目的
本文主要介紹的內容有以下三點:
一. Elastic Stack是什麼以及組成部分
二. Elastic Stack前景以及業務應用
三. Elasticsearch原理(索引方向)
四. Elasticsearch相對薄弱的地方
一、Elastic Stack是什麼以及組成部分
介紹Elastic Stack是什麼,其實只要一句話就可以,就是: 一套完整的大數據處理堆棧,從攝入、轉換到存儲分析、可視化。
它是不同產品的集合,各司其職,形成完整的數據處理鏈,因此Elastic Stack也可以簡稱為BLEK。
Beats 輕量型數據採集器
Logstash 輸入、過濾器和輸出
Elasticsearch 查詢和分析
Kibana 可視化,可自由選擇如何呈現數據
1. Beats – 全品類採集器,搞定所有數據類型
Filebeat(日誌文件):對成百上千、甚至上萬的服務器生成的日誌匯總,可搜索。
Metricbeat(指標): 收集系統和服務指標,CPU 使用率、內存、文件系統、磁盤 IO 和網絡 IO 統計數據。
Packetbeat(網絡數據):網絡數據包分析器,了解應用程序動態。
Heartbeat(運行時間監控):通過主動探測來監測服務的可用性
……
Beats支持許許多多的beat,這裏列的都是比較的常用的beat,了解更多可以點擊鏈接:
2. Logstash – 服務器端數據處理管道
介紹Logstash之前,我們先來看下Linux下常用的幾個命令
cat alldata.txt | awk ‘{print $1}’ | sort | uniq | tee filterdata.txt
只要接觸過Linux同學,應該都知道這幾個命名意思
cat alldata.txt #將alldata.txt的內容輸出到標準設備上
awk ‘{print $1}’ #對上面的內容做截取,只取每一行第一列數據
sort | uniq #對截取后的內容,進行排序和唯一性操作
tee filterdata.txt #將上面的內容寫到filterdata.txt
上面的幾個簡單的命令就可以看出來,這是對數據進行了常規的處理,用名詞修飾的話就是:數據獲取/輸入、數據清洗、數據過濾、數據寫入/輸出
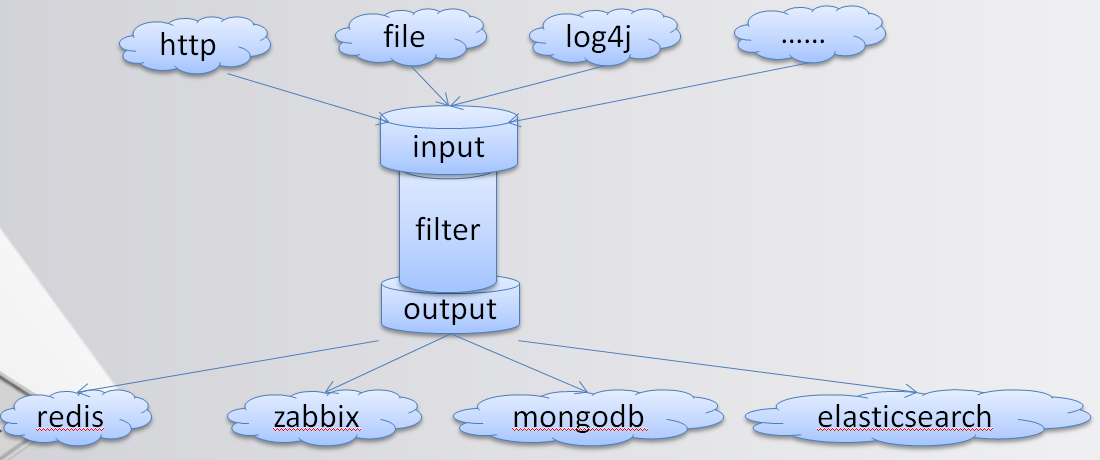
而Logstash做的也是相同的事(看下圖)。
將系統的日誌文件、應用日誌文件、系統指標等數據,輸入到Input,再通過數據清洗以及過濾,輸入到存儲設備中,這裏當然是輸入到Elasticsearch
3. Elasticsearch – 分佈式文檔存儲、RESTful風格的搜索和數據分析引擎
Elasticsearch主要也是最原始的功能就是搜索和分析功能。這裏就簡單說一下,下面講原理的時候會着重講到Elasticsearch
搜索:全文搜索,完整的信息源轉化為計算機可以識別、處理的信息單元形成的數據集合 。
分析:相關度,搜索所有內容,找到所需的具體信息(詞頻或熱度等對結果排序)
4. Kibana- 可視化
可視化看下圖(來源官網)便知
可以對日誌分析、業務分析等做可視化
現在從總體上來了解下,在心中對Elastic Stack有個清楚的認知(下圖)。
二、Elastic Stack前景以及業務應用
1. DB-Engines 排名
Elasticsearch是Elastic Stack核心,由圖可以看出在搜索領域Elasticsearch暫時沒有對手。
2. ES社區
ES中文社區也是相當活躍的,會定期做一下分享,都是大公司的寶貴經驗,值得參考。
3. 2018年攜程的使用情況(讓我們看看能處理多大的數據)
集群數量是94個,最小的集群一般是3個節點。全部節點數量大概700+。
最大的一個集群是做日誌分析的,其中數據節點330個,最高峰一天產生1600億文檔,寫入值300w/s。
現在有2.5萬億文檔,大概是幾個PB的量
