據統計,現代城市人的生活與工作同樓宇息息相關,超過80%的時間都是在城市樓宇中度過,樓宇智能毋庸置疑是影響深遠的關鍵研究課題。
近年來,隨着邊緣計算技術的崛起,邊緣智能相關的場景應用拓展也成為科技公司爭相展現技術創新和商業價值的路徑,各種邊緣AI的解決方案亦應運而生,如華為雲智能邊緣平台IEF,一站式端雲協同多模態AI開發平台HiLens。據統計,現代城市人的生活與工作同樓宇息息相關,超過80%的時間都是在城市樓宇中度過,樓宇智能毋庸置疑是影響深遠的關鍵研究課題。本文將圍繞樓宇智能其中最重要的課題之一中央空調能效預測與管理來展開,目前,該課題面臨最大的瓶頸是:現有的大多數能效預測與管理方法僅限於雲端單任務,無法支撐中央空調能效模型在邊緣隱含的大量複雜場景上的能力。
眾所周知,暖通空調系統(包括供暖,通風和空調)主導着商業建築的用電量。對暖通空調系統的現有研究表明,準確量化冷水機組的能效比(數值越大越節能)非常重要,近期提出的數據驅動的能效比預測可以被應用到雲上。但是,由於不同園區擁有不同型號的空調或不同種類的傳感器,導致不同邊緣各個項目在特徵、模型等方面區別很大,在小樣本情況下很難用一個通用模型適應所有的項目。
近年來,華為雲邊緣雲創新lab與來自香港理工大學、IBM研究院、華中科技大學、同濟大學、深圳大學等知名校企研究團隊密切合作並持續開展技術研究,以邊緣樓宇智能領域場景為依託,希望逐步解決現實中隱含大量複雜場景的邊緣智能問題。有興趣的讀者歡迎關注2018到2020間年發表的多任務學習、多任務調度和多任務應用等歷史工作:
通用算法:多任務遷移與邊緣調度
基於元數據的多任務遷移關係發現
Zheng, Z., Wang Y., Dai Q., Zheng H., Wang, D. “Metadata-driven task relation discovery for multi-task learning.” In Proceedings of IJCAI (CCF-A), 2019.
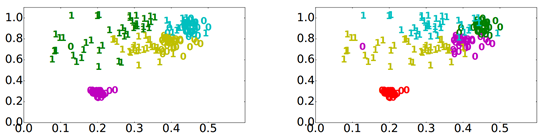
在這篇論文中有一個多任務的實際應用案例,不同邊緣智能項目採用不同設備使得邊緣側模型不同,從而可以應用於多任務設定。這篇論文的亮點是引入元數據,元數據是數據集的描述信息,在複雜系統中用於日常系統運作,蘊含專家信息。基於元數據提取任務屬性,本論文設計了元數據任務屬性與樣本任務屬性層次結合的多任務通用AI算法(圖1)。相關論文專家評審也認為該技術在應用實踐中显示了實用價值,對機器學習項目真正落地具備重要意義,將成為當今大型組織感興趣的技術。
圖1 顏色代表不同聚類簇,数字代表不同設備型號。基於樣本屬性的方法容易導致負遷移(同一簇中混淆不同型號設備模型,左圖),而基於元數據的方法可以避免負遷移(右圖)。
多任務遷移學習的邊緣任務分配系統與實現
Zheng, Z., Chen, Q., Hu, C., Wang, D., & Liu, F. “On-edge Multi-task Transfer Learning: Model and Practice with Data-driven Task Allocation.” In Proceedings of IEEE TPDS (CCF-A), 2019.
Chen, Q., Zheng, Z., Hu, C., Wang, D., & Liu, F. “Data-driven task allocation for multi-task transfer learning on the edge. ” In Proceedings of IEEE ICDCS (CCF-B), 2019.
多任務遷移學習是解決邊緣上樣本不足的典型做法。而目前邊緣上的任務分配調度工作通常假設不同的多個任務是同等重要的,導致資源分配在任務層面不夠高效。為了提升系統性能與服務質量,我們發現不同任務對決策的重要性是一個亟需衡量的重要指標。我們證明了基於重要性的任務分配是NP-complete的背包問題變種,並且在多變的邊緣場景下該複雜問題的解需要被頻繁地重新計算。因此我們提出一個用於解決該邊緣計算問題的AI驅動算法,並且在實際多變的邊緣場景中進行算法測試(圖2),與SOTA算法相比該算法能減少3倍以上的處理時間和近50%的能源消耗。
圖2 根據邊緣場景動態進行任務分配調度
邊緣應用:樓宇智能
基於多任務的冷機負荷控制
Zheng, Z., Chen, Q., Fan, C., Guan, N., Vishwanath, A., Wang, D., & Liu, F. “Data Driven Chiller Sequencing for Reducing HVAC Electricity Consumption in Commercial Buildings.” In Proceedings of ACM e-Energy, 2018. Best Paper Award.
