NioEventLoop的創建
NioEventLoop是netty及其重要的組成部件,它的首要職責就是為註冊在它上的channels服務,發現這些channels上發生的新連接、讀寫等I/O事件,然後將事件轉交 channel 流水線處理。使用netty時,我們首先要做的就是創建NioEventLoopGroup,這是一組NioEventLoop的集合,類似線程與線程池。通常,服務端會創建2個group,一個叫做bossGroup,一個叫做workerGroup。bossGroup負責監聽綁定的端口,接受請求並創建新連接,初始化后交由workerGroup處理後續IO事件。
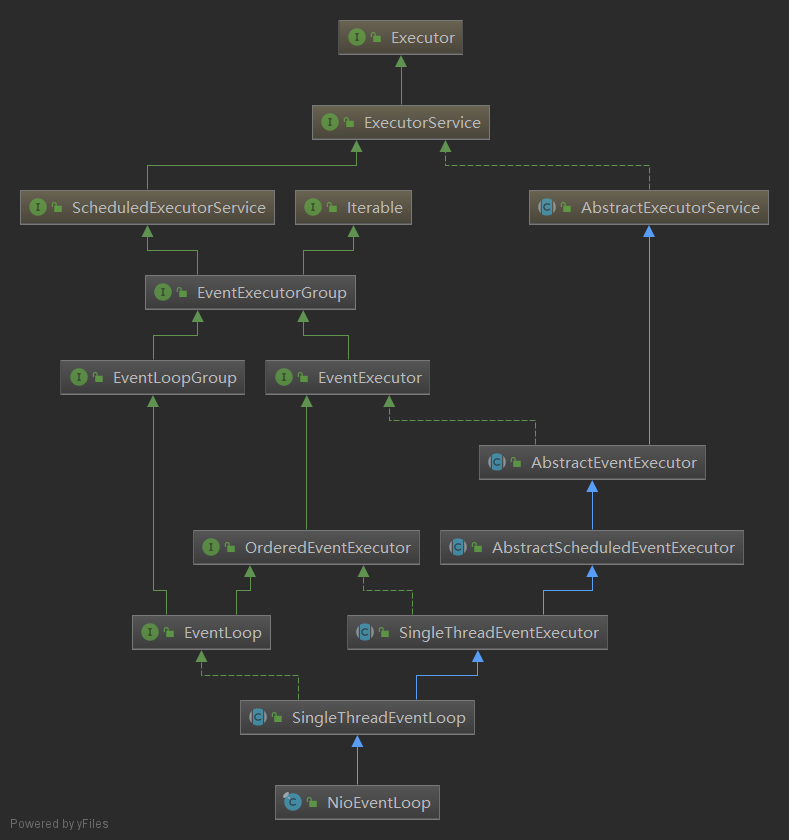
NioEventLoop和NioEventLoopGroup的類圖
首先看看NioEventLoop和NioEventLoopGroup的類關係圖
類多但不亂,可以發現三個特點:
- 兩者都繼承了ExecutorService,從而與線程池建立了聯繫
- NioEventLoop繼承的都是SingleThread,NioEventLoop繼承的是MultiThread
- NioEventLoop還繼承了AbstractScheduledEventExecutor,不難猜出這是個和定時任務調度有關的線程池
NioEventLoopGroup的創建
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
我們先看看bossGroup和workerGroup的構造方法。
public NioEventLoopGroup() {
this(0);
}
public NioEventLoopGroup(int nThreads) {
this(nThreads, (Executor) null);
}
除此之外,還有多達8種構造方法,這些構造方法可以指定5種參數:
1、最大線程數量。如果指定為0,那麼Netty會將線程數量設置為CPU邏輯處理器數量的2倍
2、線程工廠。要求線程工廠類必須實現java.util.concurrent.ThreadFactory接口。如果沒有指定線程工廠,那麼默認DefaultThreadFactory。
3、SelectorProvider。如果沒有指定SelectorProvider,那麼默認的SelectorProvider為SelectorProvider.provider()。
4、SelectStrategyFactory。如果沒有指定則默認為DefaultSelectStrategyFactory.INSTANCE
5、RejectedExecutionHandler。拒絕策略處理類,如果這個EventLoopGroup已被關閉,那麼之後提交的Runnable任務會默認調用RejectedExecutionHandler的reject方法進行處理。如果沒有指定,則默認調用拒絕策略。
最終,NioEventLoopGroup會重載到父類MultiThreadEventExecutorGroup的構造方法上,這裏省略了一些健壯性代碼。
protected MultithreadEventExecutorGroup(int nThreads, Executor executor,EventExecutorChooserFactory chooserFactory, Object... args) {
// 步驟1
if (executor == null) {
executor = new ThreadPerTaskExecutor(newDefaultThreadFactory());
}
// 步驟2
children = new EventExecutor[nThreads];
for (int i = 0; i < nThreads; i ++) {
children[i] = newChild(executor, args);
}
// 步驟3
chooser = chooserFactory.newChooser(children);
// 步驟4
final FutureListener<Object> terminationListener = future -> {
if (terminatedChildren.incrementAndGet() == children.length) {
terminationFuture.setSuccess(null);
}
};
for (EventExecutor e: children) {
e.terminationFuture().addListener(terminationListener);
}
// 步驟5
Set<EventExecutor> childrenSet = new LinkedHashSet<>(children.length);
Collections.addAll(childrenSet, children);
readonlyChildren = Collections.unmodifiableSet(childrenSet);
}
這裏可以分解為5個步驟,下面一步步講解
步驟1
第一個步驟是創建線程池executor。從workerGroup構造方法可知,默認傳進來的executor為null,所以首先創建executor。newDefaultThreadFactory的作用是設置線程的前綴名和線程優先級,默認情況下,前綴名是nioEventLoopGroup-x-y這樣的命名規則,而線程優先級則是5,處於中間位置。
