的效率提升
1.2 數據庫存儲過程程序
當我們了了解存儲過程是什麼之後,就需要了解數據庫中存在的這三種類型的數據庫存儲類型程序,如下:
- 存儲過程: 存儲過程是最常見的存儲程序,存儲過程是能夠接受輸入和輸出參數並且能夠在請求時被執行的程序單元。
- 存儲函數: 存儲函數和存儲過程很相像,但是它的執行結果會返回一個值。最重要的是存儲函數可以被用來充當標準的 SQL 語句,允許程序員有效的擴展 SQL 語言的能力。
- 觸發器: 觸發器是用來響應激活或者觸發數據庫行為事件的存儲程序。通常,觸發器用來作為數據庫操作語言的響應而被調用,觸發器可以被用來作為數據校驗和自動反向格式化。
注意: 其他的數據庫提供了別的數據存儲程序,包括包和類。目前MySQL不提供這種結構。
1.3 為什麼要使用存儲程序
雖然目前的開發中存儲程序我們使用的並不是很多,但是不一定就否認它。其實存儲程序會為我們使用和管理數據庫帶來了很多優勢:
- 使用存儲程序更加安全。
- 存儲程序提供了一種數據訪問的抽象機制,它能夠極大的改善你的代碼在底層數據結構演化過程中的易維護性。
- 存儲程序可以降低網絡擁阻,因為屬於數據庫服務器的內部數據,這相比在網上傳輸數據要快的多。
- 存儲程序可以替多種使用不同構架的外圍應用實現共享的訪問例程,無論這些構架是基於數據庫服務器外部還是內部。
- 以數據為中心的邏輯可以被獨立的放置於存儲程序中,這樣可以為程序員帶來更高、更為獨特的數據庫編程體驗。
- 在某些情況下,使用存儲程序可以改善應用程序的可移植性。(在另外某些情況下,可移植性也會很差!)
這裏我大致解釋一下上述幾種使用存儲程序的優勢:
我們要知道在Java語言中,我們使用數據庫與Java代碼結合持久化存儲需要引入JDBC來完成。會想到JDBC,我們是否還能想起SQL注入問題呢?雖然使用PreparedStatement解決SQL注入問題,那就真的是絕對安全嗎?不,它不是絕對安全的。
這時候分析一下數據庫與Java代碼的連接操作流程。在BS結構中,一般都是瀏覽器訪問服務器的,再由服務器發送SQL語句到數據庫,在數據庫中對SQL語句進行編譯運行,最後把結果通過服務器處理再返回瀏覽器。在此操作過程中,瀏覽器對服務器每發送一次對數據庫操作的請求就會調用對應的SQL語句編譯和執行,這是一件十分浪費性能的事情,性能下降 了就說明對數據庫的操作效率低 了。
還有一種可能是,在這個過程中進行發送傳輸的SQL語句是對真實的庫表進行操作的SQL語句,如果在發送傳輸的過程中被攔截了,一些不法分子會根據他所攔截的SQL語句推斷出我們數據庫中的庫表結構,這是一個很大的安全隱患 。
關於可維護性的提高,這裏模擬一個場景。通常數據庫在公司中是由DBA來管理的,如果管理數據庫多年的DBA辭職了,此時數據庫會被下一任DBA來管理。這裏時候問題來了,數據庫中這麼多的數據和SQL語句顯然對下一任管理者不太友好。就算管理多年的DBA長時間不操作查看數據庫也會忘記點什麼東西。所以,我們在需要引入存儲程序來進行SQL語句的統一編寫和編譯,為維護提供了便利 。(其實我覺得這個例子並不生動合理,但是為了大家能理解,請體諒!)