三、Elasticsearch(ES)原理
因為篇目有限,本篇只介紹ES的索引原理。
ES為什麼可以做全文搜索,主要就是用了倒排索引,先來看下面的一張圖
看圖可以簡單的理解倒排索引就是:關鍵字 + 頁碼
對倒排索引有個基本的認識后,下面來做個簡單的數據例子。
現在對Name做到排索引,記住:關鍵字 + ID(頁碼)。
對Age做到排索引。
對Intersets做到排索引。
現在搜索Age等於18的,通過倒排索引就可以快速得到1和3的id,再通過id就可以得到具體數據,看,這樣是不是快的狠。
如果是用Mysql等關係數據庫,現在有十多億數據(大數據嘛),就要一條一條的掃描下去找id,效率可想而知。而用倒排索引,找到所有的id就輕輕鬆鬆了。
在ES中,關鍵詞叫Term,頁碼叫Posting List。
但這樣就行了嗎? 如果Name有上億個Term,要找最後一個Term,效率豈不是還是很低?
再來看Name的倒排索引,你會發現,將Armani放在了第一個,Tyloo放在了第三個,可以看出來,對Term做了簡單的排序。雖然簡單,但很實用。這樣查找Term就可以用二分查找法來查找了,將複雜度由n變成了logn。
在ES中,這叫Term Dictionary。
到這裏,再來想想MySQL的b+tree, 你有沒有發現原理是差不多的,那為什麼說ES搜索比MySQL快很多,究竟快在哪裡? 接下來再看。
有一種數據結構叫Trie樹,又稱前綴樹或字典樹,是一種有序樹。這種數據結構的好處就是可以壓縮前綴和提高查詢數據。
現在有這麼一組Term: apps, apple, apply, appear, back, backup, base, bear,用Trie樹表示如下圖。
通過線路路徑字符連接就可以得到完成的Term,並且合用了前綴,比如apps, apple, apply, appear合用了app路徑,節省了大量空間。
這個時候再來找base單詞,立即就可以排除了a字符開頭的單詞,比Term Dictionary快了不知多少。
在ES中,這叫Term Index
現在我們再從整體看下ES的索引
先通過Trie樹快速定位block(相當於頁碼), 再到Term Dictionary 做二分查找,得到Posting List。
索引優化
ES是為了大數據而生的,這意味着ES要處理大量的數據,它的Term數據量也是不可想象的。比如一篇文章,要做全文索引,就會對全篇的內容做分詞,會產生大量的Term,而ES查詢的時候,這些Term肯定要放在內存裏面的。
雖然Trie樹對前綴做了壓縮,但在大量Term面前還是不夠,會佔用大量的內存使用,於是就有ES對Trie樹進一步演化。
FST(Finite State Transducer )確定無環有限狀態轉移器 (看下圖)
可以看appear、bear 對共同的後綴做了壓縮。
Posting List磁盤壓縮
假設有一億的用戶數據,現在對性別做搜索,而性別無非兩種,可能”男”就有五千萬之多,按int4個字節存儲,就要消耗50M左右的磁盤空間,而這僅僅是其中一個Term。
那麼面對成千上萬的Term,ES究竟是怎麼存儲的呢?接下來,就來看看ES的壓縮方法。
Frame Of Reference (FOR) 增量編碼壓縮,將大數變小數,按字節存儲
只要能把握“增量,大數變小數,按字節存儲”這幾個關鍵詞,這個算法就很好理解,現在來具體看看。
現在有一組Posting List:[60, 150, 300,310, 315, 340], 按正常的int型存儲,size = 6 * 4(24)個字節。
-
按增量存儲:60 + 90(150)+ 150(300) + 10(310) + 5(315)+ 25(340),也就是[60, 90, 150, 10, 5, 25],這樣就將大數變成了小數。
-
切分成不同的block:[60, 90, 150]、[10, 5, 25],為什麼要切分,下面講。
