環境資訊中心綜合外電;黃鈺婷 翻譯;林大利 審校;稿源:Mongabay
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
點贊再看,養成習慣,微信搜索【三太子敖丙】關注這個互聯網苟且偷生的工具人。
本文 GitHub https://github.com/JavaFamily 已收錄,有一線大廠面試完整考點、資料以及我的系列文章。
鎖我想不需要我過多的去說,大家都知道是怎麼一回事了吧?
在多線程環境下,由於上下文的切換,數據可能出現不一致的情況或者數據被污染,我們需要保證數據安全,所以想到了加鎖。
所謂的加鎖機制呢,就是當一個線程訪問該類的某個數據時,進行保護,其他線程不能進行訪問,直到該線程讀取完,其他線程才可使用。
還記得我之前說過Redis在分佈式的情況下,需要對存在併發競爭的數據進行加鎖,老公們十分費解,Redis是單線程的嘛?為啥還要加鎖呢?
看來老公們還是年輕啊,你說的不需要加鎖的情況是這樣的:
單個服務去訪問Redis的時候,確實因為Redis本身單線程的原因是不用考慮線程安全的,但是,現在有哪個公司還是單機的呀?肯定都是分佈式集群了嘛。
老公們你看下這樣的場景是不是就有問題了:
你們經常不是說秒殺嘛,拿到庫存判斷,那老婆告訴你分佈式情況就是會出問題的。
我們為了減少DB的壓力,把庫存預熱到了KV,現在KV的庫存是1。
老公們是不是發現問題了,這就需要分佈式鎖的介入了,我會分三個章節去分別介紹分佈式鎖的三種實現方式(Zookeeper,Redis,MySQL),說出他們的優缺點,以及一般大廠的實踐場景。
一個騷里騷氣的面試官啥也沒拿的就走了進來,你一看,這不是你老婆嘛,你正準備叫他的時候,發現他一臉嚴肅,死鬼還裝嚴肅,肯定會給我放水的吧。
B站搜:三太子敖丙
咳咳,我們啥也不說了,開始今天的面試吧。
正常線程進程同步的機制有哪些?
那分佈式鎖你了解過有哪些么?
分佈式鎖實現主要以Zookeeper(以下簡稱zk)、Redis、MySQL這三種為主。
那先跟我聊一下zk吧,你能說一下他常見的使用場景么?
他主要的應用場景有以下幾個:
zk是啥?
他是個數據庫,文件存儲系統,並且有監聽通知機制(觀察者模式)
存文件系統,他存了什麼?
節點
zk的節點類型有4大類
持久化節點(zk斷開節點還在)
持久化順序編號目錄節點
臨時目錄節點(客戶端斷開後節點就刪除了)
臨時目錄編號目錄節點
節點名稱都是唯一的。
節點怎麼創建?
我特么,這樣問的么?可是我面試只看了分佈式鎖,我得好好想想!!!
還好我之前在自己的服務器搭建了一個zk的集群,我剛好跟大家回憶一波。
create /test laogong // 創建永久節點
那臨時節點呢?
create -e /test laogong // 創建臨時節點
臨時節點就創建成功了,如果我斷開這次鏈接,這個節點自然就消失了,這是我的一個zk管理工具,目錄可能清晰點。
如何創建順序節點呢?
create -s /test // 創建順序節點
臨時順序節點呢?
我想聰明的老公都會搶答了
create -e -s /test // 創建臨時順序節點
我退出后,重新連接,發現剛才創建的所有臨時節點都沒了。
開篇演示這麼多呢,我就是想給大家看到的zk大概的一個操作流程和數據結構,中間涉及的搭建以及其他的技能我就不說了,我們重點聊一下他在分佈式鎖中的實現。
zk就是基於節點去實現各種分佈式鎖的。
就拿開頭的場景來說,zk應該怎麼去保證分佈式情況下的線程安全呢?併發競爭他是怎麼控制的呢?
為了模擬併發競爭這樣一個情況,我寫了點偽代碼,大家可以先看看
我定義了一個庫存inventory值為1,還用到了一個CountDownLatch發令槍,等10個線程都就緒了一起去扣減庫存。
是不是就像10台機器一起去拿到庫存,然後扣減庫存了?
所有機器一起去拿,發現都是1,那大家都認為是自己搶到了,都做了減一的操作,但是等所有人都執行完,再去set值的時候,發現其實已經超賣了,我打印出來給大家看看。
是吧,這還不是超賣一個兩個的問題,超賣7個都有,代碼裏面明明判斷了庫存大於0才去減的,怎麼回事開頭我說明了。
那怎麼解決這個問題?
sync,lock也只能保證你當前機器線程安全,這樣分佈式訪問還是有問題。
上面跟大家提到的zk的節點就可以解決這個問題。
zk節點有個唯一的特性,就是我們創建過這個節點了,你再創建zk是會報錯的,那我們就利用一下他的唯一性去實現一下。
怎麼實現呢?
上面不是10個線程嘛?
我們全部去創建,創建成功的第一個返回true他就可以繼續下面的扣減庫存操作,後續的節點訪問就會全部報錯,扣減失敗,我們把它們丟一個隊列去排隊。
那怎麼釋放鎖呢?
刪除節點咯,刪了再通知其他的人過來加鎖,依次類推。
我們實現一下,zk加鎖的場景。
是不是,只有第一個線程能扣減成功,其他的都失敗了。
但是你發現問題沒有,你加了鎖了,你得釋放啊,你不釋放後面的報錯了就不重試了。
那簡單,刪除鎖就釋放掉了,Lock在finally裏面unLock,現在我們在finally刪除節點。
加鎖我們知道創建節點就夠了,但是你得實現一個阻塞的效果呀,那咋搞?
死循環,遞歸不斷去嘗試,直到成功,一個偽裝的阻塞效果。
怎麼知道前面的老哥刪除節點了嗯?
監聽節點的刪除事件
但是你發現你這樣做的問題沒?
是的,會出現死鎖。
第一個仔加鎖成功了,在執行代碼的時候,機器宕機了,那節點是不是就不能刪除了?
你要故作沉思,自問自答,時而看看遠方,時而看看面試官,假裝自己什麼都不知道。
哦我想起來了,創建臨時節點就好了,客戶端連接一斷開,別的就可以監聽到節點的變化了。
嗯還不錯,那你發現還有別的問題沒?
好像這種監聽機制也不好。
怎麼個不好呢?
你們可以看到,監聽,是所有服務都去監聽一個節點的,節點的釋放也會通知所有的服務器,如果是900個服務器呢?
這對服務器是很大的一個挑戰,一個釋放的消息,就好像一個牧羊犬進入了羊群,大家都四散而開,隨時可能幹掉機器,會佔用服務資源,網絡帶寬等等。
這就是羊群效應。
那怎麼解決這個問題?
繼續故作沉思,啊啊啊,好難,我的腦袋。。。。
你TM別裝了好不好?
好的,臨時順序節點,可以順利解決這個問題。
怎麼實現老公你先別往下看,先自己想想。
之前說了全部監聽一個節點問題很大,那我們就監聽我們的前一個節點,因為是順序的,很容易找到自己的前後。
和之前監聽一個永久節點的區別就在於,這裏每個節點只監聽了自己的前一個節點,釋放當然也是一個個釋放下去,就不會出現羊群效應了。
以上所有代碼我都會開源到我的https://github.com/AobingJava/Thanos其實上面的還有瑕疵,大家可以去拉下來改一下提交pr,我會看合適的會通過的。
你說了這麼多,挺不錯的,你能說說ZK在分佈式鎖中實踐的一些缺點么?
Zk性能上可能並沒有緩存服務那麼高。
因為每次在創建鎖和釋放鎖的過程中,都要動態創建、銷毀瞬時節點來實現鎖功能。
ZK中創建和刪除節點只能通過Leader服務器來執行,然後將數據同步到所有的Follower機器上。(這裏涉及zk集群的知識,我就不展開了,以後zk章節跟老公們細聊)
還有么?
使用Zookeeper也有可能帶來併發問題,只是並不常見而已。
由於網絡抖動,客戶端可ZK集群的session連接斷了,那麼zk以為客戶端掛了,就會刪除臨時節點,這時候其他客戶端就可以獲取到分佈式鎖了。
就可能產生併發問題了,這個問題不常見是因為zk有重試機制,一旦zk集群檢測不到客戶端的心跳,就會重試,Curator客戶端支持多種重試策略。
多次重試之後還不行的話才會刪除臨時節點。
Tip:所以,選擇一個合適的重試策略也比較重要,要在鎖的粒度和併發之間找一個平衡。
有更好的實現么?
基於Redis的分佈式鎖
能跟我聊聊么?
我看看了手上的表,老公,今天天色不早了,你全問完了,我怎麼多水幾篇文章呢?
行確實很晚了,那你回家去把家務幹了吧?