Zheng, Z., Chen, Q., Fan, C., Guan, N., Vishwanath, A., Wang, D., & Liu, F. “An Edge Based Data-Driven Chiller Sequencing Framework for HVAC Electricity Consumption Reduction in Commercial Buildings.” IEEE Transactions on Sustainable Computing, 2019.
多任務可以應用於樓宇節能中。冷機是樓宇中的耗能大戶。冷機能效預測與管理,預測冷機負荷決策的能效比並優化冷機負荷決策,一直是樓宇智能最重要的研究問題之一。本研究觀測到,在冷機決策能效預測中,不同邊緣項目的設備型號和工況不同會導致最終需求的模型不同。這種情況下僅採用雲端單一模型的做法容易導致精度下降和決策失誤。本工作研發了一種邊雲協同的多任務冷機負荷決策框架(圖3),在利用現有端邊節點且不部署額外硬件的情況下,較當前工業界方法節能30%以上。
圖3 邊雲協同的冷機負荷決策框架
基於多任務的空調舒適度預測
Zheng, Z., Dai Y., Wang D., “DUET: Towards a Portable Thermal Comfort Model.” In Proceedings of ACM BuildSys (Core rank A), 2019.
Yang, L., Zheng, Z., Sun, J., Wang, D., & Li, X. A domain-assisted data driven model for thermal comfort prediction in buildings. In Proceedings of ACM e-Energy. 2018.
空調舒適度預測是樓宇智能歷史長河中重要的研究課題之一。目前的舒適度預估方法通常要求額外的傳感器或者用戶反饋等人工干預,這使得規模化本身成為難題。基於機器學習方法的空調舒適度預測已被證明可以減少額外的人工干預。但在不同邊緣場景下,樓宇製冷類型、安裝傳感器類別等因素會使得雲上單一通用模型出現嚴重錯誤。本研究提出了一種多任務的方法進行空調舒適度的預測,在精度上較機理模型和單任務模型分別提升39%和31%。
邊緣自適應任務定義
基於以上項目,讀者可以了解到基於多任務的邊緣智能算法、系統與應用。值得注意的是,在使用多任務之前,首先需要回答任務如何定義和劃分的問題,如確定在一個應用內不同項目所需機器學習模型的數量以及各個模型的應用範圍。該方法目前通常只能由數據科學家和領域專家人工進行干預,自動化程度低,難以規模化複製。因此,邊緣自動定義機器學習任務是一個懸而未決但又重要的難題。
為了在邊緣各種場景自適應地定義機器學習預測任務,華為雲邊緣雲創新Lab近日發表了研究論文《MELODY: Adaptive Task Definition of COP Prediction with Metadata for HVAC Control and Electricity Saving》。該研究提出了一種包含任務定義的多任務預測框架(MELODY),其中任務定義能夠自適應地定義並學習複數能效比預測任務。
MELODY是第一個根據各種邊緣場景自適應定義能效比預測任務的方法。本研究工作為尋求自動有效的邊緣機器學習方法的研究人員和應用開發人員提供了一種有吸引力的機制,特別適用於對於元數據多樣化但數據樣本不足的複雜系統。MELODY的關鍵思想是使用元數據動態劃分多個任務,論文提出了元數據的數學定義以及提取元數據的2種來源和方法。
該團隊在實際應用中評估該方案的性能:基於2個大型工業園區中的8座建築物中9台冷機進行4個月實驗。實驗結果表明,MELODY解決方案優於最新的能效比預測方法,並且能夠為兩個園區每月節省252 MWh的電量,較當前建築中冷水機的運行方式節省了35%以上的能源。
MELODY論文已獲ACM e-Energy 2020接收:
Zimu Zheng,Daqi Xie,Jie Pu,Feng Wang. MELODY: Adaptive Task Definition of COP Prediction with Metadata for HVAC Control and Electricity Saving. ACM e-Energy 2020. Australia.