-
按字節存儲:對於[60, 90, 150]這組block,究竟怎麼按字節存儲,其實很簡單,就是找其中最大的一個值,看X個比特能表示這個最大的數,那麼剩下的數也用X個比特表示(切分,可以盡可能的壓縮空間)。
[60, 90, 150]最大數150 < 2^8 = 256,也就是這組每個數都用8個比特表示,也就是 3*8 = 24個比特,再除以8,也就是3個字節存在,再加上一個8的標識位(說明每個數是8個比特存儲),佔用一個字節,一共4個字節。
[10, 5, 25]最大數25 < 2^5 = 32,每個數用5個比特表示,3*5=15比特,除以8,大約2個字節,加上5的標識位,一共3個字節。
那麼總體size = 4 + 3(7)個字節,相當於24個字節,大大壓縮了空間。
再看下圖表示
Posting List內存壓縮
同學們應該都知道越複雜的算法消耗的CPU性能就越大,比如常見的https,第一次交互會用非對稱密碼來驗證,驗證通過後就轉變成了對稱密碼驗證,FOR同樣如此,那麼ES是用什麼算法壓縮內存中的Posting List呢?
Roaring Bitmaps 壓縮位圖索引
Roaring Bitmaps 涉及到兩種數據結構 short[] 、bitmap。
short好理解就是2個字節的整型。
bitmap就是用比特表示數據,看下面的例子。
Posting List:[1, 2, 4, 7, 10] -> [1, 1, 0, 1, 0, 0, 1,0, 0, 1],取最大的值10,那麼就用10個比特表示這組Posting List,第1, 2, 4, 7, 10位存在,就將相對應的“位”置為1,其他的為0。
但這種bitmap數據結構有缺陷,看這組Posting List: [1, 3, 100000000] -> [1, 0, 1, 0, 0, 0, …, 0, 0, 1 ],最大數是1億,就要1億的比特表示,這麼算下來,反而消耗了更多的內存。
那如何解決這個問題,其實也很簡單,跟上面一樣,將大數變成小數。
看下圖:
第一步:將每個數除以65536,得到(商,餘數)。
第二步:按照商,分成不同的block,也就是相同的商,放在同一個block裏面,餘數就是這個值在這個block裏面的位置(永遠不會超過65536,餘數嘛)。
第三步:判斷底層block用什麼數據結構存儲數據,如果block裏面的餘數的個數超過4096個,就用short存儲,反之bitmap。
上面那個圖是官網的圖,看下我畫的圖,可能更好理解些。
到這裏,ES的索引原理就講完了,希望大家都能理解。
四、Elasticsearch(ES)相對薄弱的地方
1. 多表關聯
其實ES有一個很重要的特性這裏沒有介紹到,也就是分佈式,每一個節點的數據和,才是整體數據。
這也導致了多表關聯問題,雖然ES裏面也提供了Nested& Join 方法解決這個問題,但這裏還是不建議用。
那這個問題在實際應用中應該如何解決? 其實也很簡單,裝換思路,ES無法解決,就到其他層解決,比如:應用層,用面向對象的架構,拆分查詢。
2. 深度分頁
分佈式架構下,取數據便不是那麼簡單,比如取前1000條數據,如果是10個節點,那麼每個節點都要取1000條,10個節點就是10000條,排序后,返回前1000條,如果是深度分頁就會變的相當的慢。
ES提供的是Scroll + Scroll_after,但這個採取的是緩存的方式,取出10000條后,緩存在內存里,再來翻頁的時候,直接從緩存中取,這就代表着存在實時性問題。
來看看百度是怎麼解決這個問題的。
一樣在應用層解決,翻頁到一定的深度后,禁止翻頁。
3. 更新應用
頻繁更新的應用,用ES會有瓶頸,比如一些遊戲應用,要不斷的更新數據,用ES不是太適合,這個看大家自己的應用情況。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!