我????
=
zk通過臨時節點,解決掉了死鎖的問題,一旦客戶端獲取到鎖之後突然掛掉(Session連接斷開),那麼這個臨時節點就會自動刪除掉,其他客戶端自動獲取鎖。
zk通過節點排隊監聽的機制,也實現了阻塞的原理,其實就是個遞歸在那無限等待最小節點釋放的過程。
我上面沒實現鎖的可重入,但是也很好實現,可以帶上線程信息就可以了,或者機器信息這樣的唯一標識,獲取的時候判斷一下。
zk的集群也是高可用的,只要半數以上的或者,就可以對外提供服務了。
這周會寫完Redis和數據庫的分佈式鎖的,老公們等好。
我是敖丙,一個在互聯網苟且偷生的工具人。
最好的關係是互相成就,老公們的「三連」就是丙丙創作的最大動力,我們下期見!
注:如果本篇博客有任何錯誤和建議,歡迎老公們留言,老公你快說句話啊!
文章持續更新,可以微信搜索「 三太子敖丙 」第一時間閱讀,回復【資料】【面試】【簡歷】有我準備的一線大廠面試資料和簡歷模板,本文 GitHub https://github.com/JavaFamily 已經收錄,有大廠面試完整考點,歡迎Star。
你知道的越多,你不知道的越多
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
一.介紹
二.問題提出
2.1內存原理圖
2.2幾個問題
三.回答問題
3.1為什麼會出現內存泄漏
3.2若Entry使用弱引用
3.3弱引用配合自動回收
四.總結
之前使用ThreadLocal的時候,就聽過ThreadLocal怎麼怎麼的可能會出現內存泄漏,具體原因也沒去深究,就是一種不清不楚的狀態。最近在看JDK的源碼,其中就包含ThreadLocal,在對ThreadLocal的使用場景介紹以及源碼的分析后,對於ThreadLocal中可能存在的內存泄漏問題也搞清楚了,所以這裏專門寫一篇博客分析一下。
在分析內存泄漏之前,先了解2個概念,就是內存泄漏和內存溢出:
內存溢出(memory overflow):是指不能申請到足夠的內存進行使用,就會發生內存溢出,比如出現的OOM(Out Of Memory)
內存泄漏(memory lack):內存泄露是指在程序中已經動態分配的堆內存由於某種原因未釋放或者無法釋放(已經沒有用處了,但是沒有釋放),造成系統內存的浪費,這種現象叫“內存泄露”。
當內存泄露到達一定規模后,造成系統能申請的內存較少,甚至無法申請內存,最終導致內存溢出,所以內存泄露是導致內存溢出的一個原因。
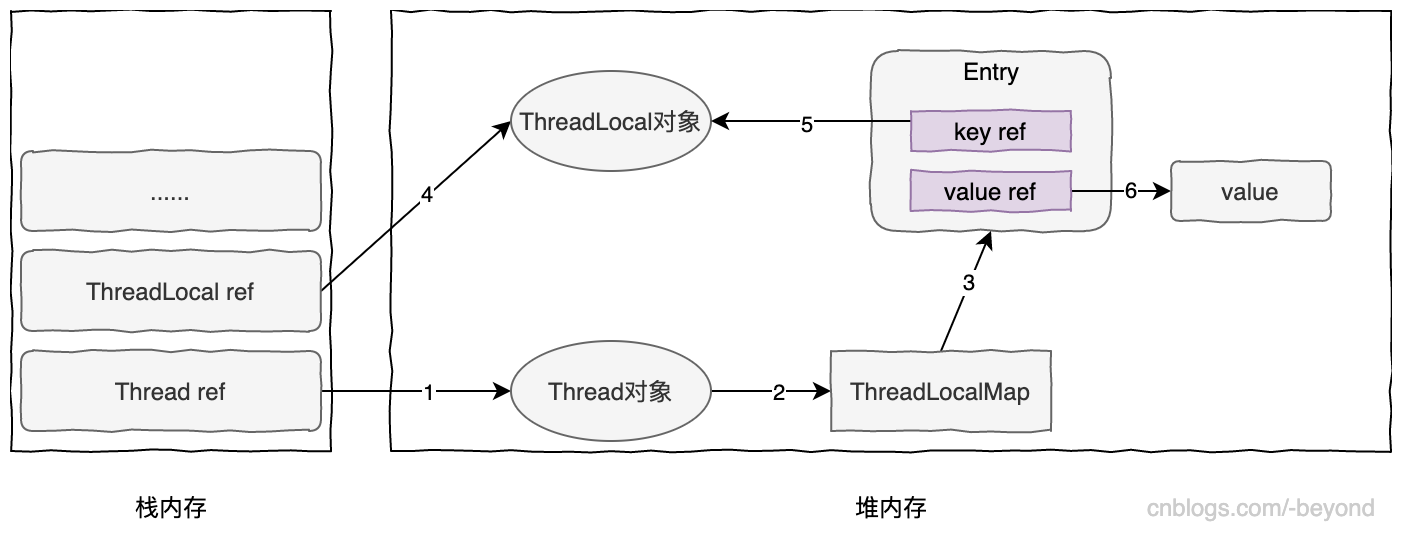
下圖是程序運行中的內存分布圖,簡要介紹一下這種圖:當前線程有一個threadLocals屬性(ThreadLocalMap屬性),該map的底層是數組,每個數組元素時Entry類型,Entry類型的key是ThreadLocal類型(也就是創建的ThreadLocal對象),而value是則是ThreadLocal.set()方法設置的value。
需要注意的是ThreadLocalMap的Entry,繼承自弱引用,定義如下,關於Java的引用介紹,可以參考:Java-強引用、軟引用、弱引用、虛引用
/**
* ThreadLocalMap中存放的元素類型,繼承了弱引用類
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
// key對應的value,注意key是ThreadLocal類型
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
在看了上面ThreadLocal和ThreadLocalMap相關的內存分佈以及關聯后,提出這樣幾個問題:
1.ThreadLocal為什麼會出現內存溢出?
2.Entry的key為什麼要用弱引用?
3.使用弱引用是否就能解決內存溢出?
為了回答上面這3個問題,我寫了一段代碼,後面根據這段代碼進行分析:
public void step1() {
// some action
step2();
step3();
// other action
}
// 在stepX中都會創建threadLocal對象
public void step2() {
ThreadLocal<String> tl = new ThreadLocal<>();
tl.set("this is value");
}
public void step3() {
ThreadLocal<Integer> tl = new ThreadLocal<>();
tl.set(99);
}
在step1中會調用step2和step3,step2和step3都會創建ThreadLocal對象,當step2和step3執行完畢后,其中的棧內存中ThreadLocal引用就會被清除。
現在針對這個圖,一步一步的分析問題,中途會得出一些臨時的結論,但是最終的結論才是正確的。
現在有2點假設,本小節的分析都是基於這兩個假設之上的:
1.Entry的key使用強引用,key對ThreadLocal對象使用強引用,也就是上面圖中連線5是強引用(key強引用ThreadLocal對象);
2.ThreadLocalMap中不會對過期的Entry進行清理。
上面代碼中,如果ThreadLocalMap的key使用強引用,那麼即使棧內存的ThreadLocal引用被清除,但是堆中的ThreadLocal對象卻並不會被清除,這是因為ThreadLocalMap中Entry的key對ThreadLocal對象是強引用。
如果當前線程不結束,那麼堆中的ThreadLocal對象將會一直存在,對應的內存就不會被回收,與之關聯的Entry也不會被回收(Entry對應的value也不會被回收),當這種情況出現數量比較多的時候,未釋放的內存就會上升,就可能出現內存泄漏的問題。
上面的結論是暫時的,有前提假設!!!最終結論還需要看後面分析。
仍舊有1個假設,就是ThreadLocalMap中不會對過期的Entry進行清理,陳舊的Entry是指Entry的key為null。
按照源碼,Entry繼承弱引用,其Key對ThreadLocal是弱引用,也就是上圖中連線5是弱引用,連線6仍為強引用。
同樣以上面代碼為例,step2和step3創建了ThreadLocal對象,step2和step3執行完后,棧中的ThreadLocal引用被清除了;由於堆內存中ThreadLocalMap的Entry key弱引用ThreadLocal對象,根據垃圾收集器對弱引用對象的處理:
當垃圾收集器工作時,無論當前內存是否足夠,都會回收掉只被弱引用關聯的對象。
此時堆中ThreadLocal對象會被gc回收(因為現在沒有對ThreadLocal的強引用,只有一個弱引用ThreadLocal對象),Entry的key為null,但是value不為null,且value也是強引用(連線6),所以Entry仍舊不能回收,只能釋放ThreadLocal的內存,仍舊可能導致內存泄漏。
在沒有自動清理陳舊Entry的前提下,即使Entry使用弱引用,仍可能出現內存泄漏。
通過3.2的分析,其實只要陳舊的Entry能自動被回收,就能解決內存泄漏的問題,其實JDK就是這麼做的。
如果看過源碼,就知道,ThreadLocalMap底層使用數組來保存元素,使用“線性探測法”來解決hash衝突,關於線性探測法的介紹可以查看:利用線性探測法解決hash衝突
在每次調用ThreadLocal類的get、set、remove這些方法的時候,內部其實都是對ThreadLocalMap進行操作,對應ThreadLocalMap的get、set、remove操作。
重點來了!重點來了!重點來了!