ACM e-Energy 屬於ACM EIG-Energy Interest Group、計算機與能源交叉的旗艦會議。
1、論文接受率23.2%,歷年接受率在20%左右;
2、與CCF-A的Ubicomp; CCF-B的ECAI、TKDD H5-index相同;
3、55位評審程序委員會成員中包括Andrew A. Chien、Klara Nahrstedt、Prashant Shenoy等8位ACM/IEEE Fellow(約15%);
4、評審程序委員會成員來自IBM研究院、伊利諾伊大學香檳分校、劍橋大學、華盛頓大學、普渡大學、馬薩諸塞大學阿默斯特分校、西蒙菲沙大學、南洋理工大學、清華大學、香港理工大學等國際知名校企;
5、與CCF-A的STOC、ISCA、PLDI;CCF-B的IWQos、SIG Metric、COLT、HPDC、ICS、LCTES、SPAA等同屬ACM Federated Computing Research Conference (FCRC)系列的13個會議中,ACM FCRC頂會系列由Google、微軟、IBM、華為、arm、Xilinx等國際知名企業贊助。
能效比預測
基於冷機的暖通空調系統通常用於商業建築中,消耗的電力占建築物總用電量的40%至70%,這種消耗量主要由暖通空調系統的消耗量決定。商業建築物支付的電費(其中大部分歸於暖通空調系統)通常位於組織運營支出的前三名。這種趨勢給設施管理者帶來了巨大的壓力,他們需要通過減少與暖通空調系統相關的電力消耗來提高建築的能源利用效率。
暖通空調的主要消耗來自冷機(見圖4)。典型的冷機負荷控制的有效性在很大程度上取決於冷機運行時的性能,即在不同的冷負荷條件下的能效比。能效比是衡量冷機能效的指標,指的是在單位輸入功率消耗下的輸出冷量。能效比通常大於1,值越大,意味着效率越高。在實踐中,設施管理人員通常在冷機部署到建築物期間,在首次測試和調試冷水機組時衡量能效比的初始信息,並用該初始信息來執行冷機負荷控制。初始信息測試時通常將冷量負荷視為唯一參數。然而,這些初始信息無法捕獲實際參數的影響,並且已被近期研究證明是不精確的。
圖4 冷機示意圖
本研究以能效比預測問題作為個例研究。能效比高度依賴於多種因素,例如工況、冷量需求、設備老化、天氣等。為了在冷水機組中捕獲這些因素,現有工作已經提出採用數據驅動方法。能效比預測問題可以看做是在訓練階段學習一種被稱為模型的“公式”,該公式在推理階段能夠輸出具有給定特徵的能效比。
自適應任務定義
現有方法通常假定預測任務的配置,比如同一應用下的預測模型的數量和預測模型的應用範圍,是由數據科學家或領域專家定義和固定的。下文比較三種被廣泛接受的設定:單任務設定、多任務設定和專家輔助的多任務設定。
單任務設定
一個最典型的、被廣泛接受的預測任務配置方法是基於固定的單任務設定:這意味着將所有數據集作為一個整體合併在一起,並訓練單個預測模型。研究人員可以使用任何機器學習算法(例如SVM、神經網絡、Boosting等)來學習這種模型,並在任何場景下的推理階段都應用訓練出的這單個模型。
單任務設定假設對於同一應用下不同項目內不同的數據集,單個模型應足以描述所選特徵和能效比之間的關係。但是,這種假設可能並不總是成立。
比方說有兩個園區採用了兩種類型的冷水機:園區H使用了特靈CVHG1100冷水機和園區J使用了開利W3C100冷水機,那麼應根據冷水機的型號調整在特徵和能效比之間的熱力學模型。邊緣用戶往往也期待看到應用到兩個邊緣項目的模型有所不同:即使兩種冷水機輸入相同的水溫等特徵值,輸出的能效比也應不同。但如果將兩個數據集合併在一起並訓練同一個能效比模型,通常很難在沒有人工干預的情況下確保這一點。
論文作者過去的研究還表明,除了不同邊緣項目採用冷機型號不同可能導致模型不同外,可能導致模型不同的例子還包括:不同項目採用的工況和參數配置不同、不同項目採用的傳感器種類不同、不同季節採用特徵不同等(篇幅原因不再贅述,感興趣的讀者可以參考文章開頭提及的研究團隊歷史工作)。不同邊緣場景訓練出的模型應用範圍可能是迥乎不同的。所以對於不同的場景都採用單任務設定並非總是最佳選擇,這可能在實踐中引發重大錯誤,尤其是某些邊緣智能項目中訓練樣本的大小不足以在大量特徵中自動將場景彼此區分的情況。