講了很多存儲程序的優勢演變過程,其核心就是: 需要將編譯好的一段或多段SQL語句放置在數據庫端的存儲程序中,以便解決以上問題並方便開發者直接調用。
二、存儲過程的使用步驟
2.1 存儲過程的開發思想
存儲過程時數據庫的一個重要的對象,可以封裝SQL語句集,可以用來完成一些較複雜的業務邏輯,並且可以入參(傳參)、出參(返回參數),這裏與Java中封裝方式十分相似。
而且創建時會預先編譯后保存,開發者後續的調用都不需要再次編譯。
2.2 存儲過程的優缺點
存儲過程使用的優缺點其實在1.3中的優勢中說到了。這裏我簡單羅列一下存儲過程的優點與缺點。
- 優點:
- 在生產環境下,可以通過直接修改存儲過程的方式修改業務邏輯或bug,而不用重啟服務器。
- 執行速度快,存儲過程經過編譯之後會比單獨一條一條編譯執行要快很多。
- 減少網絡傳輸流量。
- 便於開發者或DBA使用和維護。
- 在相同數據庫語法的情況下,改善了可移植性。
- 缺點:
- 過程化編程,複雜業務處理的維護成本高。
- 調試不便。
- 因為不同數據庫語法不一致,不同數據庫之間可移植性差。
2.3 MySQL存儲過程的官方文檔
英語好或者有能力的小夥伴可以去參考一下官方文檔。如果不參考官方文檔,沒關係,我在下面也會詳細講述MySQL存儲過程的各個知識點。
1https://dev.mysql.com/doc/refman/5.6/en/preface.html
2.3 存儲過程的使用語法
1create PROCEDURE 過程名( in|out|inout 參數名 數據類型 , ...)
2begin
3 sql語句;
4end;
5call 過程名(參數值);
in是定義傳入參數的關鍵字。out是定義出參的關鍵字。inout是定義一個出入參數都可以的參數。如果括號內什麼都不定義,就說明該存儲過程時一個無參的函數。在後面會有詳細的案例分析。注意: SQL語句默認的結束符為
;,所以在使用以上存儲過程時,會報1064的語法錯誤。我們可以使用DELIMITER關鍵字臨時聲明修改SQL語句的結束符為//,如下:
1-- 臨時定義結束符為"//"
2DELIMITER //
3create PROCEDURE 過程名( in|out 參數名 數據類型 , ...)
4begin
5 sql語句;
6end//
7-- 將結束符重新定義回結束符為";"
8DELIMITER ;
例如: 使用存儲過程來查詢員工的工資(無參)
注意: 如果在特殊的必要情況下,我們還可以通過delimiter關鍵字將;結束符聲明回來使用,在以下案例中我並沒有這樣將結束符聲明回原來的;,在此請大家注意~
為什麼我在這裏提供了drop(刪除)呢?
是因為我們在使用的時候如果需要修改存儲過程中的內容,我們需要先刪除現有的存儲過程后,再creat重新創建。
1# 聲明結束符為//
2delimiter //
3
4# 創建存儲過程(函數)
5create procedure se()
6begin
7 select salary from employee;
8end //
9
10# 調用函數
11call se() //
12
13# 刪除已存在存儲過程——se()函數
14drop procedure if exists se //
三、存儲過程的變量和賦值
3.1 局部變量
聲明局部變量語法:
declare var_name type [default var_value];賦值語法:
注意: 局部變量的定義,在begin/end塊中有效。
使用set為參數賦值
1# set賦值
2
3# 聲明結束符為//
4delimiter //
