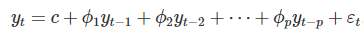
單例模式,大家恐怕再熟悉不過了,其作用與實現方式有多種,這裏就不啰嗦了。但是,咱們在使用這些方式實現單例模式時,程序中就真的會只有一個實例嗎?
聰明的你看到這樣的問話,一定猜到了答案是NO。這裏筆者就不賣關子了,開門見山吧!實際上,在有些場景下,如果程序處理不當,會無情地破壞掉單例模式,導致程序中出現多個實例對象。
下面筆者介紹筆者已知的三種破壞單例模式的方式以及避免方法。
1、反射對單例模式的破壞
我們先通過一個例子,來直觀感受一下
(1)案例
DCL實現的單例模式:
1 public class Singleton{ 2 private static volatile Singleton mInstance; 3 private Singleton(){} 4 public static Singleton getInstance(){ 5 if(mInstance == null){ 6 synchronized (Singleton.class) { 7 if(mInstance == null){ 8 mInstance = new Singleton(); 9 } 10 } 11 } 12 return mInstance; 13 } 14 }
測試代碼:
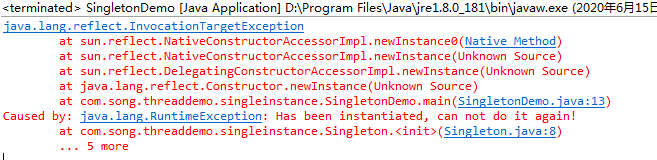
1 public class SingletonDemo { 2 3 public static void main(String[] args){ 4 Singleton singleton = Singleton.getInstance(); 5 try { 6 Constructor<Singleton> constructor = Singleton.class.getDeclaredConstructor(); 7 constructor.setAccessible(true); 8 Singleton reflectSingleton = constructor.newInstance(); 9 System.out.println(reflectSingleton == singleton); 10 } catch (Exception e) { 11 // TODO Auto-generated catch block 12 e.printStackTrace(); 13 } 14 } 15 }
執行結果:
false
運行結果說明,採用反射的方式另闢蹊徑實例了該類,導致程序中會存在不止一個實例。
(2)解決方案
其思想就是採用一個全局變量,來標記是否已經實例化過了,如果已經實例化過了,第二次實例化的時候,拋出異常。實現代碼如下:
1 public class Singleton{ 2 private static volatile Singleton mInstance; 3 private static volatile boolean mIsInstantiated = false; 4 private Singleton(){ 5 if (mIsInstantiated){ 6 throw new RuntimeException("Has been instantiated, can not do it again!"); 7 } 8 mIsInstantiated = true; 9 } 10 public static Singleton getInstance(){ 11 if(mInstance == null){ 12 synchronized (Singleton.class) { 13 if(mInstance == null){ 14 mInstance = new Singleton(); 15 } 16 } 17 } 18 return mInstance; 19 } 20 }
執行結果:
這種方式看起來比較暴力,運行時直接拋出異常。
2、clone()對單例模式的破壞
當需要實現單例的類允許clone()時,如果處理不當,也會導致程序中出現不止一個實例。
(1)案例
一個實現了Cloneable接口單例類:
1 public class Singleton implements Cloneable{ 2 private static volatile Singleton mInstance; 3 private Singleton(){ 4 } 5 public static Singleton getInstance(){ 6 if(mInstance == null){ 7 synchronized (Singleton.class) { 8 if(mInstance == null){ 9 mInstance = new Singleton(); 10 } 11 } 12 } 13 return mInstance; 14 } 15 @Override 16 protected Object clone() throws CloneNotSupportedException { 17 // TODO Auto-generated method stub 18 return super.clone(); 19 } 20 }
測試代碼:
1 public class SingletonDemo { 2 3 public static void main(String[] args){ 4 try { 5 Singleton singleton = Singleton.getInstance(); 6 Singleton cloneSingleton; 7 cloneSingleton = (Singleton) Singleton.getInstance().clone(); 8 System.out.println(cloneSingleton == singleton); 9 } catch (CloneNotSupportedException e) { 10 e.printStackTrace(); 11 } 12 } 13 }
執行結果:
false
(2)解決方案:
解決思想是,重寫clone()方法,調clone()時直接返回已經實例的對象
1 public class Singleton implements Cloneable{ 2 private static volatile Singleton mInstance; 3 private Singleton(){ 4 } 5 public static Singleton getInstance(){ 6 if(mInstance == null){ 7 synchronized (Singleton.class) { 8 if(mInstance == null){ 9 mInstance = new Singleton(); 10 } 11 } 12 } 13 return mInstance; 14 } 15 @Override 16 protected Object clone() throws CloneNotSupportedException { 17 return mInstance; 18 } 19 }
執行結果:
true
3、序列化對單例模式的破壞
在使用序列化/反序列化時,也會出現產生新實例對象的情況。
(1)案例
一個實現了序列化接口的單例類:
1 public class Singleton implements Serializable{ 2 private static volatile Singleton mInstance; 3 private Singleton(){ 4 } 5 public static Singleton getInstance(){ 6 if(mInstance == null){ 7 synchronized (Singleton.class) { 8 if(mInstance == null){ 9 mInstance = new Singleton(); 10 } 11 } 12 } 13 return mInstance; 14 } 15 }
測試代碼:
1 public class SingletonDemo { 2 3 public static void main(String[] args){ 4 try { 5 Singleton singleton = Singleton.getInstance(); 6 FileOutputStream fos = new FileOutputStream("singleton.txt"); 7 ObjectOutputStream oos = new ObjectOutputStream(fos); 8 oos.writeObject(singleton); 9 oos.close(); 10 fos.close(); 11 12 FileInputStream fis = new FileInputStream("singleton.txt"); 13 ObjectInputStream ois = new ObjectInputStream(fis); 14 Singleton serializedSingleton = (Singleton) ois.readObject(); 15 fis.close(); 16 ois.close(); 17 System.out.println(serializedSingleton==singleton); 18 } catch (Exception e) { 19 e.printStackTrace(); 20 } 21 22 } 23 }
運行結果:
false
(2)解決方案
在反序列化時的回調方法 readResolve()中返回單例對象。
1 public class Singleton implements Serializable{ 2 private static volatile Singleton mInstance; 3 private Singleton(){ 4 } 5 public static Singleton getInstance(){ 6 if(mInstance == null){ 7 synchronized (Singleton.class) { 8 if(mInstance == null){ 9 mInstance = new Singleton(); 10 } 11 } 12 } 13 return mInstance; 14 } 15 16 protected Object readResolve() throws ObjectStreamException{ 17 return mInstance; 18 } 19 }
結果:
true
以上就是筆者目前已知的三種可以破壞單例模式的場景以及對應的解決辦法,讀者如果知道還有其他的場景,記得一定要分享出來噢,正所謂“獨樂樂不如眾樂樂”!!!
單例模式看起來是設計模式中最簡單的一個,但“麻雀雖小,五臟俱全”,其中有很多細節都是值得深究的。即便是本篇介紹的這幾個場景,也只是介紹了一些梗概而已,很多細節還需要讀者自己去試驗和推敲的,比如:通過枚舉方式實現單例模式,就不存在上述問題,而其它的實現方式似乎都存在上述問題!
後記
本篇參(剽)考(竊)了如下資料:
高洪岩的《Java 多線程編程核心技術》
博文:https://blog.csdn.net/fd2025/article/details/79711198
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化