多任務設定
但目前預測任務的配置,例如所需模型的數量以及模型的應用範圍,仍然是一個開放性問題。為了深入研究此問題,該團隊進一步驗證多任務設定而非單任務設定,也即觀察多個模型在多個測試集上的性能。在一個實際建築物中,使用了從冷機1到冷機5的訓練數據集訓練了5個模型(以下稱為M1 – M5)。然後在另外5個測試數據集(T1 – T5)的不同場景中測試了5個模型的性能。實驗及其結果分別如圖5-1、5-2所示。
圖5-1 複數冷機訓練模型在不同冷機測試集下的實驗示意圖
圖5-2 複數冷機訓練模型在不同冷機測試集下的預測準確率和樣本採集時間對比結果
觀察結果显示,
1)精度
儘管是基於不同的數據集進行訓練,但是冷機1的模型在冷機2和冷機3的測試集上效果很好,而在冷機4和冷機5的測試集上卻導致嚴重錯誤。對於冷機2到冷機5的模型可以看到類似的觀察結果。這是因為冷機1到冷機3來自同一種冷機型號,而冷機4和冷機5是另一種型號。
2)樣本採集時間
如果按冷機來劃分任務,每個冷機任務至少需要81天的樣本。但如果按照型號劃分為2個任務,每個型號任務僅需30天的樣本。這是因為每個型號任務包含多台冷機採集的數據。
根據上述精度和樣本採集時間的結果,與其考慮5個冷機從而定義5個冷機任務,在這個數據集下不如考慮2個型號(冷機1-3和冷機4-5)從而定義2個型號任務,在上述例子中可以降低63%左右的樣本採集時間,同時提升近10%的精度。
專家輔助的多任務設定
實際上,不僅冷機型號,隨時間變化的環境(例如,天氣條件)和工況(例如,供水溫度)也可以導致能效比模型的變化。藉助領域專家的知識,可以在構建的環境中定義固定的任務,並將這些固定的任務應用於不同的建築中。
例如,基於建築環境研究中的領域專業知識,該團隊最近一項工作在三座建築物中根據工況給出了固定的50個任務,用於多任務冷機能效比預測;該團隊最近另外一項工作根據季節和製冷類型在160座建築物中給出了固定的4個任務,以進行多任務熱舒適性預測。
但是,所需模型的數量及其應用範圍可以根據不同的邊緣項目場景而變化,而領域專家的配置很難跟隨不同邊緣項目動態擴展。例如,在一個建築物的少量數據集中,最好有3個任務,即訓練3種不同的模型進行能效比預測。但是在另一個包含1000座建築物的大型數據集中,最好有75個任務。在邊緣場景手動定義要預測的機器學習任務通常會導致成本過高或準確性降低,尤其是當任務隨項目和時間而動態變化時。因此,有必要針對不同場景自適應地定義任務。
MELODY
本研究工作旨在解決自適應任務定義問題,也即不同場景下自動化定義不同的任務,例如,在不同場景中確定需要使用的模型數量以及模型的應用範圍等。該團隊遇到三個主要挑戰,並提出了使用自適應任務定義方法的多任務預測框架(MELODY)。
挑戰1:當前項目的目標未知,而且通常更糟糕的是,可能的任務候選集也未知。
MELODY通過提出任務挖掘解決了第一個挑戰。它基於諸如任務森林等新穎結構和算法來自適應地定義任務,參見圖6。這使得MELODY可規模化到眾多建築和環境的能效比預測。
圖6 任務森林的例子:數據表示模型訓練樣本,屬性表示模型應用範圍;節點表示子任務,包括數據、屬性和模型(若有);森林的每個根節點,也即每棵樹的頂點,表示各個子任務合併成的一個任務。對任務森林初始化和維護等具體實現和算法複雜度等證明,有興趣的讀者可以閱讀論文附錄。
挑戰2:標誌能效比模型應用範圍的屬性未知,同時此類屬性的來源也在研究中。
MELODY通過使用元數據作為任務屬性的來源來解決第二個挑戰。
元數據由領域專家定義,用於建築管理系統的日常控制。例如,傳感器的名稱和建築物的類型是元數據。在MELODY框架中,該團隊提出了從數據庫的兩個來源中提取兩種元數據的方法。
元數據包含潛在領域信息,藉助這些信息,能夠自適應地提取具有領域知識的任務,併為自動和強大的任務定義打開了方便之門,如圖7所示。