5
6# 創建存儲過程
7create procedure val_set()
8begin
9 # 聲明一個默認值為unknown的val_name局部變量
10 declare val_name varchar(32) default 'unknown';
11 # 為局部變量賦值
12 set val_name = 'Centi';
13 # 查詢局部變量
14 select val_name;
15end //
16
17# 調用函數
18call val_set() //
19
使用into接收參數
1delimiter //
2create procedure val_into()
3begin
4 # 定義兩個變量存放name和age
5 declare val_name varchar(32) default 'unknown';
6 declare val_age int;
7 # 查詢表中id為1的name和age並放在定義的兩個變量中
8 select name,age into val_name,val_age from employee where id = 1;
9 # 查詢兩個變量
10 select val_name,val_age;
11end //
12
13call val_into() //
14
3.2 用戶變量
用戶自定義用戶變量,當前會話(連接)有效。與Java中的成員變量相似。
- 語法:
@val_name- 注意: 該用戶變量不需要提前聲明,使用即為聲明。
1delimiter //
2create procedure val_user()
3begin
4 # 為用戶變量賦值
5 set @val_name = 'Lacy';
6end //
7
8# 調用函數
9call val_user() //
10
11# 查詢該用戶變量
12select @val_name //
3.3 會話變量
會話變量是由系統提供的,只在當前會話(連接)中有效。
語法:
@@session.val_name
1# 查看所有會話變量
2show session variables;
3# 查看指定的會話變量
4select @@session.val_name;
5# 修改指定的會話變量
6set @@session.val_name = 0;
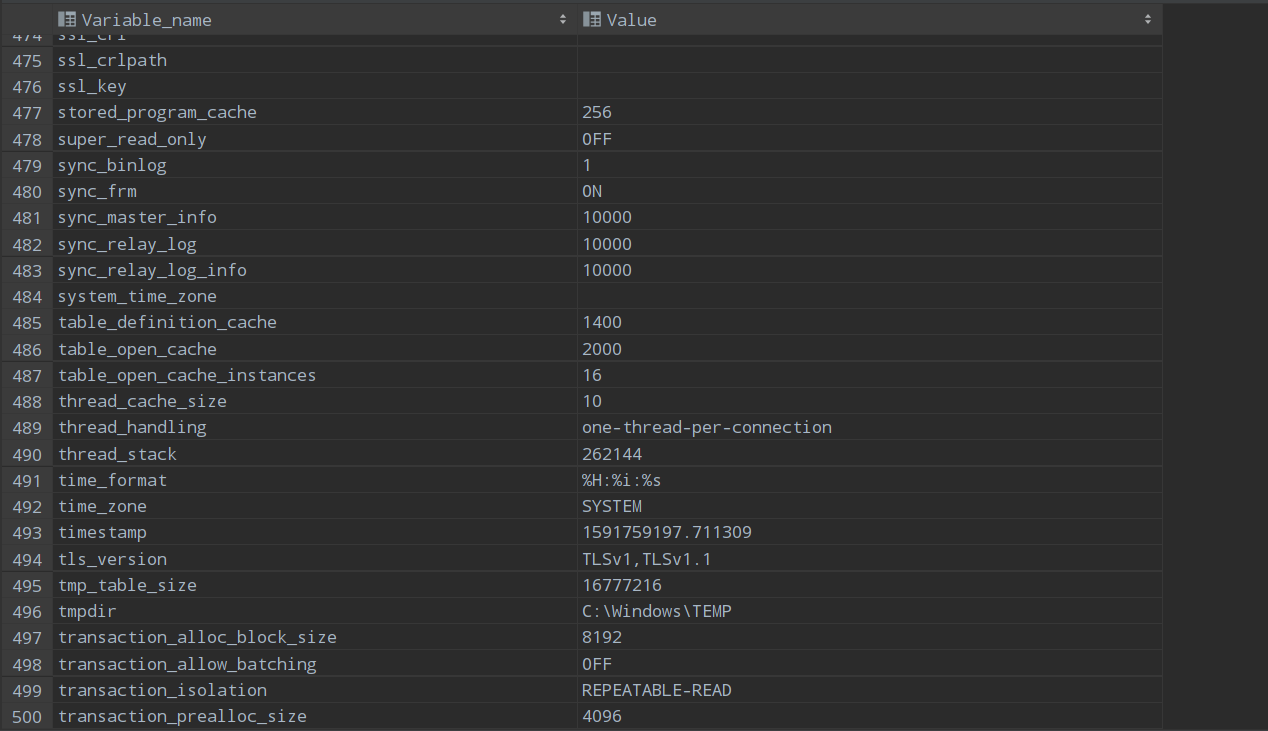
這裏我獲取了一下所有的會話變量,大概有500條會話變量的記錄。等我們深入學習MySQL后,了解了各個會話變量值的作用,可以根據需求和場景來修改會話變量值。
1delimiter //
2create procedure val_session()
3begin
4 # 查看會話變量
5 show session variables;
6end //
7
8call val_session() //
9
image-20200610112512964
3.4 全局變量
全局變量由系統提供,整個MySQL服務器內有效。
語法:
@@global.val_name
1# 查看全局變量中變量名有char的記錄
2show global variables like '%char%' //
3# 查看全局變量character_set_client的值
4select @@global.character_set_client //
3.5 入參出參
入參出參的語法我們在文章開頭已經提過了,但是沒有演示,在這裏我將演示一下入參出參的使用。
語法:
in|out|inout 參數名 數據類型 , ...
