Transaction事務是指一個邏輯單元,執行一系列操作的SQL語句。
事務中一組的SQL語句,要麼全部執行,要麼全部回退。在Oracle數據庫中有個名字,叫做transaction ID
在關係型數據庫中,事務必須ACID的特性。
- 原子性,事務中的操作,要不全部執行,要不都不執行
- 一致性,事務完成前後,數據的必須保持一致。
- 隔離性,多個用戶併發訪問數據庫時,每一個用戶開啟的事務,相互隔離,不被其他事務的操作所干擾。
- 持久性,事務一旦commit,它對數據庫的改變是持久性的。
目前重點討論隔離性。數據庫一共有四個隔離級別
-
未提交讀(RU,Read Uncommitted)。它能讀到一個事物的中間狀態,不符合業務中安全性的保證,違背 了ACID特性,存在臟讀的問題,基本不會用到,可以忽略
-
提交讀(RC,Read Committed)。顧名思義,事務提交之後,那麼我們可以看到。這是一種最普遍的適用的事務級別。我們生產環境常用的使用級別。
-
可重複讀(RR,Repeatable Read)。是目前被使用得最多的一種級別。其特點是有GAP鎖,目前還是默認級別,這個級別下會經常發生死鎖,低併發等問題。
-
可串行化,這種實現方式,其實已經是不是多版本了,而是單版本的狀態,因為它所有的實現都是通過鎖來實現的。
因此目前數據庫主流常用的是RC和RR隔離級別。
隔離性的實現方式,我們通常用Read View表示一個事務的可見性。
RC級別,事務可見性比較高,它可以看到已提交的事務的所有修改。因此在提交讀(RC,Read Committed)隔離級別下,每一次select語句,都會獲取一次Read View,得到數據庫最新的事務提交狀態。因此對於數據庫,併發性能也最好。
RR級別,則不是。它為了避免幻讀和不可重複讀。保證在一個事務內前後數據讀取的一致。其可見性視圖Read View只有在自己當前事務提交之後,才會更新。
那如何保證數據的一致性?其核心是通過redo log和undo log來保證的。
而在數據庫中,為了實現這種高併發訪問,就需要對數據庫進行多版本控制,通過事務的可見性來保證事務看到自己想看到的那個數據版本(或者是最新的Read View亦或者是老的Read View)。這種技術叫做MVCC
多版本是如何實現的?通過undo日誌來保證。每一次數據庫的修改,undo日誌會存儲之前的修改記錄值。如果事務未提交,會回滾至老版本的數據。其MVCC的核心原理,以後詳談
舉例論證:
## 開啟事務
MariaDB [scott]> begin;
Query OK, 0 rows affected (0.000 sec)
##查看當前的數據
MariaDB [scott]> select * from dept;
+--------+------------+----------+
| deptno | dname | loc |
+--------+------------+----------+
| 10 | ACCOUNTING | beijing |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | beijing |
| 50 | security | beijing |
| 60 | security | nanchang |
+--------+------------+----------+
6 rows in set (0.001 sec)
##更新數據
MariaDB [scott]> update dept set loc ='beijing' where deptno = 20;
Query OK, 1 row affected (0.001 sec)
## 其行記錄| 20 | RESEARCH | DALLAS |已經被放置在undo日誌中,目前最新的記錄被改為'beijing':
MariaDB [scott]> select * from dept;
+--------+------------+----------+
| deptno | dname | loc |
+--------+------------+----------+
| 10 | ACCOUNTING | beijing |
| 20 | RESEARCH | beijing |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | beijing |
| 50 | security | beijing |
| 60 | security | nanchang |
+--------+------------+----------+
##事務不提交,回滾。數據回滾至老版本的數據。
MariaDB [scott]> rollback;
Query OK, 0 rows affected (0.004 sec)
MariaDB [scott]> select * from dept;