圖7 基於元數據提取的任務定義(具體實現請參見論文)
挑戰3:任務組合數量隨屬性數量指數增長;因此,冷機樣本不足以為所有組合訓練模型。
MELODY通過利用多任務遷移學習克服了第三個挑戰。在多任務優化中,學習任務可以使用來自其他不同任務的知識,從而減少數據量的需求。
多任務評估
本研究工作通過將其應用於實際數據來評估方案的性能,在2個大型工業園區中的8座建築物中9台冷機進行4個月時間的實驗。園區情況可參見圖8。
圖8 2個大型工業園區中的8座建築物及其冷機信息
表1 任務定義輸出結果
表1显示了通過任務定義算法挖掘出的任務的總體信息,在Park J和Park H中發現了兩組不同的任務集合。觀察显示不同項目模型的數量和使用模型時的場景都不同。藉助五分鐘的間隔數據,可以在Park J中挖掘出33個任務,這些任務模型的應用範圍主要根據冷機額定功率和平均濕度的來判斷。藉助一小時的時間間隔數據,Park H中僅有2個任務,應用範圍需要通過額定功率和額定製冷量來判斷。可以發現每個任務中的樣本量很小。 對於總共35個任務,有13個任務的樣本數少於100,其餘22個任務的樣本數少於1000。
研究比較了幾種應用於冷機能效預測的典型方法:
(1)工業界當前方法:初始配置文件(IP)利用安裝時測量的初始配置文件來估算未來的能效比,是目前工業界正在使用的方法。
(2)學術界常用方法:單任務學習(STL)通過將來自每個數據集的所有任務的數據匯總在一起來學習一個模型;
(3)近期研究工作:關於數據源的獨立多任務學習(IMTL),它獨立於數據源學習每個任務。例如,針對9個冷機固定9個任務,而無需在任務之間共享任何樣本或知識;
(4)近期研究工作:具有領域知識的多任務學習(MTL),它學習具有由領域知識定義的任務聚類。例如,固定的50個任務,其中10個負載比和5個冷機。
表2 各方法錯誤率提升
表2結果显示,MELODY的任務定義可以比STL(單任務方法)有所提升。 但是,不正確的任務定義(即IMTL和MTL)對比單任務方法未能有所提升。這主要是因為與在不同數據集中(如MELODY)使用自適應任務的方法相比,IMTL和MTL在劃分任務後會生成較小的數據集,這導致部分任務內缺乏訓練樣本。當任務數量隨着屬性數目和時間推移而增加時,效果變得更差,因為任務遷移關係變得越來越複雜。在這種情況下,任務之間共享知識變得更具挑戰性,並容易導致一種被稱為負遷移的影響,也即從不相關的源域到目標域共享知識而導致的錯誤。可以看到,MELODY能解決相關問題,從而使得結果優於最新的能效比預測方法,將能效比預測誤差率降低了18.18-61.70%,最終能夠在兩個園區上每月節省252 MWh的電量,與當前建築中冷水機的運行方式相比節省了36.75%以上的能源。
本文作者:鄭博士,華為雲邊緣雲創新Lab高級研究工程師,畢業於香港理工大學,主要研究方向是邊緣智能及AIoT。發表國際相關領域頂級會議及期刊 (TPDS、 IJCAI、 ICDCS、CIKM、TOSN、TIST等) 論文十餘篇,多次獲得最佳會議論文獎項,多次獲得關鍵技術突破、高價值專利和新服務孵化等華為傑出貢獻獎項。
華為雲邊緣雲創新Lab:願景是探索端邊雲協同關鍵技術,構建無所不在的、極致體驗的智能邊緣雲。聯合工業夥伴和學術機構,共同致力於研究邊緣雲創新技術、孵化邊緣雲創新應用、構建邊緣雲繁榮生態。研究方向包括大規模智能邊緣雲平台、邊雲協同AI、端邊雲協同渲染與視頻加速。目前已孵化上線華為邊緣計算平台IEF,並貢獻首個基於Kubernetes的雲原生邊緣計算平台KubeEdge,獲尖峰開源技術創新獎、最佳智能邊緣計算技術創新平台等多項獎項;孵化的業內首個邊雲協同增量學習工作流即將上線華為雲HiLens服務、IEF服務;學術上近2年已發表7篇邊雲協同AI、雲原生邊緣計算相關頂會論文,獲多項最佳論文和優秀論文獎項。
點擊關注,第一時間了解華為雲新鮮技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※FB行銷專家,教你從零開始的技巧