in定義出參;out定義入參;inout定義出參和入參。
出參in
使用出參in時,就是需要我們傳入參數,在這裏可以對參入的參數加以改變。簡單來說in只負責傳入參數到存儲過程中,類似Java中的形參。
1delimiter //
2create procedure val_in(in val_name varchar(32))
3begin
4 # 使用用戶變量出參(為用戶變量賦參數值)
5 set @val_name1 = val_name;
6end //
7
8# 調用函數
9call val_in('DK') //
10
11# 查詢該用戶變量
12select @val_name1 //
入參out
在使用out時,需要傳入一個參數。而這個參數相當於是返回值,可以通過調用、接收來獲取這個參數的內容。簡單來說out只負責作返回值。
1delimiter //
2# 創建一個入參和出參的存儲過程
3create procedure val_out(in val_id int,out val_name varchar(32))
4begin
5 # 傳入參數val_id查詢員工返回name值(查詢出的name值用出參接收並返回)
6 select name into val_name from employee where id = val_id;
7end //
8
9# 調用函數傳入參數並聲明傳入一個用戶變量
10call val_out(1, @n) //
11
12# 查詢用戶變量
13select @n //
入參出參inout
inout關鍵字,就是把in和out合併成了一個關鍵字使用。被關鍵字修飾的參數既可以出參也可以入參。
1delimiter //
2create procedure val_inout(in val_name varchar(32), inout val_age int)
3begin
4 # 聲明一個a變量
5 declare a int;
6 # 將傳入的參數賦值給a變量
7 set a = val_age;
8 # 通過name查詢age並返回val_age
9 select age into val_age from employee where name = val_name;
10 # 將傳入的a與-和查詢age結果字符串做拼接並查詢出來(concat——拼接字符串)
11 select concat(a, '-', val_age);
12end //
13
14# 聲明一個用戶變量並賦予參數為40
15set @ages = '40' //
16# 調用函數並傳入參數值
17call val_inout('Ziph', @ages) //
18# 執行結果
19# 40-18
四、存儲過程中的流程控制
4.1 if 條件判斷(推薦)
擴展:
timestampdiff(unit, exp1, exp2)為exp2 – exp1得到的差值,而單位是unit。(常用於日期)擴展例子:
select timestampdiff(year,’2020-6-6‘,now()) from emp e where id = 1;解釋擴展例子: 查詢員工表中id為1員工的年齡,exp2就可以為該員工的出生年月日,並以年為單位計算。
語法:
1IF 條件判斷 THEN 結果
2 [ELSEIF 條件判斷 THEN 結果] ...
3 [ELSE 結果]
4END IF
舉例: 傳入所查詢的id參數查詢工資標準(s<=6000為低工資標準;6000 =15000為高工資標準)
1delimiter //
2create procedure s_sql(in val_id int)
3begin
4 # 聲明一個局部變量result存放工資標準結果
5 declare result varchar(32);
6 # 聲明一個局部變量存放查詢得到的工資
7 declare s double;
8 # 根據入參id查詢工資
9 select salary into s from employee where id = val_id;
10 # if判斷的使用
11 if s <= 6000 then
12 set result = '低工資標準';
13 elseif s <= 10000 then
14 set result = '中工資標準';
15 elseif s <= 15000 then
16 set result = '中上工資標準';
17 else
18 set result = '高工資標準';
19 end if;
20 # 查詢工資標準結果
21 select result;
22end //
23
24# 調用函數,傳入參數
25call s_sql(1);
4.2 case條件判斷
關於case語句,不僅僅在存儲過程中可以使用,MySQL基礎查詢語句中也有用到過。相當於是Java中的switch語句。
語法:
1# 語法一
2CASE case_value
3 WHEN when_value THEN 結果
4 [WHEN when_value THEN 結果] ...
5 [ELSE 結果]
6END CASE
7
8# 語法二(推薦語法)
9CASE
10 WHEN 條件判斷 THEN 結果
11 [WHEN 條件判斷 THEN 結果] ...