ThreadLocalMap的每次get、set、remove,都會清理過期的Entry,下面以get操作解釋,其他操作也是一個意思,大致如下:
1.ThreadLocalMap底層用數組保存元素,當get一個Entry時,根據key的hash值(非hashCode)計算出該Entry應該出在什麼位置;
2.計算出的位置可能會有衝突,比如預期位置是position=5,但是position=5的位置已經有其他Entry了;
3.出現衝突后,會使用線性探測法,找position=6位置上的Entry是否匹配(匹配是指hash相同),如果匹配,則返回position=6的Entry。
4.在這個過程中,如果position=5位置上的Entry已經是陳舊的Entry(Entry的key為null),此時position=5的key就應該被清理;
5.光清理position=5的Entry還不夠,為了保證線性探測法的規則,需要判斷數組中的其他元素是否需要調整位置(如果需要,則調整位置),在這個過程中,也會進行清理陳舊Entry的操作。
上面這5個步驟就保證了每次get都會清理數組中(map)的陳舊Entry,清理一個陳舊的Entry,就是下面這三行代碼:
Entry.value = null; // 將Entry的value設為null table[index] = null;// 將數組中該Entry的位置設置null size--; // map的size減一
對於ThreadLocal的set、remove也類似這個原理。
有了自動回收陳舊Entry的操作,需要注意的是,在這個時候,key使用弱引用就是至關重要的一點!!!
因為key使用弱引用后,當弱引用的ThreadLocal對象被會回收后,該key的引用為null,則該Entry在下一次get、set、remove的時候就才會被清理,從未避免內存泄漏的問題。
在上面的分析中,看到ThreadLocal基本不會出現內存泄漏的問題了,因為ThreadLocalMap中會在get、set、remove的時候清理陳舊的Entry,與Entry的key使用弱引用密不可分。
當然我們也可以在代碼中手動調用ThreadLocal的remove方法進行清除map中key為該threadLocal對象的Entry,同時清理過期的Entry。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
轉載請保留以下聲明
作者: 趙宗晟
出處: https://www.cnblogs.com/zhao-zongsheng/p/13067733.html
很多軟件都要做性能分析和性能優化。很多語言都會有他的性能分析工具,例如如果優化C++的性能,我們可以用Visual Studio自帶的性能探測器,或者使用Intel VTune Profiler。了解性能分析工具的原理有助於了解工具給出的數據與結果,也能幫助我們在遇到異常結果時排查哪裡出了問題。這篇博客簡單總結一下常見的性能分析工具原理。
性能分析工具大部分都可以分為下面幾類
基於採樣的分析器會每隔一個固定時間間隔暫停所有線程的執行,然後分析有哪些線程正在執行,那些線程處於就緒狀態。對於這類線程,我們記錄每個線程的調用堆棧,以及其他需要的信息。我們稱這個行為為一次採樣,記錄下來的每個堆棧為一個樣本。然後在結束性能分析的時候我們統計記錄下載的堆棧,看每個堆棧被記錄了多少次,或者每個函數被記錄了多少次。統計學告訴我們,那些執行時間比較長的函數、堆棧,被記錄的次數會更多。如果堆棧A被記錄了200次,堆棧B被記錄了100次,那麼堆棧B的執行時間是堆棧A的2倍。我們可以計算某個堆棧樣本的數量佔總樣本數的比例,這個比例就是堆棧執行時間的佔比。用Visual Studio的性能探測器我們看到的百分比和数字就是值樣本的佔比(也就是時間佔比)和樣本次數。
很多性能分析工具都是基於採樣的方式。運行性能分析器是會影響被測程序的性能的,而基於採樣的有點是對性能影響比較小,不需要重新編譯程序,非常方便。
插裝是指通過修改程序,往裡面加入性能分析相關代碼,來收集、監控相關性能指標。例如我們可以在一個函數的開頭寫下計數代碼,我們就可以知道在運行中這個函數被執行了多少次。一般來說基於插裝的性能分析更為準確,但是對性能影響比較大。因為需要修改代碼,所以也不是很方便。另外,基於插裝的分析也可能會引起海森堡bug(heisenbug)。海森堡bug是指當你再運行程序的時候能遇到這個bug,但是試圖定位這個bug時卻遇不到這個bug。這個bug往往是因為在定位bug時修改了軟件的運行環境/流程,導致軟件執行和生產時不一樣,於是就遇不到這個bug了。這個命名的來源很有意思,海森堡是量子力學的著名科學家,他提出了不確定性原理,以及觀察者理論。這個理論認為,觀察會影響例子的狀態,導致觀察粒子和不觀察粒子會導致不同的結果,這個和海森堡bug的情形非常相似。關於觀察者理論,有興趣的人可以再了解一下。
回到正題,基於插裝也可以再進行劃分:
在軟件執行過程中,可能會拋出某些事件。我們通過統計事件出現的次數,事件出現的時機,可以得到軟件的某些性能指標。事件又可以分為軟件事件和硬件事件。軟件事件比如Java可以在class-load的時候拋出事件。硬件事件則是使用專門的性能分析硬件。現在很多CPU裏面都有用於分析性能的性能監控單元(PMU),PMU本身是一個寄存器,在某個事件發生時寄存器裏面的值會+1。例如我們可以設置為當運行中發生memory cache miss的時候PMU寄存器+1,這樣我們就知道一段時間內發生了多少次memory cache miss。性能分析器使用PMU時,會給PMU設置需要統計的事件類型,以及Sample After Value (SAV)。SAV是指寄存器達到什麼值之後出發硬件中斷。例如,我們可以給PMU設置SAV為2000,統計事件為memory cache miss。那麼當cache miss發生2000次時,發生硬件中斷。這個時候性能分析器就可以收集CPU的IP,調用堆棧,進程ID等等信息,分析器結束時進行統計分析。
基於硬件事件的優點是,對被測程序的影響非常小,比基於採樣還小,可以使用更短的時間間隔收集信息,而且可以收集CPU的非常重要的性能指標,例如cache miss,分支預測錯誤,等等。
但是基於硬件事件的分析器也有它的一些問題,導致數據上的誤差:
這幾個就是比較常見的性能分析方法。我們知道了性能分析的原理,可以更好地理解性能分析器給出的結果,也可以在出現明顯異常的結果時,分析判斷可能的原因,針對性的解決。
https://en.wikipedia.org/wiki/Profiling_(computer_programming)
https://software.intel.com/content/www/us/en/develop/articles/understanding-how-general-exploration-works-in-intel-vtune-amplifier-xe.html
https://software.intel.com/content/www/us/en/develop/documentation/vtune-help/top/analyze-performance/user-mode-sampling-and-tracing-collection.html
https://software.intel.com/content/www/us/en/develop/documentation/vtune-help/top/analyze-performance/hardware-event-based-sampling-collection.html
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!

