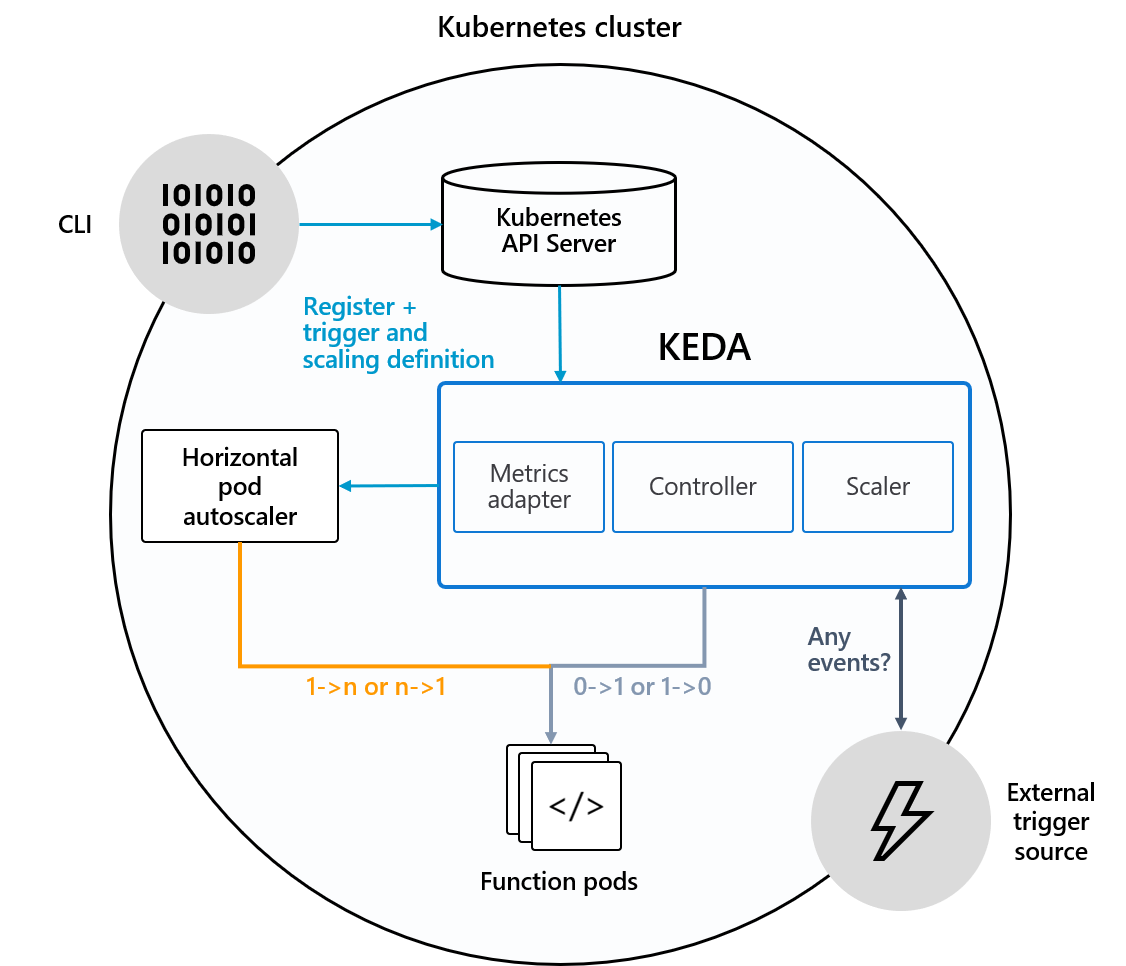
隨着大數據和AI業務的不斷融合,大數據分析和處理過程中,通過深度學習技術對非結構化數據(如圖片、音頻、文本)進行大數據處理的業務場景越來越多。本文會介紹Spark如何與深度學習框架進行協同工作,在大數據的處理過程利用深度學習框架對非結構化數據進行處理。
Spark介紹
Spark是大規模數據處理的事實標準,包括機器學習的操作,希望把大數據處理和機器學習管道整合。
Spark使用函數式編程範式擴展了MapReduce模型以支持更多計算類型,可以涵蓋廣泛的工作流。Spark使用內存緩存來提升性能,因此進行交互式分析也足夠快速(如同使用Python解釋器,與集群進行交互一樣)。緩存同時提升了迭代算法的性能,這使得Spark非常適合機器學習。
由於Spark庫提供了Python、Scale、Java編寫的API,以及內建的機器學習、流數據、圖算法、類SQL查詢等模塊;Spark迅速成為當今最重要的分佈式計算框架之一。與YARN結合,Spark提供了增量,而不是替代已存在的Hadoop集群。在最近的Spark版本中,Spark加入了對於K8s的支持,為Spark與AI能力的融合提供了更好的支持。
深度學習框架介紹
TensorFlow
TensorFlow最初是由Google機器智能研究部門的Google Brain團隊開發,基於Google 2011年開發的深度學習基礎架構DistBelief構建起來的。由於Google在深度學習領域的巨大影響力和強大的推廣能力,TensorFlow一經推出就獲得了極大的關注,並迅速成為如今用戶最多的深度學習框架。
TensorFlow是一個非常基礎的系統,因此也可以應用於眾多領域。但由於過於複雜的系統設計,對讀者來說,學習TensorFlow底層運行機制更是一個極其痛苦的過程。TensorFlow的接口一直處於快速迭代之中,並且沒有很好地考慮向後兼容性,這導致現在許多開源代碼已經無法在新版的TensorFlow上運行,同時也間接導致了許多基於TensorFlow的第三方框架出現BUG。
Keras
Keras 於2015年3月首次發布,擁有“為人類而不是機器設計的API”,得到Google的支持。它是一個用於快速構建深度學習原型的高層神經網絡庫,由純Python編寫而成,以TensorFlow、CNTK、Theano和MXNet為底層引擎,提供簡單易用的API接口,能夠極大地減少一般應用下用戶的工作量。
嚴格意義上講,Keras並不能稱為一個深度學習框架,它更像一個深度學習接口,它構建於第三方框架之上。Keras的缺點很明顯:過度封裝導致喪失靈活性。Keras最初作為Theano的高級API而誕生,後來增加了TensorFlow和CNTK作為後端。學習Keras十分容易,但是很快就會遇到瓶頸,因為它缺少靈活性。另外,在使用Keras的大多數時間里,用戶主要是在調用接口,很難真正學習到深度學習的內容。
PyTorch
PyTorch於2016年10月發布,是一款專註於直接處理數組表達式的低級API。 前身是Torch(一個基於Lua語言的深度學習庫)。Facebook人工智能研究院對PyTorch提供了強力支持。PyTorch支持動態計算圖,為更具數學傾向的用戶提供了更低層次的方法和更多的靈活性,目前許多新發表的論文都採用PyTorch作為論文實現的工具,成為學術研究的首選解決方案。
Caffe/Caffe2.0
Caffe的全稱是Convolutional Architecture for Fast Feature Embedding,它是一個清晰、高效的深度學習框架,於2013年底由加州大學伯克利分校開發,核心語言是C++。它支持命令行、Python和MATLAB接口。Caffe的一個重要特色是可以在不編寫代碼的情況下訓練和部署模型。如果您是C++熟練使用者,並對CUDA計算游刃有餘,你可以考慮選擇Caffe。
在Spark大數據處理中使用深度學習框架
在Spark程序中使用一個預訓練過的模型,將其并行應用於大型數據集的數據處理。比如,給定一個可以識別圖片的分類模型,其通過一個標準數據集(如ImageNet)訓練過。可以在一個Spark程序中調用一個框架(如TensorFlow或Keras)進行分佈式預測。通過在大數據處理過程中調用預訓練模型可以直接對非結構化數據進行直接處理。
我們重點介紹在Spark程序中使用Keras+TensorFlow來進行模型推理。
使用深度學習處理圖片的第一步,就是載入圖片。Spark 2.3中新增的ImageSchema包含了載入數百萬張圖像到Spark DataFrame的實用函數,並且以分佈式方式自動解碼,容許可擴展地操作。
使用Spark’s ImageSchema:
from pyspark.ml.image import ImageSchema image_df = ImageSchema.readImages("/data/myimages") image_df.show()