12 [ELSE 結果]
13END CASE
舉例:
1# 語法一
2delimiter //
3create procedure s_case(in val_id int)
4begin
5 # 聲明一個局部變量result存放工資標準結果
6 declare result varchar(32);
7 # 聲明一個局部變量存放查詢得到的工資
8 declare s double;
9 # 根據入參id查詢工資
10 select salary into s from employee where id = val_id;
11 case s
12 when 6000 then set result = '低工資標準';
13 when 10000 then set result = '中工資標準';
14 when 15000 then set result = '中上工資標準';
15 else set result = '高工資標準';
16 end case;
17 select result;
18end //
19
20call s_case(1);
21
22# 語法二(推薦)
23delimiter //
24create procedure s_case(in val_id int)
25begin
26 # 聲明一個局部變量result存放工資標準結果
27 declare result varchar(32);
28 # 聲明一個局部變量存放查詢得到的工資
29 declare s double;
30 # 根據入參id查詢工資
31 select salary into s from employee where id = val_id;
32 case
33 when s <= 6000 then set result = '低工資標準';
34 when s <= 10000 then set result = '中工資標準';
35 when s <= 15000 then set result = '中上工資標準';
36 else set result = '高工資標準';
37 end case;
38 select result;
39end //
40
41call s_case(1);
4.3 loop循環
loop為死循環,需要手動退出循環,我們可以使用
leave來退出循環可以把leave看成Java中的break;與之對應的,就有
iterate(繼續循環)也可以看成Java的continue
語法:
1[別名:] LOOP
2 循環語句
3END LOOP [別名]
注意:別名和別名控制的是同一個標籤。
示例1: 循環打印1~10(leave控制循環的退出)
注意:該loop循環為死循環,我們查的1~10数字是i,在死循環中設置了當大於等於10時停止循環,也就是說先後執行了10次該循環內的內容,結果查詢了10次,生成了10個結果(1~10)。
1delimiter //
2create procedure s_loop()
3begin
4 # 聲明計數器
5 declare i int default 1;
6 # 開始循環
7 num:
8 loop
9 # 查詢計數器記錄的值
10 select i;
11 # 判斷大於等於停止計數
12 if i >= 10 then
13 leave num;
14 end if;
15 # 計數器自增1
16 set i = i + 1;
17 # 結束循環
18 end loop num;
19end //
20
21call s_loop();
打印結果:
image-20200610191639524
示例2: 循環打印1~10(iterate和leave控制循環)
注意:這裏我們使用字符串拼接計數器結果,而條件如果用iterate就必須時 i < 10 了!
1delimiter //
2create procedure s_loop1()
3begin
4 # 聲明變量i計數器
5 declare i int default 1;
6 # 聲明字符串容器
7 declare str varchar(256) default '1';
8 # 開始循環
9 num:
10 loop
11 # 計數器自增1
12 set i = i + 1;
13 # 字符串容器拼接計數器結果
14 set str = concat(str, '-', i);
15 # 計數器i如果小於10就繼續執行
16 if i < 10 then
17 iterate num;
18 end if;
19 # 計數器i如果大於10就停止循環
20 leave num;
21 # 停止循環
22 end loop num;
23 # 查詢字符串容器的拼接結果
24 select str;
25end //
26
27call s_loop1();
image-20200610193153512
4.4 repeat循環
repeat循環類似Java中的do while循環,直到條件不滿足才會結束循環。
語法:
1[別名:] REPEAT
2 循環語句
3UNTIL 條件
4END REPEAT [別名]
示例: 循環打印1~10
1delimiter //
2create procedure s_repeat()
3begin
4 declare i int default 1;
5 declare str varchar(256) default '1';
6 # 開始repeat循環
7 num:
8 repeat
9 set i = i + 1;
10 set str = concat(str, '-', i);
11 # until 結束條件
12 # end repeat 結束num 結束repeat循環
13 until i >= 10 end repeat num;
14 # 查詢字符串拼接結果
15 select str;
16end //
17
18call s_repeat();
4.5 while循環
while循環就與Java中的while循環很相似了。
語法:
1[別名] WHILE 條件 DO
2 循環語句
3END WHILE [別名]
示例: 循環打印1~10
1delimiter //
2create procedure s_while()
3begin
4 declare i int default 1;
5 declare str varchar(256) default '1';
6 # 開始while循環
7 num:
8 # 指定while循環結束條件
9 while i < 10 do
10 set i = i + 1;
11 set str = concat(str, '+', i);
12 # while循環結束
13 end while num;
14 # 查詢while循環拼接字符串
15 select str;
16end //
17
18call s_while();
4.6 流程控制語句(繼續、結束)
至於流程控制的繼續和結束,我們在前面已經使用過了。這裏再列舉一下。
leave:與Java中break;相似
1leave 標籤;
iterate:與Java中的continue;相似
1iterate 標籤;
五、游標與handler
5.1 游標
游標是可以得到某一個結果集並逐行處理數據。游標的逐行操作,導致了游標很少被使用!
語法:
1DECLARE 游標名 CURSOR FOR 查詢語句
2-- 打開語法
3OPEN 游標名
4-- 取值語法
5FETCH 游標名 INTO var_name [, var_name] ...