聽瑪莎拉蒂堅持與寶華韋健合作隨車打造的音響系統可以帶給你在聽覺上殿堂級的享受,甚至可以調整側重地方,比如往後排照顧,就可以向後排調節,能輕易分出前排後排的區別。最神奇的是,經過無數次調校之後,發動機艙傳來的聲浪並不會影響音響效果,甚至會相互加成,帶給你獨特的聽覺享受。
瑪莎拉蒂,一個最喜愛的超豪華品牌,沒有之一。在有的人眼裡,瑪莎拉蒂是個跑車裡的異類,沒有讓人驚艷的百公里加速成績,沒有讓人眼前一亮的高科技配置,更沒有跑車具有的戰鬥姿態,但是,可以告訴你,瑪莎拉蒂具有的是其他品牌所沒有的一種浪漫,把豪華、運動、享受都融合在一起的意式浪漫。
在這次北京車展專門跑去瑪莎拉蒂展台個性化配置專區感受一番這種浪漫情懷,並通過看、聽、聞、觸、味全方位體驗。
看
看瑪莎拉蒂全系車型就是一種享受,造型不僅獨特個性,且在不經意間會發現瑪莎拉蒂融入車裡的品牌造型,比如,你會發現在輪轂的形狀就是圍繞瑪莎拉蒂的標誌(海神三叉戟)而設計。並且全系車型都接受定製,從車身顏色、車漆種類、輪轂、制動卡鉗到內飾材料、多功能方向盤、豪華還是運動座椅、座椅面料等等,無不體現屬於自己的個性訂製。
聽
瑪莎拉蒂堅持與寶華韋健合作隨車打造的音響系統可以帶給你在聽覺上殿堂級的享受,甚至可以調整側重地方,比如往後排照顧,就可以向後排調節,能輕易分出前排後排的區別。最神奇的是,經過無數次調校之後,發動機艙傳來的聲浪並不會影響音響效果,甚至會相互加成,帶給你獨特的聽覺享受。
聞
意大利頂級皮革帶給車內獨特的芳香,讓駕駛者更覺舒適,展台專門聘請的咖啡師調出香濃的意式咖啡,帶來極致的享受。
觸
意大利頂級皮革以及精緻的手工縫製,無一不在體現瑪莎拉蒂在工藝方面的水平以及造車的誠意。
味
最後,在瑪莎拉蒂個性化配置專區還提供了頂級廚師烹飪的意大利美食,開啟味覺享受的同時也結束了本次瑪莎拉蒂的體驗之旅。
瑪莎拉蒂,一個百年來始終堅持做自己的個性品牌,這是喜歡它的原因,有人說,瑪莎拉蒂是一個“全靠浪(聲浪)”的品牌,這個說法對也不對,不可否認,瑪莎拉蒂在聲浪方面所下的功夫確實無人能敵,但是其在豪華體驗上也是讓人不得不翹起個大拇指說“Good”!本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準

實在是難為了造車的車企,由此催生出的“全能选手”也是越來越多。
大家發現了么,現在純粹的車好像越來越少了。
前些年總流行混搭、串燒,如今說的好聽了一些叫跨界、融合,車型上有SUV跨界轎車,更有SUV跨界MpV;定位上更是注重全面,要運動也要舒適,想豪華也想家用,求動力強也求夠省油…實在是難為了造車的車企,由此催生出的“全能选手”也是越來越多…
本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?

Quick Start: https://spark.apache.org/docs/latest/quick-start.html
在Spark 2.0之前,Spark的編程接口為RDD (Resilient Distributed Dataset)。而在2.0之後,RDDs被Dataset替代。Dataset很像RDD,但是有更多優化。RDD仍然支持,不過強烈建議切換到Dataset,以獲得更好的性能。 RDD文檔: https://spark.apache.org/docs/latest/rdd-programming-guide.html Dataset文檔: https://spark.apache.org/docs/latest/sql-programming-guide.html
scala> val textFile = spark.read.textFile("README.md") # 構建一個Dataset textFile: org.apache.spark.sql.Dataset[String] = [value: string] scala> textFile.count() # Dataset的簡單計算 res0: Long = 104 scala> val linesWithSpark = textFile.filter(line => line.contain("Spark")) # 由現有Dataset生成新Dataset res1: org.apache.spark.sql.Dataset[String] = [value: string] # 等價於: # res1 = new Dataset() # for line in textFile: # if line.contain("Spark"): # res1.append(line) # linesWithSpark = res1 scala> linesWithSpark.count() res2: Long = 19 # 可以將多個操作串行起來 scala> textFile.filter(line => line.contain("Spark")).count() res3: Long = 19
進一步的Dataset分析:
scala> textFile.map(line => line.split(" ").size).reduce((a,b) => if (a > b) a else b) res12: Int = 16 # 其實map和reduce就是兩個普通的算子,不要被MapReduce中一個map配一個reduce、先map后reduce的思想所束縛 # map算子就是對Dataset的元素X計算fun(X),並且將所有f(X)作為新的Dataset返回 # reduce算子其實就是通過兩兩計算fun(X,Y)=Z,將Dataset中的所有元素歸約為1個值 # 也可以引入庫進行計算 scala> import java.lang.Math import java.lang.Math scala> textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b)) res14: Int = 16 # 還可以使用其他算子 scala> val wordCounts = textFile.flatMap(line => line.split(" ")).groupByKey(identity).count() # flatMap算子也是對Dataset的每個元素X執行fun(X)=Y,只不過map的res是 # res.append(Y),如[[Y11, Y12], [Y21, Y22]],結果按元素區分 # 而flatMap是 # res += Y,如[Y11, Y12, Y21, Y22],各元素結果合在一起 # groupByKey算子將Dataset的元素X作為參數傳入進行計算f(X),並以f(X)作為key進行分組,返回值為KeyValueGroupedDataset類型 # 形式類似於(key: k; value: X1, X2, ...),不過KeyValueGroupedDataset不是一個Dataset,value列表也不是一個array # 注意:這裏的textFile和textFile.flatMap都是Dataset,不是RDD,groupByKey()中可以傳func;如果以sc.textFile()方法讀文件,得到的是RDD,groupByKey()中間不能傳func # identity就是函數 x => x,即返回自身的函數 # KeyValueGroupedDataset的count()方法返回(key, len(value))列表,結果是Dataset類型 scala> wordCounts.collect() res37: Array[(String, Long)] = Array((online,1), (graphs,1), ... # collect操作:將分佈式存儲在集群上的RDD/Dataset中的所有數據都獲取到driver端
數據的cache:
scala> linesWithSpark.cache() # in-memory cache,讓數據在分佈式內存中緩存 res38: linesWithSpark.type = [value: string] scala> linesWithSpark.count() res41: Long = 19
需提前安裝sbt,sbt是scala的編譯工具(Scala Build Tool),類似java的maven。 brew install sbt 1)編寫SimpleApp.scala
import org.apache.spark.sql.SparkSession object SimpleApp { def main(args: Array[String]) { val logFile = "/Users/dxm/work-space/spark-2.4.5-bin-hadoop2.7/README.md" val spark = SparkSession.builder.appName("Simple Application").getOrCreate() val logData = spark.read.textFile(logFile).cache() val numAs = logData.filter(line => line.contains("a")).count() # 包含字母a的行數 val numBs = logData.filter(line => line.contains("b")).count() # 包含字母b的行數 println(s"Lines with a: $numAs, Lines with b: $numBs") spark.stop() } }
2)編寫sbt依賴文件build.sbt
name := "Simple Application" version := "1.0" scalaVersion := "2.12.10" libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.5"
其中,”org.apache.spark” %% “spark-sql” % “2.4.5”這類庫名可以在網上查到,例如https://mvnrepository.com/artifact/org.apache.spark/spark-sql_2.10/1.0.0
3)使用sbt打包 目錄格式如下,如果SimpleApp.scala和build.sbt放在一個目錄下會編不出來
$ find . . ./build.sbt ./src ./src/main ./src/main/scala ./src/main/scala/SimpleApp.scala
sbt目錄格式要求見官方文檔 https://www.scala-sbt.org/1.x/docs/Directories.html
src/
main/
resources/
<files to include in main jar here>
scala/
<main Scala sources>
scala-2.12/
<main Scala 2.12 specific sources>
java/
<main Java sources>
test/
resources
<files to include in test jar here>
scala/
<test Scala sources>
scala-2.12/
<test Scala 2.12 specific sources>
java/
<test Java sources>
使用sbt打包
# 打包 $ sbt package ... [success] Total time: 97 s (01:37), completed 2020-6-10 10:28:24 # jar包位於 target/scala-2.12/simple-application_2.12-1.0.jar
4)提交並執行Spark任務