創建完newDefaultThreadFactory后,進入到ThreadPerTaskExecutor。它直接實現了juc包的線程池頂級接口,從構造方法可以看到它只是簡單的把factory賦值給自己的成員變量。而它實現的接口方法調用了threadFactory的newThread方法。從名字可以看出,它構造了一個thread,並立即啟動thread。
public ThreadPerTaskExecutor(ThreadFactory threadFactory) {
this.threadFactory = threadFactory;
}
@Override
public void execute(Runnable command) {
threadFactory.newThread(command).start();
}
那麼我們回過頭來看下DefaultThreadFactory的newThread方法,發現他創建了一個FastThreadLocalThread。這是netty自定義的一個線程類,顧名思義,netty認為它的性能更快。關於它的解析留待以後。這裏步驟1創建線程池就完成了。總的來說他與我們通常使用的線程池不太一樣,不設置線程池的線程數和任務隊列,而是來一個任務啟動一個線程。(問題:那任務一多豈不是直接線程爆炸?)
@Override
public Thread newThread(Runnable r) {
Thread t = newThread(FastThreadLocalRunnable.wrap(r), prefix + nextId.incrementAndGet());
return t;
}
protected Thread newThread(Runnable r, String name) {
return new FastThreadLocalThread(threadGroup, r, name);
}
步驟2
步驟2是創建workerGroup中的NioEventLoop。在示例代碼中,傳進來的線程數是0,顯然不可能真的只創建0個nioEventLoop線程。在調用父類MultithreadEventLoopGroup構造函數時,對線程數進行了判斷,若為0,則傳入默認線程數,該值默認為2倍CPU核心數
protected MultithreadEventLoopGroup(int nThreads, Executor executor, Object... args) {
super(nThreads == 0 ? DEFAULT_EVENT_LOOP_THREADS : nThreads, executor, args);
}
// 靜態代碼塊初始化DEFAULT_EVENT_LOOP_THREADS
static {
DEFAULT_EVENT_LOOP_THREADS = Math.max(1, SystemPropertyUtil.getInt("io.netty.eventLoopThreads", NettyRuntime.availableProcessors() * 2));
}
接下來是通過newChild方法為每一個EventExecutor創建一個對應的NioEventLoop。這個方法傳入了一些args到NioEventLoop中,前三個是在NioEventLoopGroup創建時傳過來的參數。默認值見上文
- SlectorProvider.provider, 用於創建 Java NIO Selector 對象;
- SelectStrategyFactory, 選擇策略工廠;
- RejectedExecutionHandlers, 拒絕執行處理器;
- EventLoopTaskQueueFactory,任務隊列工廠,默認為null;
進入NioEventLoop的構造函數,如下:
NioEventLoop構造函數
NioEventLoop(NioEventLoopGroup parent, Executor executor, SelectorProvider selectorProvider,
SelectStrategy strategy, RejectedExecutionHandler rejectedExecutionHandler,
EventLoopTaskQueueFactory queueFactory) {
super(parent, executor, false, newTaskQueue(queueFactory), newTaskQueue(queueFactory),
rejectedExecutionHandler);
if (selectorProvider == null) {
throw new NullPointerException("selectorProvider");
}
if (strategy == null) {
throw new NullPointerException("selectStrategy");
}
provider = selectorProvider;
final SelectorTuple selectorTuple = openSelector();
selector = selectorTuple.selector;
unwrappedSelector = selectorTuple.unwrappedSelector;
selectStrategy = strategy;
}
// 父類構造函數
protected SingleThreadEventExecutor(EventExecutorGroup parent, Executor executor,