6-- 關閉語法
7CLOSE 游標名
了解了游標的語法,我們開始使用游標。如下:
示例: 使用游標查詢id、name和salary。
1delimiter //
2create procedure f()
3begin
4 declare val_id int;
5 declare val_name varchar(32);
6 declare val_salary double;
7
8 # 聲明游標
9 declare emp_flag cursor for
10 select id, name, salary from employee;
11
12 # 打開
13 open emp_flag;
14
15 # 取值
16 fetch emp_flag into val_id, val_name, val_salary;
17
18 # 關閉
19 close emp_flag;
20
21 select val_id, val_name, val_salary;
22end //
23
24call f();
執行結果:
image-20200610203622749
因為游標逐行操作的特點,導致我們只能使用游標來查詢一行記錄。怎麼改善代碼才可以實現查詢所有記錄呢?聰明的小夥伴想到了使用循環。對,我們試試使用一下循環。
1delimiter //
2create procedure f()
3begin
4 declare val_id int;
5 declare val_name varchar(32);
6 declare val_salary double;
7
8 # 聲明游標
9 declare emp_flag cursor for
10 select id, name, salary from employee;
11
12 # 打開
13 open emp_flag;
14
15 # 使用循環取值
16 c:loop
17 # 取值
18 fetch emp_flag into val_id, val_name, val_salary;
19 end loop;
20
21 # 關閉
22 close emp_flag;
23
24 select val_id, val_name, val_salary;
25end //
26
27call f();
image-20200610204034224
我們使用循環之後,發現有一個問題,因為循環是死循環,我們不加結束循環的條件,游標會一直查詢記錄,當查到沒有的記錄的時候,就會拋出異常1329:未獲取到選擇處理的行數。
如果我們想辦法指定結束循環的條件該怎麼做呢?
這時候可以聲明一個boolean類型的標記。如果為true時則查詢結果集,為false時則結束循環。
1delimiter //
2create procedure f()
3begin
4 declare val_id int;
5 declare val_name varchar(32);
6 declare val_salary double;
7
8 # 聲明flag標記
9 declare flag boolean default true;
10
11 # 聲明游標
12 declare emp_flag cursor for
13 select id, name, salary from employee;
14
15 # 打開
16 open emp_flag;
17
18 # 使用循環取值
19 c:loop
20 fetch emp_flag into val_id, val_name, val_salary;
21 # 如果標記為true則查詢結果集
22 if flag then
23 select val_id, val_name, val_salary;
24 # 如果標記為false則證明結果集查詢完畢,停止死循環
25 else
26 leave c;
27 end if;
28 end loop;
29
30 # 關閉
31 close emp_flag;
32
33 select val_id, val_name, val_salary;
34end //
35
36call f();
上述代碼你會發現並沒有寫完,它留下了一個很嚴肅的問題。當flag = false時候可以結束循環。但是什麼時候才讓flag為false啊?
於是,MySQL為我們提供了一個handler句柄。它可以幫我們解決此疑惑。
handler句柄語法:
declare continue handler for 異常 set flag = false;
handler句柄可以用來捕獲異常,也就是說在這個場景中當捕獲到1329:未獲取到選擇處理的行數時,就將flag標記的值改為false。這樣使用handler句柄就解決了結束循環的難題。讓我們來試試吧!
終極版示例: 解決了多行查詢以及結束循環問題。
1delimiter //
2create procedure f()
3begin
4 declare val_id int;
5 declare val_name varchar(32);
6 declare val_salary double;
7
8 # 聲明flag標記
9 declare flag boolean default true;
10
11 # 聲明游標
12 declare emp_flag cursor for
13 select id, name, salary from employee;
14
15 # 使用handler句柄來解決結束循環問題
16 declare continue handler for 1329 set flag = false;
17
18 # 打開
19 open emp_flag;
20
21 # 使用循環取值
22 c:loop
23 fetch emp_flag into val_id, val_name, val_salary;
24 # 如果標記為true則查詢結果集
25 if flag then
26 select val_id, val_name, val_salary;
27 # 如果標記為false則證明結果集查詢完畢,停止死循環
28 else
29 leave c;
30 end if;
31 end loop;
32
33 # 關閉
34 close emp_flag;
35
36 select val_id, val_name, val_salary;