也可以利用Keras的圖片處理庫:
from keras.preprocessing import image img = image.load_img("/data/myimages/daisy.jpg", target_size=(299, 299))
可以通過圖片路徑來構造Spark DataFrame:
def get_image_paths_df(sqlContext, dirpath, colName): files = [os.path.abspath(os.path.join(dirpath, f)) for f in os.listdir(dirpath) if f.endswith('.jpg')] return sqlContext.createDataFrame(files, StringType()).toDF(colName)
使用Keras接口加載預訓練模型:
from keras.applications import InceptionV3 model = InceptionV3(weights="imagenet") model.save('/tmp/model-full.h5') model = load_model('/tmp/model-full.h5')
定義圖片識別推理方法:
def iv3_predict(fpath): model = load_model('/tmp/model-full.h5') img = image.load_img(fpath, target_size=(299, 299)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = preprocess_input(x) preds = model.predict(x) preds_decode_list = decode_predictions(preds, top=3) tmp = preds_decode_list[0] res_list = [] for x in tmp: res = [x[0], x[1], float(x[2])] res_list.append(res) return res_list
定義推理輸入結果Schema:
def get_labels_type(): ele_type = StructType() ele_type.add("class", data_type=StringType()) ele_type.add("description", data_type=StringType()) ele_type.add("probability", data_type=FloatType()) return ArrayType(ele_type)
將推理方法定義成Spark UDF:
spark.udf.register("iv3_predict", iv3_predict, returnType=get_labels_type())
載入圖片定義為數據表:
df = get_image_paths_df(self.sql) df.createOrReplaceTempView("_test_image_paths_df")
使用SQL語句對接圖片進行處理:
df_images = spark.sql("select fpath, iv3_predict(fpath) as predicted_labels from _test_image_paths_df") df_images.printSchema() df_images.show(truncate=False)
結語
在大數據Spark引擎中使用深度學習框架加載預處理模型,來進行非結構數據處理有非常多的應用場景。但是由於深度學習框架目前比較多,模型與框架本身是深度耦合,在大數據環境中安裝和部署深度學習框架軟件及其依賴軟件會非常複雜,同時不利於大數據集群的管理和維護,增加人力成本。
華為雲DLI服務,採用大數據Serverless架構,用戶不需要感知實際物理集群,同時DLI服務已經在大數據集群中內置了AI計算框架和底層依賴庫(Keras/tensorflow/scikit-learn/pandas/numpy等)。DLI最新版本中已經支持k8s+Docker生態,並開放用戶自定義Docker鏡像能力,提供給用戶來擴展自己的AI框架、模型、算法包。在Serverless基礎上,為用戶提供更加開放的自定義擴展能力。
DLI支持多模引擎,企業僅需使用SQL或程序就可輕鬆完成異構數據源的批處理、流處理等,挖掘和探索數據信息,揭示其中的規律並發現數據潛在價值,華為雲618年中鉅惠,大數據+AI專場,歷史低價,助力企業“智能化”,業務“數據化”。
點擊關注,第一時間了解華為雲新鮮技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※FB行銷專家,教你從零開始的技巧
※聚甘新