$ bin/spark-submit --class "SimpleApp" --master spark://xxx:7077 ../scala-tests/SimpleApp/target/scala-2.12/simple-application_2.12-1.0.jar # 報錯:Caused by: java.lang.ClassNotFoundException: scala.runtime.LambdaDeserialize # 參考:https://stackoverflow.com/questions/47172122/classnotfoundexception-scala-runtime-lambdadeserialize-when-spark-submit # 這是spark版本和scala版本不匹配導致的
查詢spark所使用的scala的版本
$ bin/spark-shell --master spark://xxx:7077 scala> util.Properties.versionString res0: String = version 2.11.12
修改build.sbt: scalaVersion := “2.11.12” 從下載頁也可驗證,下載的spark 2.4.5使用的是scala 2.11
重新sbt package,產出位置變更為target/scala-2.11/simple-application_2.11-1.0.jar 再次spark-submit,成功
$ bin/spark-submit --class "SimpleApp" --master spark://xxx:7077 ../scala-tests/SimpleApp/target/scala-2.11/simple-application_2.11-1.0.jar Lines with a: 61, Lines with b: 30
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準

——永遠不要在OJ上使用值元編程,過於簡單的沒有優勢,能有優勢的編譯錯誤。
2019年10月,我在學習算法。有一道作業題,輸入規模很小,可以用打表法解決。具體方案有以下三種:
運行時預處理,生成所需的表格,根據輸入直接找到對應項,稍加處理后輸出;
一個程序生成表格,作為提交程序的一部分,後續與方法1相同,這樣就省去了運行時計算的步驟;
以上兩種方法結合,編譯期計算表格,運行時直接查詢,即元編程(metaprogramming)。
做題當然是用方法1或2,但是元編程已經埋下了種子。時隔大半年,我來補上這個坑。
北京大學OpenJudge 百練4119 複雜的整數劃分問題
將正整數 \(n\) 表示成一系列正整數之和,\(n = n_1 + n_2 + … + n_k\),其中 \(n_1 \geq n_2 \geq … \geq n_k \geq 1\),\(k \geq 1\)。正整數 \(n\) 的這種表示稱為正整數 \(n\) 的劃分。
標準的輸入包含若干組測試數據。每組測試數據是一行輸入數據,包括兩個整數 \(N\) 和 \(K\)。( \(0 \le N \leq 50\),\(0 \le K \leq N\) )
對於每組測試數據,輸出以下三行數據:
第一行: \(N\) 劃分成 \(K\) 個正整數之和的劃分數目
第二行: \(N\) 劃分成若干個不同正整數之和的劃分數目
第三行: \(N\) 劃分成若干個奇正整數之和的劃分數目
5 2
2
3
3
第一行: 4+1,3+2
第二行: 5,4+1,3+2
第三行: 5,1+1+3,1+1+1+1+1+1
標準的動態規劃題。用dp[c][i][j]表示把i分成c個正整數之和的方法數,其中每個數都不超過j。
第一行。初始化:由 \(i \leq j\) 是否成立決定dp[1][i][j]的值,當 \(i \leq j\) 時為1,劃分為 \(i = i\),否則無法劃分,值為0。
遞推:為了求dp[c][i][j],對 \(i = i_1 + i_2 + … + i_c\),\(i_1 \geq i_2 \geq … \geq i_c\) 中的最大數 \(i_1\) 分類討論,最小為 \(1\),最大不超過 \(i – 1\),因為 \(c \geq 2\),同時不超過 \(j\),因為定義。最大數為 \(n\) 時,對於把 \(i – n\) 分成 \(c – 1\) 個數,每個數不超過 \(n\) 的劃分,追加上 \(n\) 可得 \(i\) 的一個劃分。\(n\) 只有這些取值,沒有漏;對於不同的 \(n\),由於最大數不一樣,兩個劃分也不一樣,沒有多。故遞推式為:
\[dp[c][i][j] = \sum_{n=1}^{min\{i-1,j\}}dp[c-1][i-n][n] \]
dp[K][N][N]即為所求ans1[K][N]。
第二行。可以把遞推式中的dp[c - 1][i - n][n]修改為dp[c - 1][i - n][n - 1]后重新計算。由於只需一個與c無關的結果,可以省去c這一維度,相應地改變遞推順序,每輪累加。
另一種方法是利用已經計算好的ans1數組。設 \(i = i_1 + i_2 + … + + i_{c-1} + i_c\),其中 \(i_1 \ge i_2 \ge … \ge i_{c+1} \ge i_c \ge 0\),則 \(i_1 – \left( c-1 \right) \geq i_2 – \left( c-2 \right) \geq … \geq i_{c-1} – 1 \geq i_c \ge 0\),且 \(\left( i_1 – \left( c-1 \right) \right) + \left( i_2 – \left( c-2 \right) \right) + … + \left( i_{c-1} – 1 \right) + \left( i_c \right) = i – \frac {c \left( c-1 \right)} {2}\),故把i劃分成c個不同正整數之和的劃分數目等於ans[c][i - c * (c - 1) / 2],遍歷c累加即得結果。
第三行。想法與第二行相似,也是找一個對應,此處從略。另外,數學上可以證明,第二行和第三行的結果一定是一樣的。
#include <iostream>
#include <algorithm>
constexpr int max = 50;
int dp[max + 1][max + 1][max + 1] = { 0 };
int ans1[max + 1][max + 1] = { 0 };
int ans2[max + 1] = { 0 };
int ans3[max + 1] = { 0 };
int main()
{
int num, k;
for (int i = 1; i <= max; ++i)
for (int j = 1; j <= max; ++j)
dp[1][i][j] = i <= j;
for (int cnt = 2; cnt <= max; ++cnt)
for (int i = 1; i <= max; ++i)
for (int j = 1; j <= max; ++j)
{
auto min = std::min(i - 1, j);
for (int n = 1; n <= min; ++n)
dp[cnt][i][j] += dp[cnt - 1][i - n][n];
}
for (int cnt = 1; cnt <= max; ++cnt)
for (int i = 1; i <= max; ++i)
ans1[cnt][i] = dp[cnt][i][i];
for (int i = 1; i <= max; ++i)
for (int cnt = 1; cnt <= i; ++cnt)
{
int j = i - cnt * (cnt - 1) / 2;
if (j <= 0)
break;
ans2[i] += ans1[cnt][j];
}
for (int i = 1; i <= max; ++i)
for (int cnt = 1; cnt <= i; ++cnt)
{
int j = i + cnt;
if (j % 2)
continue;
j /= 2;
ans3[i] += ans1[cnt][j];
}
while (std::cin >> num)
{
std::cin >> k;
std::cout << ans1[k][num] << std::endl;
std::cout << ans2[num] << std::endl;
std::cout << ans3[num] << std::endl;
}
}
元編程是指計算機程序能把其他程序作為它們的數據的編程技術。在目前的C++中,元編程體現為用代碼生成代碼,包括宏與模板。當我們使用了std::vector<int>中的任何一個名字時,std::vector類模板就用模板參數int, std::allocator<int>實例化為std::vector<int, std::allocator<int>>模板類,這是一種元編程,不過我們通常不這麼講。
狹義的C++模板元編程(template metaprogramming,TMP)包括值元編程、類型元編程,以及兩者的相交。本文討論的是值元編程,即為編譯期值編程。
在C++中有兩套工具可用於值元編程:模板和constexpr。C++模板是圖靈完全的,這是模板被引入C++以後才被發現的,並不是C++模板的初衷,因此用模板做計算在C++中算不上一等用法,導致其語法比較冗長複雜。constexpr的初衷是提供純正的編譯期常量,後來才取消對計算的限制,但不能保證計算一定在編譯期完成。總之,這兩套工具都不完美,所以本文都會涉及。
嚴格來說,constexpr不符合上述對元編程的定義,但它確實可以提供運行時程序需要的數據,所以也歸入元編程的類別。
從constexpr開始講,是因為它與我們在C++中慣用的編程範式——過程式範式是一致的。
constexpr關鍵字在C++11中被引入。當時,constexpr函數中只能包含一條求值語句,就是return語句,返回值可以用於初始化constexpr變量,作模板參數等用途。如果需要分支語句,用三目運算符?:;如果需要循環語句,用函數遞歸實現。比如,計算階乘:
constexpr int factorial(int n)
{
return n <= 1 ? 1 : (n * factorial(n - 1));
}
對於編譯期常量i,factorial(i)產生編譯期常量;對於運行時值j,factorial(j)產生運行時值,也就是說,constexpr可以視為對既有函數的附加修飾。
然而,多數函數不止有一句return語句,constexpr對函數體的限制使它很難用於中等複雜的計算任務,為此C++14放寬了限制,允許定義局部變量,允許if-else、switch-case、while、for等控制流。factorial函數可以改寫為:
constexpr int factorial(int n)
{
int result = 1;
for (; n > 1; --n)
result *= n;
return result;
}
也許你會覺得factorial函數的遞歸版本比循環版本易懂,那是因為你學習遞歸時接觸的第一個例子就是它。對於C++開發者來說,大多數情況下首選的還是循環。
計算單個constexpr值用C++14就足夠了,但是傳遞數組需要C++17,因為std::array的operator[]從C++17開始才是constexpr的。