37end //
38
39call f();
執行結果:
image-20200610210925964
在執行結果中,可以看出查詢結果以多次查詢的形式,分佈显示到了每一個查詢結果窗口中。
注意: 在語法中,變量聲明、游標聲明、handler聲明是必須按照先後順序書寫的,否則創建存儲過程出錯。
5.2 handler句柄
語法:
1DECLARE handler操作 HANDLER
2 FOR 情況列表...(比如:異常錯誤情況)
3 操作語句
注意:異常情況可以寫異常錯誤碼、異常別名或SQLSTATE碼。
handler操作:
- CONTINUE: 繼續
- EXIT: 退出
- UNDO: 撤銷
異常情況列表:
- mysql_error_code
- SQLSTATE [VALUE] sqlstate_value
- condition_name
- SQLWARNING
- NOT FOUND
- SQLEXCEPTION
注意: MySQL中各種異常情況代碼、錯誤碼、別名和SQLSTATEM碼可參考官方文檔:
https://dev.mysql.com/doc/refman/5.6/en/server-error-reference.html
寫法示例:
1 DECLARE exit HANDLER FOR SQLSTATE '3D000' set flag = false;
2 DECLARE continue HANDLER FOR 1050 set flag = false;
3 DECLARE continue HANDLER FOR not found set flag = false;
六、循環創建表
需求: 創建下個月的每天對應的表,創建的表格式為:
comp_2020_06_01、comp_2020_06_02、...描述: 我們需要用某個表記錄很多數據,比如記錄某某用戶的搜索、購買行為(注意,此處是假設用數據庫保存),當每天記錄較多時,如果把所有數據都記錄到一張表中太龐大,需要分表,我們的要求是,每天一張表,存當天的統計數據,就要求提前生產這些表——每月月底創建下一個月每天的表!
預編譯: PREPARE 數據庫對象名 FROM 參數名
執行: EXECUTE 數據庫對象名 [USING @var_name [, @var_name] ...]
通過數據庫對象創建或刪除表: {DEALLOCATE | DROP} PREPARE 數據庫對象名
關於時間處理的語句:
1-- EXTRACT(unit FROM date) 截取時間的指定位置值
2-- DATE_ADD(date,INTERVAL expr unit) 日期運算
3-- LAST_DAY(date) 獲取日期的最後一天
4-- YEAR(date) 返回日期中的年
5-- MONTH(date) 返回日期的月
6-- DAYOFMONTH(date) 返回日
代碼:
1-- 思路:循環構建表名 comp_2020_06_01 到 comp_2020_06_30;並執行create語句。
2delimiter //
3create procedure sp_create_table()
4begin
5 # 聲明需要拼接表名的下一個月的年、月、日
6 declare next_year int;
7 declare next_month int;
8 declare next_month_day int;
9
10 # 聲明下一個月的月和日的字符串
11 declare next_month_str char(2);
12 declare next_month_day_str char(2);
13
14 # 聲明需要處理每天的表名
15 declare table_name_str char(10);
16
17 # 聲明需要拼接的1
18 declare t_index int default 1;
19 # declare create_table_sql varchar(200);
20
21 # 獲取下個月的年份
22 set next_year = year(date_add(now(),INTERVAL 1 month));
23 # 獲取下個月是幾月
24 set next_month = month(date_add(now(),INTERVAL 1 month));
25 # 下個月最後一天是幾號
26 set next_month_day = dayofmonth(LAST_DAY(date_add(now(),INTERVAL 1 month)));
27
28 # 如果下一個月月份小於10,就在月份的前面拼接一個0
29 if next_month < 10
30 then set next_month_str = concat('0',next_month);
31 else
32 # 如果月份大於10,不做任何操作
33 set next_month_str = concat('',next_month);
34 end if;
35
36 # 循環操作(下個月的日大於等於1循環開始循環)
37 while t_index <= next_month_day do
38
39 # 如果t_index小於10就在前面拼接0
40 if (t_index < 10)
41 then set next_month_day_str = concat('0',t_index);
42 else
43 # 如果t_index大於10不做任何操作
44 set next_month_day_str = concat('',t_index);
45 end if;
46
47 # 拼接標命字符串
48 set table_name_str = concat(next_year,'_',next_month_str,'_',next_month_day_str);
49 # 拼接create sql語句
50 set @create_table_sql = concat(
51 'create table comp_',
52 table_name_str,
53 '(`grade` INT(11) NULL,`losal` INT(11) NULL,`hisal` INT(11) NULL) COLLATE=\'utf8_general_ci\' ENGINE=InnoDB');
54 # 預編譯
55 # 注意:FROM後面不能使用局部變量!
