題外話:本來不想解釋、可是看完評論,有點服氣。沒想到居然這麼多人能曲解題意。這篇文章明顯是在說,不要寫一大堆if-else,一大堆是啥意思很難懂嗎?我沒有一句話說了不要寫if-else。開頭也給出了具體需求,在這種需求的前提下不要寫if-else,沒毛病吧??
代碼潔癖狂們!看到一個類中有幾十個if-else是不是很抓狂?
設計模式學了用不上嗎?面試的時候問你,你只能回答最簡單的單例模式,問你有沒有用過反射之類的高級特性,回答也是否嗎?
這次就讓設計模式(模板方法模式+工廠模式)和反射助你消滅if-else!
真的是開發中超超超超超超有用的乾貨啊!
那個坑貨
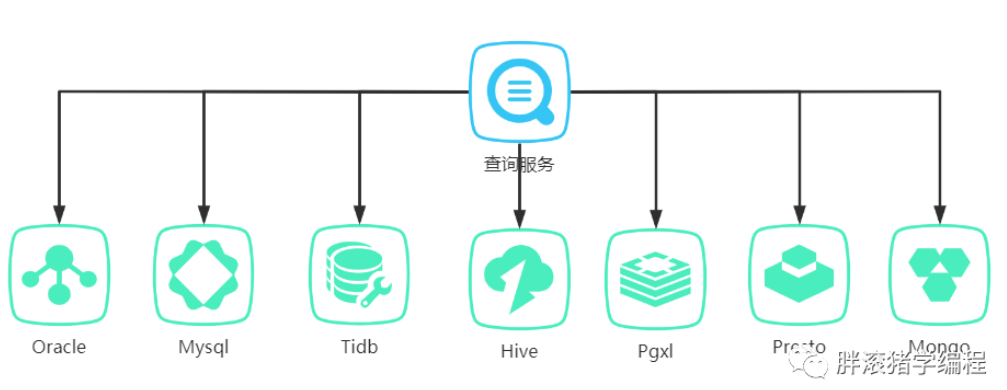
某日,碼農胖滾豬接到上級一個需求,這個需求牛逼了,一站式智能報表查詢平台,支持mysql、pgxl、tidb、hive、presto、mongo等眾多數據源,想要啥數據都能通通給你查出來展示,對於業務人員數據分析有重大意義!
雖然各個數據源的參數校驗、查詢引擎和查詢邏輯都不一樣,但是胖滾豬對這些框架都很熟悉,這個難不倒她,她只花了一天時間就都寫完了。
領導胖滾熊也對胖滾豬的效率表示了肯定。可是好景不長,第三天,領導閑着沒事,準備做一下code review,可把胖滾熊驚呆了,一個類裏面有近30個if-else代碼,我滴個媽呀,這可讓代碼潔癖狂崩潰了。
// 檢驗入參合法性
Boolean check = false;
if(DataSourceEnum.hive.equals(dataSource)){
check = checkHiveParams(params);
} else if(DataSourceEnum.tidb.equals(dataSource)){
check = checkTidbParams(params);
} else if(DataSourceEnum.mysql.equals(dataSource)){
check = checkMysqlParams(params);
} // else if ....... 省略pgxl、presto等
if(check){
if(DataSourceEnum.hive.equals(dataSource)){
list = queryHive(params);
} else if(DataSourceEnum.tidb.equals(dataSource)){
list = queryTidb(params);
} else if(DataSourceEnum.mysql.equals(dataSource)){
list = queryMysql(params);
} // else if ....... 省略pgxl、presto等
}
//記錄日誌
log.info("用戶={} 查詢數據源={} 結果size={}",params.getUserName(),params.getDataSource(),list.size());
模板模式來救場
首先我們來分析下,不管是什麼數據源,算法結構(流程)都是一樣的,1、校驗參數合法性 2、查詢 3、記錄日誌。這不就是說模板一樣、只不過具體細節不一樣,沒錯吧?