整數劃分問題的constexpr元編程實現需要C++17標準:
#include <iostream>
#include <utility>
#include <array>
constexpr int MAX = 50;
constexpr auto calculate_ans1()
{
std::array<std::array<std::array<int, MAX + 1>, MAX + 1>, MAX + 1> dp{};
std::array<std::array<int, MAX + 1>, MAX + 1> ans1{};
constexpr int max = MAX;
for (int i = 1; i <= max; ++i)
for (int j = 1; j <= max; ++j)
dp[1][i][j] = i <= j;
for (int cnt = 2; cnt <= max; ++cnt)
for (int i = 1; i <= max; ++i)
for (int j = 1; j <= max; ++j)
{
auto min = std::min(i - 1, j);
for (int n = 1; n <= min; ++n)
dp[cnt][i][j] += dp[cnt - 1][i - n][n];
}
for (int cnt = 1; cnt <= max; ++cnt)
for (int i = 1; i <= max; ++i)
ans1[cnt][i] = dp[cnt][i][i];
return ans1;
}
constexpr auto calculate_ans2()
{
constexpr auto ans1 = calculate_ans1();
std::array<int, MAX + 1> ans2{};
constexpr int max = MAX;
for (int i = 1; i <= max; ++i)
for (int cnt = 1; cnt <= i; ++cnt)
{
int j = i - cnt * (cnt - 1) / 2;
if (j <= 0)
break;
ans2[i] += ans1[cnt][j];
}
return ans2;
}
int main()
{
constexpr auto ans1 = calculate_ans1();
constexpr auto ans2 = calculate_ans2();
for (int cnt = 1; cnt <= 10; ++cnt)
{
for (int i = 1; i <= 10; ++i)
std::cout << ans1[cnt][i] << ' ';+
std::cout << std::endl;
}
std::cout << std::endl;
for (int i = 1; i <= 50; ++i)
std::cout << ans2[i] << ' ';
std::cout << std::endl;
int num, k;
while (std::cin >> num)
{
std::cin >> k;
std::cout << ans1[k][num] << std::endl;
std::cout << ans2[num] << std::endl;
std::cout << ans2[num] << std::endl;
}
}
模板式與C++11中的constexpr式類似,必須把循環化為遞歸。事實上C++模板是一門函數式編程語言,對值元編程和類型元編程都是如此。
程序控制流有三種基本結構:順序、分支與循環。
在函數式編程中,數據都是不可變的,函數總是接受若干參數,返回若干結果,參數和結果是不同的變量;修改原來的變量是不允許的。對於C++模板這門語言,函數是類模板,也稱“元函數”(metafunction);參數是模板參數;運算結果是模板類中定義的靜態編譯期常量(在C++11以前,常用enum來定義;C++11開始用constexpr)。
比如,對於參數 \(x\),計算 \(x + 1\) 和 \(x ^ 2\) 的元函數:
template<int X>
struct PlusOne
{
static constexpr int value = X + 1;
};
template<int X>
struct Square
{
static constexpr int value = X * X;
};
這裏假定運算數的類型為int。從C++17開始,可以用auto聲明非類型模板參數。
順序結構,是對數據依次進行多個操作,可以用函數嵌套來實現:
std::cout << PlusOne<1>::value << std::endl;
std::cout << Square<2>::value << std::endl;
std::cout << Square<PlusOne<3>::value>::value << std::endl;
std::cout << PlusOne<Square<4>::value>::value << std::endl;
或者藉助constexpr函數,回歸熟悉的過程式範式:
template<int X>
struct SquareAndIncrease
{
static constexpr int calculate()
{
int x = X;
x = x * x;
x = x + 1;
return x;
}
static constexpr int value = calculate();
};
void f()
{
std::cout << SquareAndIncrease<5>::value << std::endl;
}
過程式方法同樣可以用於分支和循環結構,以下省略;函數式方法可以相似地用於值元編程與類型元編程,所以我更青睞(主要還是逼格更高)。
C++模板元編程實現分支的方式是模板特化與模板參數匹配,用一個額外的帶默認值的bool類型模板參數作匹配規則,特化false或true的情形,另一種情形留給主模板。
比如,計算 \(x\) 的絕對值:
template<int X, bool Pos = (X > 0)>
struct AbsoluteHelper
{
static constexpr int value = X;
};
template<int X>
struct AbsoluteHelper<X, false>
{
static constexpr int value = -X;
};
如果你怕用戶瞎寫模板參數,可以再包裝一層:
template<int X>
struct Absolute : AbsoluteHelper<X> { };
void g()
{
std::cout << Absolute<6>::value << std::endl;
std::cout << Absolute<-7>::value << std::endl;
}
標準庫提供了std::conditional及其輔助類型std::conditional_t用於模板分支:
template<bool B, class T, class F>
struct conditional;
定義了成員類型type,當B == true時為T,否則為F。
模板匹配實際上是在處理switch-case的分支,bool只是其中一種簡單情況。對於對應關係不太規則的分支語句,可以用一個constexpr函數把參數映射到一個整數或枚舉上:
enum class Port_t
{
PortB, PortC, PortD, PortError,
};
constexpr Port_t portMap(int pin)
{
Port_t result = Port_t::PortError;
if (pin < 0)
;
else if (pin < 8)
result = Port_t::PortD;
else if (pin < 14)
result = Port_t::PortB;
else if (pin < 20)
result = Port_t::PortC;
return result;
}
template<int Pin, Port_t Port = portMap(Pin)>
struct PinOperation;
template<int Pin>
struct PinOperation<Pin, Port_t::PortB> { /* ... */ };
template<int Pin>
struct PinOperation<Pin, Port_t::PortC> { /* ... */ };
template<int Pin>
struct PinOperation<Pin, Port_t::PortD> { /* ... */ };
如果同一個模板有兩個參數分別處理兩種分支(這已經從分支上升到模式匹配了),或同時處理分支和循環的特化,總之有兩個或以上維度的特化,需要注意兩個維度的特化是否會同時滿足,如果有這樣的情形但沒有提供兩參數都特化的模板特化,編譯會出錯。見problem2::Accumulator,它不需要提供兩個參數同時特化的版本。
如前所述,循環要化為遞歸,循環的開始與結束是遞歸的起始與終點或兩者對調,遞歸終點的模板需要特化。比如,還是計算階乘:
template<int N>
struct Factorial
{
static constexpr int value = N * Factorial<N - 1>::value;
};
template<>
struct Factorial<0>
{
static constexpr int value = 1;
};
或許階乘的遞歸定義很大程度上來源於數學,那就再看一個平方和的例子:
template<int N>
struct SquareSum
{
static constexpr int value = SquareSum<N - 1>::value + N * N;
};
template<>
struct SquareSum<0>
{
static constexpr int value = 0;
};
(\(1^2 + 2^2 + \cdots + n^2 = \frac {n \left( n + 1 \right) \left( 2n + 1\right)} {6}\))
好吧,還是挺數學的,去下面看實例感覺一下吧,那裡還有break——哦不,被我放到思考題中去了。
加群是交換群,求和順序不影響結果,上面這樣的順序寫起來方便。有些運算符不滿足交換律,需要逆轉順序。還以平方和為例:
template<int N, int Cur = 0>
struct SquareSumR
{
static constexpr int value = Cur * Cur + SquareSumR<N, Cur + 1>::value;
};
template<int N>
struct SquareSumR<N, N>
{
static constexpr int value = N * N;
};
遞歸在過程式中是一種高級的結構,它可以直接轉化為函數式的遞歸,後面會提到兩者的異同。
比如,計算平方根,這個例子來源於C++ Templates: The Complete Guide 2e:
// primary template for main recursive step
template<int N, int LO = 1, int HI = N>
struct Sqrt {
// compute the midpoint, rounded up
static constexpr auto mid = (LO + HI + 1) / 2;