56 prepare create_table_stmt FROM @create_table_sql;
57 # 執行
58 execute create_table_stmt;
59 # 創建表
60 DEALLOCATE prepare create_table_stmt;
61
62 # t_index自增1
63 set t_index = t_index + 1;
64
65 end while;
66end//
67
68# 調用函數
69call sp_create_table()
七、其他
7.1 characteristic
在MySQL存儲過程中,如果沒有显示的定義characteristic,它會隱式的定義一系列特性的默認值來創建存儲過程。
LANGUAGE SQL
存儲過程語言,默認是sql,說明存儲過程中使用的是sql語言編寫的,暫時只支持sql,後續可能會支持其他語言
NOT DETERMINISTIC
是否確定性的輸入就是確定性的輸出,默認是NOT DETERMINISTIC,只對於同樣的輸入,輸出也是一樣的,當前這個值還沒有使用
CONTAINS SQL
提供子程序使用數據的內在信息,這些特徵值目前提供給服務器,並沒有根據這些特徵值來約束過程實際使用數據的情況。有以下選擇:
- CONTAINS SQL表示子程序不包含讀或者寫數據的語句
- NO SQL 表示子程序不包含sql
- READS SQL DATA 表示子程序包含讀數據的語句,但是不包含寫數據的語句
- MODIFIES SQL DATA 表示子程序包含寫數據的語句。
SQL SECURITY DEFINER
MySQL存儲過程是通過指定SQL SECURITY子句指定執行存儲過程的實際用戶。所以次值用來指定存儲過程是使用創建者的許可來執行,還是執行者的許可來執行,默認值是DEFINER
- DEFINER 創建者的身份來調用,對於當前用戶來說:如果執行存儲過程的權限,且創建者有訪問表的權限,當前用戶可以成功執行過程的調用的
- INVOKER 調用者的身份來執行,對於當前用戶來說:如果執行存儲過程的權限,以當前身份去訪問表,如果當前身份沒有訪問表的權限,即便是有執行過程的權限,仍然是無法成功執行過程的調用的。
COMMENT ”
存儲過程的註釋性信息寫在COMMENT裏面,這裏只能是單行文本,多行文本會被移除到回車換行等
7.2 死循環處理
如有死循環處理,可以通過下面的命令查看並殺死(結束)
1show processlist;
2kill id;
7.3 select語句中書寫case
1select
2 case
3 when 條件判斷 then 結果
4 when 條件判斷 then 結果
5 else 結果
6 end 別名,
7 *
8from 表名;
7.4 複製表和數據
1CREATE TABLE dept SELECT * FROM procedure_demo.dept;
2CREATE TABLE emp SELECT * FROM procedure_demo.emp;
3CREATE TABLE salgrade SELECT * FROM procedure_demo.salgrade;
7.5 臨時表
1create temporary table 表名(
2 字段名 類型 [約束],
3 name varchar(20)
4)Engine=InnoDB default charset utf8;
5
6-- 需求:按照部門名稱查詢員工,通過select查看員工的編號、姓名、薪資。(注意,此處僅僅演示游標用法)
7delimiter $$
8create procedure sp_create_table02(in dept_name varchar(32))
9begin
10 declare emp_no int;
11 declare emp_name varchar(32);
12 declare emp_sal decimal(7,2);
13 declare exit_flag int default 0;
14
15 declare emp_cursor cursor for
16 select e.empno,e.ename,e.sal
17 from emp e inner join dept d on e.deptno = d.deptno where d.dname = dept_name;
18
19 declare continue handler for not found set exit_flag = 1;
20
21 -- 創建臨時表收集數據
22 CREATE temporary TABLE `temp_table_emp` (
23 `empno` INT(11) NOT NULL COMMENT '員工編號',
24 `ename` VARCHAR(32) NULL COMMENT '員工姓名' COLLATE 'utf8_general_ci',
25 `sal` DECIMAL(7,2) NOT NULL DEFAULT '0.00' COMMENT '薪資',
26 PRIMARY KEY (`empno`) USING BTREE
27 )
28 COLLATE='utf8_general_ci'
29 ENGINE=InnoDB;
30
31 open emp_cursor;
32
33 c_loop:loop
34 fetch emp_cursor into emp_no,emp_name,emp_sal;
35
36
37 if exit_flag != 1 then
38 insert into temp_table_emp values(emp_no,emp_name,emp_sal);
39 else
40 leave c_loop;
41 end if;
42
43 end loop c_loop;
44
45 select * from temp_table_emp;
46
47 select @sex_res; -- 僅僅是看一下會不會執行到
48 close emp_cursor;
49
50end$$
51
52call sp_create_table02('RESEARCH');
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準