讓我們來看看設計模式中模板方法模式的定義吧:
模板方法模式:定義一個操作中的算法的框架,而將一些步驟延遲到子類中. 使得子類可以不改變一個算法的結構即可重定義該算法的某些特定步驟。通俗的講,就是將子類相同的方法, 都放到其抽象父類中。
我們這需求不就和模板方法模式差不多嗎?因此我們可以把模板抽到父類(抽象類)中。至於特定的步驟實現不一樣,這些特殊步驟,由子類去重寫就好了。
廢話不多說了,我們先把父類模板寫好吧,完全一樣的邏輯是記錄日誌,這步在模板寫死就好。至於檢驗參數和查詢,這兩個方法各不相同,因此需要置為抽象方法,由子類去重寫。
public abstract class AbstractDataSourceProcesser <T extends QueryInputDomain> {
public List<HashMap> query(T params){
List<HashMap> list = new ArrayList<>();
//檢驗參數合法性 不同的引擎sql校驗邏輯不一樣
Boolean b = checkParam(params);
if(b){
//查詢
list = queryData(params);
}
//記錄日誌
log.info("用戶={} 查詢數據源={} 結果size={}",params.getUserName(),params.getDataSource(),list.size());
return list;
}
//抽象方法 由子類來實現特定邏輯
abstract Boolean checkParam(T params);
abstract List<HashMap> queryData(T params);
}
這段代碼非常簡單。但是為了照顧新手,還是想解釋一個東西:
T這個玩意。叫泛型,因為不同數據源的入參不一樣,所以我們使用泛型。但是他們也有公共的參數,比如用戶名。因此為了不重複冗餘,更好的利用公共資源,在泛型的設計上,我們可以有一個泛型上限,<T extends QueryInputDomain>
public class QueryInputDomain<T> {
public String userName;//查詢用戶名
public String dataSource;//查詢數據源 比如mysql\tidb等
public T params;//特定的參數 不同的數據源參數一般不一樣
}
public class MysqlQueryInput extends QueryInputDomain{
private String database;//數據庫
public String sql;//sql
}
接下來就輪到子類出場了,通過上面的分析,其實也很簡單了,不過是繼承父類,重寫checkParam()和queryData()方法,下面以mysql數據源為例,其他數據源也都一樣的套路:
@Component("dataSourceProcessor#mysql")
public class MysqlProcesser extends AbstractDataSourceProcesser<MysqlQueryInput>{
@Override
public Boolean checkParam(MysqlQueryInput params) {
System.out.println("檢驗mysql參數是否準確");
return true;
}
@Override
public List<HashMap> queryData(MysqlQueryInput params) {
List<HashMap> list = new ArrayList<>();
System.out.println("開始查詢mysql數據");
return list;
}
}
這樣一來,所有的數據源,都自成一體,擁有一個只屬於自己的類,後續要擴展數據源、或者要修改某個數據源的邏輯,都非常方便和清晰了。
說實話,模板方法模式太簡單了,抽象類這東西也太基礎普遍了,一般應屆生都會知道的。但是對於初入職場的新人來說,還真不太能果斷應用在實際生產中。因此提醒各位:一定要有一個抽象思維,避免代碼冗餘重複。
另外,要再啰嗦幾句,即使工作有幾年的工程師也很容易犯一個錯誤。就是把思維局限在今天的需求,比如老闆一開始只給你一個mysql數據源查詢的需求,壓根沒有if-else,可能你就不會放在心上,直接在一個類中寫死,不會考慮到後續的擴展。直到後面越來越多的新需求,你才恍然大悟,要全部重構一番,這樣浪費自己的時間了。因此提醒各位:做需求不要局限於今天,要考慮到未來。 從一開始就做到高擴展性,後續需求變更和維護就非常爽了。
原創聲明:本文為【胖滾豬學編程】原創博文,轉載請註明出處。以漫畫形式讓編程生動有趣!原創不易,求關注!
工廠模式來救場
但是模板模式還是沒有完全解決胖滾豬的if-else,因為需要根據傳進來的dataSource參數,判斷由哪個service來實現查詢邏輯,現在是這麼寫的:
if(DataSourceEnum.hive.equals(dataSource)){
list = queryHive(params);
} else if(DataSourceEnum.tidb.equals(dataSource)){
list = queryTidb(params);
}
那麼這種if-else應該怎麼去幹掉呢?我想先跟你講講工廠模式的那些故事。
工廠模式:工廠方法模式是一種創建對象的模式,它被廣泛應用在jdk中以及Spring和Struts框架中。它將創建對象的工作轉移到了工廠類。
為了呼應一下工廠兩字,我特意舉一個代工廠的例子讓你理解,這樣你應該會有更深刻的印象。
以手機製造業為例。我們知道有蘋果手機、小米手機等等,每種品牌的手機製造方法必然不相同,我們可以先定義好一個手機標準接口,這個接口有make()方法,然後不同型號的手機都繼承這個接口:
#Phone類:手機標準規範類(AbstractProduct)
public interface Phone {
void make();
}
#MiPhone類:製造小米手機(Product1)
public class MiPhone implements Phone {
public MiPhone() {
this.make();
}
@Override
public void make() {
System.out.println("make xiaomi phone!");
}
}
#IPhone類:製造蘋果手機(Product2)
public class IPhone implements Phone {