// search a not too large value in a halved interval
using SubT = std::conditional_t<(N < mid * mid),
Sqrt<N, LO, mid - 1>,
Sqrt<N, mid, HI>>;
static constexpr auto value = SubT::value;
};
// partial specialization for end of recursion criterion
template<int N, int S>
struct Sqrt<N, S, S> {
static constexpr auto value = S;
};
這個遞歸很容易化為循環,有助於你對循環化遞歸的理解。
實際應用中我們可能不需要把所有計算出來的值存儲起來,但在打表的題目中需要。存儲一系列數據需要用循環,循環的實現方式依然是遞歸。比如,存儲階乘(Factorial類模板見上):
template<int N>
inline void storeFactorial(int* dst)
{
storeFactorial<N - 1>(dst);
dst[N] = Factorial<N>::value;
}
template<>
inline void storeFactorial<-1>(int* dst)
{
;
}
void h()
{
constexpr int MAX = 10;
int factorial[MAX + 1];
storeFactorial<MAX>(factorial);
for (int i = 0; i <= MAX; ++i)
std::cout << factorial[i] << ' ';
std::cout << std::endl;
}
多維數組同理,例子見下方。注意,函數模板不能偏特化,但有靜態方法的類模板可以,這個靜態方法就充當原來的模板函數。
雖然我們是對數組中的元素挨個賦值的,但編譯器的生成代碼不會這麼做,即使不能優化成所有數據一起用memcpy,至少能做到一段一段拷貝。
類內定義的函數隱式成為inline,手動寫上inline沒有語法上的意義,但是對於一些編譯器,寫上以後函數被內聯的可能性更高,所以寫inline是一個好習慣。
#include <iostream>
#include <algorithm>
constexpr int MAX = 50;
namespace problem1
{
template<int Count, int Num, int Max>
struct Partition;
template<int Count, int Num, int Loop>
struct Accumulator
{
static constexpr int value = Accumulator<Count, Num, Loop - 1>::value + Partition<Count, Num - Loop, Loop>::value;
};
template<int Count, int Num>
struct Accumulator<Count, Num, 0>
{
static constexpr int value = 0;
};
template<int Count, int Num, int Max = Num>
struct Partition
{
static constexpr int value = Accumulator<Count - 1, Num, std::min(Num - 1, Max)>::value;
};
template<int Num, int Max>
struct Partition<1, Num, Max>
{
static constexpr int value = Num <= Max;
};
template<int Count, int Num>
struct Store
{
static inline void store(int* dst)
{
Store<Count, Num - 1>::store(dst);
dst[Num] = Partition<Count, Num>::value;
}
};
template<int Count>
struct Store<Count, 0>
{
static inline void store(int* dst)
{
;
}
};
template<int Count>
inline void store(int (*dst)[MAX + 1])
{
store<Count - 1>(dst);
Store<Count, MAX>::store(dst[Count]);
}
template<>
inline void store<0>(int (*dst)[MAX + 1])
{
;
}
inline void store(int(*dst)[MAX + 1])
{
store<MAX>(dst);
}
}
namespace problem2
{
template<int Num, int Count = Num, int Helper = Num - Count * (Count - 1) / 2, bool Valid = (Helper > 0)>
struct Accumulator
{
static constexpr int value = Accumulator<Num, Count - 1>::value + problem1::Partition<Count, Helper>::value;
};
template<int Num, int Count, int Helper>
struct Accumulator<Num, Count, Helper, false>
{
static constexpr int value = Accumulator<Num, Count - 1>::value;
};
template<int Num, int Helper, bool Valid>
struct Accumulator<Num, 0, Helper, Valid>
{
static constexpr int value = 0;
};
template<int Num>
inline void store(int* dst)
{
store<Num - 1>(dst);
dst[Num] = Accumulator<Num>::value;
}
template<>
inline void store<0>(int* dst)
{
;
}
inline void store(int* dst)
{
store<MAX>(dst);
}
}
int ans1[MAX + 1][MAX + 1];
int ans2[MAX + 1];
int main()
{
problem1::store(ans1);
problem2::store(ans2);
int num, k;
while (std::cin >> num)
{
std::cin >> k;
std::cout << ans1[k][num] << std::endl;
std::cout << ans2[num] << std::endl;
std::cout << ans2[num] << std::endl;
}
}
請對照運行時版本自行理解。
constexpr不保證計算在編譯期完成,大部分編譯器在Debug模式下把所有可以推遲的constexpr計算都推遲到運行時完成。但constexpr可以作為一個強有力的優化提示,原本在最高優化等級都不會編譯期計算的代碼,在有了constexpr后編譯器會儘力幫你計算。如果編譯器實在做不到,根據你是否強制編譯期求值,編譯器會給出錯誤或推遲到運行時計算。在不同的編譯器中,這類行為的表現是不同的——眾所周知MSVC對constexpr的支持不好。
目前(C++17)沒有任何方法可以檢查一個表達式是否是編譯期求值的,但是有方法可以讓編譯器對於非編譯期求值表達式給出一個錯誤,把期望constexpr的表達式放入模板參數或static_assert表達式都是可行的:如果編譯期求值,則編譯通過;否則編譯錯誤。
(C++20:consteval、is_constant_evaluated)
如果我們把Sqrt中的遞歸替換為如下語句:
static constexpr auto value = (N < mid * mid) ? Sqrt<N, LO, mid - 1>::value
: Sqrt<N, mid, HI>::value;
顯然計算結果是相同的,看上去還更簡潔。但是問題在於,編譯器會把Sqrt<N, LO, mid - 1>和Sqrt<N, mid, HI>兩個類都實例化出來,儘管只有一個模板類的value會被使用到。這些類模板實例繼續導致其他實例產生,最終將產生 \(O \left( n \log n \right)\) 個實例。相比之下,把兩個類型名字傳給std::conditional並不會導致類模板被實例化,std::conditional只是定義一個類型別名,對該類型求::value才會實例化它,一共產生 \(O \left( \log n \right)\) 個實例。
還有一個很常見的工具是變參模板,我沒有介紹是因為暫時沒有用到,而且我怕寫出非多項式複雜度的元程序。如果我還有機會寫一篇類型元編程的話,肯定會包含在其中的。
循環的一次迭代往往需要上一次迭代的結果,對應地在遞歸中就是函數對一個參數的結果依賴於對其他 \(n\) 個參數的結果。有些問題用遞歸解決比較直觀,但是如果 \(n \geq 2\),計算過程就會指數爆炸,比如:
int fibonacci(int n)
{
if (n <= 2)
return 1;
else
return fibonacci(n - 2) + fibonacci(n - 1);
}
計算fibonacci(30)已經需要一點點時間了,而計算fibonacci(46)(4字節帶符號整型能容納的最大斐波那契數)就很慢了。把這種遞歸轉化為循環,就是設計一個動態規劃算法的過程。然而函數式中的遞歸與過程式中的循環可能有相同的漸近複雜度:
template<int N>
struct Fibonacci
{
static constexpr int value = Fibonacci<N - 2>::value + Fibonacci<N - 1>::value;
};
template<>
struct Fibonacci<1>
{
static constexpr int value = 1;
};
template<>
struct Fibonacci<2>
{
static constexpr int value = 1;
};
因為只有Fibonacci<1>到Fibonacci<46>這46個類模板被實例化,是 \(O \left( n \right)\) 複雜度的。
在題目中,由於表中的所有數據都有可能用到,並且運行時不能執行計算,所以要把所有數據都計算出來。實際問題中可能只需要其中一個值,比如我現在就想知道不同整數的劃分問題對 \(50\) 的答案是多少,就寫:
std::cout << problem2::Accumulator<50>::value << std::endl;
那麼problem1::Partition的Count參數就不會超過10,不信的話你可以加一句static_assert。實例化的模板數量一共只有2000多個,而在完整的問題中這個數量要翻100倍不止。這種性質稱為惰性求值,即用到了才求值。惰性求值是必需的,總不能窮盡模板參數的所有可能組合一一實例化出來吧?
函數式編程語言可以在運行時實現這些特性。