boolean addTaskWakesUp, Queue<Runnable> taskQueue,
RejectedExecutionHandler rejectedHandler) {
super(parent);
this.addTaskWakesUp = addTaskWakesUp;
this.maxPendingTasks = DEFAULT_MAX_PENDING_EXECUTOR_TASKS;
this.executor = ThreadExecutorMap.apply(executor, this);
this.taskQueue = ObjectUtil.checkNotNull(taskQueue, taskQueue");
rejectedExecutionHandler = ObjectUtil.checkNotNullrejectedHandler, "rejectedHandler");
}
首先調用一個newTaskQueue方法創建一個任務隊列。這是一個mpsc即多生產者單消費者的無鎖隊列。之後調用父類的構造函數,在父類的構造函數中,將NioEventLoopGroup設置為自己的parent,並通過匿名內部類創建了這樣一個Executor————通過ThreadPerTaskExecutor執行傳進來的任務,並且在執行時將當前線程與NioEventLoop綁定。其他屬性也一一設置。
在nioEventLoop構造函數中,我們發現創建了一個selector,不妨看一看netty對它的包裝。
unwrappedSelector = provider.openSelector();
if (DISABLE_KEY_SET_OPTIMIZATION) {
return new SelectorTuple(unwrappedSelector);
}
首先看到netty定義了一個常量DISABLE_KEY_SET_OPTIMIZATION,如果這個常量設置為true,也即不對keyset進行優化,則直接返回未包裝的selector。那麼netty對selector進行了哪些優化?
final SelectedSelectionKeySet selectedKeySet = new SelectedSelectionKeySet();
final class SelectedSelectionKeySet extends AbstractSet<SelectionKey> {
SelectionKey[] keys;
int size;
SelectedSelectionKeySet() {
keys = new SelectionKey[1024];
}
}
往下,我們看到了一個叫做selectedSelectionKeySet的類,點進去可以看到,它繼承了AbstractSet,然而它的成員變量卻讓我們想到了ArrayList,再看看它定義的方法,除了不支持remove和contains外,活脫脫一個簡化版的ArrayList,甚至也支持擴容。
沒錯,netty確實通過反射的方式,將selectionKey從Set替換為了ArrayList。仔細一想,卻又覺得此番做法有些道理。眾所周知,雖然HashSet和ArrayList隨機查找的時間複雜度都是o(1),但相比數組直接通過偏移量定位,HashSet由於需要Hash運算,時間消耗上又稍稍遜色了些。再加上使用場景上,都是獲取selectionKey集合然後遍歷,Set去重的特性完全用不上,也無怪乎追求性能的netty想要替換它了。
步驟3
創建完workerGroup的NioEventLoop后,如何挑選一個nioEventLoop進行工作是netty接下來想要做的事。一般來說輪詢是一個很容易想到的方案,為此需要創建一個類似負載均衡作用的線程選擇器。當然追求性能到喪心病狂的netty是不會輕易滿足的。我們看看netty在這樣常見的方案里又做了哪些操作。
public EventExecutorChooser newChooser(EventExecutor[] executors) {
if (isPowerOfTwo(executors.length)) {
return new PowerOfTwoEventExecutorChooser(executors);
} else {
return new GenericEventExecutorChooser(executors);
}
}
// PowerOfTwo
public EventExecutor next() {
return executors[idx.getAndIncrement() & executors.length - 1];
}
// Generic
public EventExecutor next() {
return executors[Math.abs(idx.getAndIncrement() % executors.length)];
}
可以看到,netty根據workerGroup內線程的數量採取了2種不同的線程選擇器,當線程數x是2的冪次方時,可以通過&(x-1)來達到對x取模的效果,其他情況則需要直接取模。這與hashmap強制設置容量為2的冪次方有異曲同工之妙。
步驟4
步驟4就是添加一些保證健壯性而添加的監聽器了,這些監聽器會在EventLoop被關閉后得到通知。
步驟5
創建一個只讀的NioEventLoop線程組
到此NioEventLoopGroup及其包含的NioEventLoop組就創建完成了
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?