public IPhone() {
this.make();
}
@Override
public void make() {
System.out.println("make iphone!");
}
}
現在有某手機代工廠:【天霸手機代工廠】。客戶只會告訴該工廠手機型號,就要匹配到不同型號的製作方案,那麼代工廠是怎麼實現的呢?其實也很簡單,簡單工廠模式(還有抽象工廠模式和工廠方法模式,有興趣可以了解下)是這麼實現的:
#PhoneFactory類:手機代工廠(Factory)
public class PhoneFactory {
public Phone makePhone(String phoneType) {
if(phoneType.equalsIgnoreCase("MiPhone")){
return new MiPhone();
}
else if(phoneType.equalsIgnoreCase("iPhone")) {
return new IPhone();
}
}
}
這樣客戶告訴你手機型號,你就可以調用代工廠類的方法去獲取到對應的手機製造類。你會發現其實也不過是if-else,但是把if-else抽到一個工廠類,由工廠類統一創建對象,對我們的業務代碼無入侵,不管是維護還是美觀上都會好很多。
首先,我們應該在每個特定的dataSourceProcessor(數據源執行器),比如MysqlProcesser、TidbProcesser中添加spring容器註解@Component。該註解我想應該不用多解釋了吧~重點是:我們可以把不同數據源都搞成類似的bean name,形如dataSourceProcessor#數據源名稱,如下兩段代碼:
@Component("dataSourceProcessor#mysql")
public class MysqlProcesser extends AbstractDataSourceProcesser<MysqlQueryInput>{
@Component("dataSourceProcessor#tidb")
public class TidbProcesser extends AbstractDataSourceProcesser<TidbQueryInput>{
這樣有什麼好處呢?我可以利用Spring幫我們一次性加載出所有繼承於AbstractDataSourceProcesser的Bean ,形如Map<String, AbstractDataSourceProcesser>,Key是Bean的名稱、而Value則是對應的Bean:
@Service
public class QueryDataServiceImpl implements QueryDataService {
@Resource
public Map<String, AbstractDataSourceProcesser> dataSourceProcesserMap;
public static String beanPrefix = "dataSourceProcessor#";
@Override
public List<HashMap> queryData(QueryInputDomain domain) {
AbstractDataSourceProcesser dataSourceProcesser = dataSourceProcesserMap.get(beanPrefix + domain.getDataSource());
//省略query代碼
}
}
可能你還是不太理解,我們直接看一下運行效果:
1、dataSourceProcesserMap內容如下所示,存儲了所有數據源Bean,Key是Bean的名稱、而Value則是對應的Bean:
2、我只需要通過key(即前綴+數據源名稱=beanName),就能匹配到對應的執行器了。比如當參數dataSource為tidb的時候,key為dataSourceProcessor#tidb,根據key可以直接從dataSourceProcesserMap中獲取到TidbProcesser
public static String classPrefix = "com.lyl.java.advance.service.";
AbstractDataSourceProcesser sourceGenerator =
(AbstractDataSourceProcesser) Class.forName
(classPrefix+DataSourceEnum.getClasszByCode(domain.getDataSource()))
.newInstance();
需要注意的是,該種方法是通過className來獲取到類的實例,而前端傳參肯定是不會傳className過來的。因此可以用到枚舉類,去定義好不同數據源的類名:
public enum DataSourceEnum {
mysql("mysql", "MysqlProcesser"),
tidb("tidb", "TidbProcesser");
private String code;
private String classz;
原創聲明:本文為【胖滾豬學編程】原創博文,轉載請註明出處。以漫畫形式讓編程生動有趣!原創不易,求關注!
總結
有些童鞋總覺得設計模式用不上,因為平時寫代碼除了CRUD還是CRUD,面試的時候問你設計模式,你只能回答最簡單的單例模式,問你有沒有用過反射之類的高級特性,回答也是否。
其實不然,JAVA這23種設計模式,每一個都是經典。今天我們就用模板方法模式+工廠模式(或者反射)解決了讓人崩潰的if-else。後續對於設計模式的學習,也應該多去實踐,從真實的項目中找到用武之地,你才算真正把知識佔為己有了。
本篇文章的內容和技術點雖然很簡單,但旨在告訴大家應該要有一個很好的代碼抽象思維。杜絕在代碼中出現一大摞if-else或者其他爛代碼。
即使你有很好的代碼抽象思維,做需求開發的時候,也不要局限於當下,只考慮現在,要多想想未來的擴展性。
就像你談戀愛一樣,只考慮當下的是渣男,考慮到未來的,才算是一個負責任的人
“願世界沒有渣男”
原創聲明:本文為【胖滾豬學編程】原創博文,轉載請註明出處。以漫畫形式讓編程生動有趣!原創不易,求關注!
本文來源於公眾號:【胖滾豬學編程】。一枚集顏值與才華於一身,不算聰明卻足夠努力的女程序媛。用漫畫形式讓編程so easy and interesting!求關注!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?