我愧對這個小標題,因為C++值元編程根本沒有性能,時間和空間都是。類型元編程也許是必需,至於值元編程,emm,做點簡單的計算就可以了,這整篇文章都是反面教材。
思考題2用GCC編譯,大概需要10分鐘;用MSVC編譯,出現我聞所未聞的錯誤:
因為編譯器是32位的,4GB內存用完了就爆了。
一個很有趣的問題是編譯器對於死循環的行為。根據圖靈停機問題,編譯器無法判斷它要編譯的元程序是否包含死循環,那麼它在遇到死循環時會怎樣表現呢?當然不能跟着元程序一起死循環,constexpr的循環次數與模板的嵌套深度都是有限制的。在GCC中,可以用-fconstexpr-depth、-fconstexpr-loop-limit和-ftemplate-depth等命令行參數來控制。
problem2::Accumulator從Count == 0到Count == Num都要實例化,但其實只需實例化到 \(O \left( \sqrt{n} \right)\) 就可以了,試改寫之。
洛谷 NOIp2016提高組D2T1 組合數問題,用元編程實現。
只需完成 \(n \leq 100, m \leq 100\) 的任務點;
使用64位編譯器(指編譯器本身而非目標代碼),給編譯器億點點時間;
不要去網站上提交,我已經試過了,編譯錯誤。
測試數據下載。
組合數 \(\binom {n} {m}\) 表示的是從 \(n\) 個物品中選出 \(m\) 個物品的方法數。舉個例子,從 \(\left( 1, 2, 3 \right)\) 三個物品中選擇兩個物品可以有 \(\left( 1, 2 \right), \left( 1, 3 \right), \left( 2, 3 \right)\) 這三種選擇方法。根據組合數的定義,我們可以給出計算組合數 \(\binom {n} {m}\) 的一般公式
\[\binom {n} {m} = \frac {n!} {m! \left( n-m \right) !} \,, \]
其中 \(n! = 1 \times 2 \times \cdots \times n\);特別地,定義 \(0! = 1\)。
小蔥想知道如果給定 \(n\),\(m\) 和 \(k\),對於所有的 \(0 \leq i \leq n, 0 \leq j \leq \min \left( i, m \right)\) 有多少對 \(\left( i, j \right)\) 滿足 \(k \mid \binom {i} {j}\)。
第一行有個兩個整數 \(t, k\),其中 \(t\) 代表該測試點總共有多少組測試數據,\(k\) 的意義見問題描述。
接下來 \(t\) 行每行兩個整數 \(n, m\),其中 \(n, m\) 的意義見問題描述。
共 \(t\) 行,每行一個整數代表所有的 \(0 \leq i \leq n, 0 \leq j \leq \min \left( i, m \right)\) 有多少對 \(\left( i, j \right)\) 滿足 \(k \mid \binom {i} {j}\)。
【輸入#1】
1 2
3 3
【輸出#1】
1
【輸入#2】
2 5
4 5
6 7
【輸出#2】
0 7
【樣例1說明】
在所有可能的情況中,只有 \(\binom {2} {1} = 2\) 一種情況是 \(2\) 的倍數。
【子任務】
| 測試點 | \(n\) | \(m\) | \(k\) | \(t\) |
|---|---|---|---|---|
| 1 | \(\leq 3\) | $ \leq 3$ | \(= 2\) | $ = 1$ |
| 2 | \(= 3\) | \(\leq 10^4\) | ||
| 3 | \(\leq 7\) | $ \leq 7$ | \(= 4\) | $ = 1$ |
| 4 | \(= 5\) | \(\leq 10^4\) | ||
| 5 | \(\leq 10\) | $ \leq 10$ | \(= 6\) | $ = 1$ |
| 6 | \(= 7\) | \(\leq 10^4\) | ||
| 7 | \(\leq 20\) | $ \leq 100$ | \(= 8\) | $ = 1$ |
| 8 | \(= 9\) | \(\leq 10^4\) | ||
| 9 | \(\leq 25\) | $ \leq 2000$ | \(=10\) | $ = 1$ |
| 10 | \(=11\) | \(\leq 10^4\) | ||
| 11 | \(\leq 60\) | $ \leq 20$ | \(=12\) | $ = 1$ |
| 12 | \(=13\) | \(\leq 10^4\) | ||
| 13 | \(\leq 100\) | $ \leq 25$ | \(=14\) | $ = 1$ |
| 14 | \(=15\) | \(\leq 10^4\) | ||
| 15 | $ \leq 60$ | \(=16\) | $ = 1$ | |
| 16 | \(=17\) | \(\leq 10^4\) | ||
| 17 | \(\leq 2000\) | $ \leq 100$ | \(=18\) | $ = 1$ |
| 18 | \(=19\) | \(\leq 10^4\) | ||
| 19 | $ \leq 2000$ | \(=20\) | $ = 1$ | |
| 20 | \(=21\) | \(\leq 10^4\) |
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
目錄
macOS上有一個很方便的功能:“觸發角”。通過這個功能可以設置當鼠標移動到屏幕的四個角時的觸發事件,例如觸發啟動屏幕保護程序等,显示桌面等功能。和我們習慣的熱鍵相對應,macOS將其稱之為“Hot Corners(熱角)”。筆者接下來要介紹的軟件“HotCorner“就是用於讓Windows系統擁有像macOS那樣的觸發角,實現下面動圖展示的效果:
當鼠標移動到屏幕的左上角時,自動打開Windows的時間軸試圖,實現快捷切換任務。
這個程序來源於一個國外大神(Google的信息安全工程師)Tavis Ormandy 的一個小項目 hotcorner,他創作這個項目是因為習慣於一款Linux操作系統桌面:GNOME 3,這款桌面可以在鼠標移動到左上角時觸發任務視圖。他發現每當自己使用Windows 10時,總是會忘記Windows中並沒有這個功能,四處尋找替代軟件都無法令他滿意,因此自己用C語言手擼了一個小程序來實現這個功能。但這個小程序只有一個功能:屏幕左上角觸發Windows時間軸視圖。並且軟件的安裝,卸載都需要通過命令行或者手動實現,十分不方便。
筆者在原先的項目基礎上做出了如下改動:
下面一張動圖演示了筆者添加的左下角觸發開始菜單的功能
Github地址:下載地址
碼雲地址:下載地址
如果你不打算參与本軟件開發,只需要下載HotcornerInstaller.exe這個安裝程序即可
國內推薦使用碼雲地址進行下載,速度比較快,但如果你需要提交issue,請前往Github地址。
從上述下載地址將HotcornerInstaller.exe下載下來之後,雙擊打開即可開始安裝。
找到軟件的安裝位置(默認是C:\Program Files (x86)\HotCorner),雙擊該文件夾下的unins000.exe即可完成卸載。在卸載之前請先停止軟件運行(同時按下Ctrl+Alt+C)。
軟件安裝完成之後會自動添加到開始菜單的應用列表中,在其中找到HotCorner,單擊之後軟件即可後台運行。如果你使用了如圖所示的屏幕縮放,並且縮放比例不是100%時,則需要進行下面的配置
正常情況下,軟件可以自動獲取屏幕的高度,但是在系統使用屏幕縮放時,會導致軟件獲取到的不是屏幕的真實高度,因此你需要編輯軟件安裝路徑(默認是C:\Program Files (x86)\HotCorner)下的config.txt文件,在這個文件中寫入屏幕的真實高度,例如圖中的屏幕真實高度為1080(無單位),然後重啟軟件。(config.txt中的默認值是0,表示自動獲取屏幕高度。)
在軟件運行過程中同時按下Ctrl+Alt+C可以關閉程序
代碼使用GPL3協議進行開源,如需使用代碼請遵循CPL3協議相關規定。
Q: 屏幕左上角可以觸發時間軸視圖,但是屏幕右下角沒有反應?
A: 你可能使用了屏幕縮放,查看配置說明
Q: 我想修改屏幕角觸發的事件,怎麼辦?
A: 目前只能自己下載源代碼進行修改,然後重新編譯運行。
Q: 軟件運行之後怎麼關閉?
A: 在軟件運行過程中同時按下Ctrl+Alt+C可以關閉程序
Q: 怎麼讓軟件在開機時運行?
A: 在安裝過程中可以選擇開機啟動,如果安裝時沒有選擇,可以手動實現(方法自己百度即可)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準

這樣的加速放眼這個價位,可以說是數一數二了。當你大腳油門跺下去時,馬牌的MC5輪胎雖然捉地力不錯,但還是響着胎竄出去了,確實有那麼點性能車的味道。儘管動力確實不俗,但是代號DQ380的7速濕式雙離合變速箱還是小小地拖了一下後腿。
大眾在中國深耕多年,絕大部分車系都賣得相當不錯,今天要給大家講講的是奢適寬體轎跑——凌渡。這款車在今年1至3月累計賣出了超過4萬台,實力不用小覷。
動力可以說是凌渡一個小小的賣點,TSI+DSG這套黃金組合併沒有讓我們失望。即便是凌渡的1.4T低功版車型,在實測時,也能有9.1s左右的零百成績。不過在起步時不能憋轉速,這點對於那些玩家來說,還是有點小遺憾。
1.8T車型的零百成績為7.9s,表現比1.4T車型好不少。雖然都是7擋雙離合,但1.8T車型採用的是7擋濕式雙離合。這套雙離合較好地改善了凌渡低速蠕行時的頓挫問題,1/2擋之間的切換不再顯得猶豫。
不過這套7擋雙離合也是有一點點問題,那就是為了平順性,犧牲了一點換擋速度。急加速時的降擋會稍微慢了那麼一點,但也在一個合理的範圍內。如果不是一個對駕駛有很高要求的人,這樣的動力響應已然不錯。
2.0T GTS車型可以說是凌渡的精華所在,220馬力推動僅1475kg的車身,出來的便是6.9s的零百加速。這樣的加速放眼這個價位,可以說是數一數二了。當你大腳油門跺下去時,馬牌的MC5輪胎雖然捉地力不錯,但還是響着胎竄出去了,確實有那麼點性能車的味道。
儘管動力確實不俗,但是代號DQ380的7速濕式雙離合變速箱還是小小地拖了一下後腿。這套變速箱的表現與1.8T車型上的那副相近,都是平順為先,急加速時的降擋還是稍顯拖沓了一些。
除了轎跑這個賣點外,奢適也是凌渡的一大優點。前懸架採用的是麥弗遜式獨立懸架,后懸架則為多連桿獨立懸架,這種結構在同級車中極為常見,但凌渡的調校在操控與舒適之間拿捏得恰到好處。
在過濾路面的震動時,凌渡表現出了足夠的厚實感。即便是在遇到一些大坑窪時,車身的拋跳也不會很明顯。走高速遇到一些接縫位置時,凌渡的底盤貼服性相當不錯。
既然說是奢適寬體轎跑,空間自然不得不提。175cm的體驗者坐在前排時,能獲得3指左右的頭部空間,同時前排的包裹性和舒適性都做得不錯,只是中央扶手的位置稍微低了一些。
二排來看,由於車身偏低矮,所以175cm的體驗者坐在裏面直接就頂頭了,還好腿部依然有兩拳的空間。凌渡的二排中央地板凸起較為明顯,對於中間的乘客不太友好,不過勝在帶有中央頭枕。同時,整個二排的橫向空間表現不錯,坐滿三人時也不會覺得過於擁擠,這點還是值得表揚。
總結
可以看到凌渡這款車表現得頗為全面,無愧於奢適寬體轎跑的名號。動力水平高,儘管換擋稍稍慢了一些,但整體平順性確實好;底盤調校得有高級感,容易討好乘客;最大問題恐怕還是二排頭部空間稍微小了一些。目前凌渡的終端優惠能有5萬塊左右,喜歡的人可以果斷出手了。本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案