+--------+------------+----------+
| deptno | dname | loc |
+--------+------------+----------+
| 10 | ACCOUNTING | beijing |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | beijing |
| 50 | security | beijing |
| 60 | security | nanchang |
+--------+------------+----------+
6 rows in set (0.000 sec)因為MVCC,讓數據庫有了很強的併發能力。隨着數據庫併發事務處理能力大大增強,從而提高了數據庫系統的事務吞吐量,可以支持更多的用戶併發訪問。但併發訪問,會出現帶來一系列問題。如下:
| 數據庫併發帶來的問題 | 概述解釋 |
|---|---|
| 臟讀(Dirty Reads) | 當一個事務A正在訪問數據,並且對數據進行了修改,而這種修改還沒有提交到數據庫中,這時,另外一個事務B也訪問這同一個數據,如不控制,事務B會讀取這些”臟”數據,並可能做進一步的處理。這種現象被稱為”臟讀”(Dirty Reads) |
| 不可重複讀(Non-Repeatable Reads) | 指在一個事務A內,多次讀同一數據。在這個事務還沒有結束時,另外一個事務B也訪問該同一數據。那麼,在事務A的兩次讀數據之間,由於第二個事務B的修改,那麼第一個事務兩次讀到的的數據可能是不一樣的 。出現了”不可重複讀”(Non-Repeatable Reads)的現象 |
| 幻讀(Phantom Reads) | 指在一個事務A內,按相同的查詢條件重新檢索以前檢索過的數據,同時發現有其他事務插入了數據,其插入的數據滿足事務A的查詢條件。因此查詢出了新的數據,這種現象就稱為”幻讀”(Phantom Reads) |
隔離級別和上述現象之間的聯繫。
隔離級別有:未提交讀(RU,Read Uncommitted),提交讀(RC,Read Committed),可重複讀(RR,Repeatable Read),可串行化(Serializable)
| 隔離級別 | 臟讀 | 不可重複讀 | 幻讀 |
|---|---|---|---|
| 未提交讀(RU,Read Uncommitted) | 可能 | 可能 | 可能 |
| 提交讀(RC,Read Committed) | 不可能 | 可能 | 可能 |
| 可重複讀(RR,Repeatable Read) | 不可能 | 不可能 | 可能 (間隙鎖解決) |
| 可串行化(Serializable) | 不可能 | 不可能 | 不可能 |
實驗環節
舉例在隔離級別RR和RC下,說明“不可重複讀”問題。
MySQL的默認級別是Repeatable Read,如下:
MariaDB [(none)]> select @@global.tx_isolation;
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| REPEATABLE-READ |
+-----------------------+
1 row in set (0.000 sec)這裏修改當前會話級別為Read Committed
MariaDB [scott]> set session transaction isolation level read committed;
Query OK, 0 rows affected (0.001 sec)
MariaDB [scott]> select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+
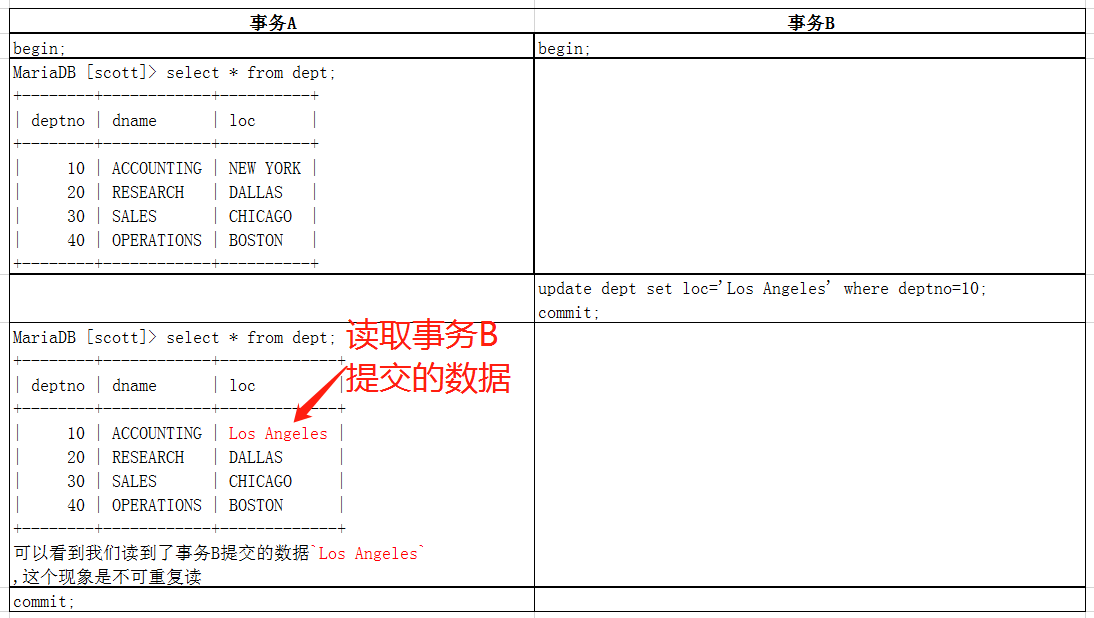
1 row in set (0.000 sec)在隔離級別已提交讀(RC,Read Committed)下,出現了不可重複讀的現象。在事務A中可以讀取事務B中的數據。
在隔離級別可重複讀(RR,Repeatable Read),不會出現不可重複讀現象,舉例如下:
舉例說明“幻讀”的現象。
行鎖可以防止不同事務版本的數據在修改(update)提交時造成數據衝突的問題。但是插入數據如何避免呢?
在RC隔離級別下,其他事務的插入數據,會出現幻讀(Phantom Reads)的現象。
而在RR隔離級別下,會通過Gap鎖,鎖住其他事務的insert操作,避免”幻讀”的發生。
因此,在MySQL事務中,鎖的實現方式與隔離級別有關,如上述實驗所示。在RR隔離級別下,MySQL為了解決幻讀的問題,已犧牲并行度為代價,通過Gap鎖來防止數據的寫入。這種鎖,并行度差,衝突多。容易引發死鎖。
目前流行的Row模式可以避免很多衝突和死鎖問題,因此建議數據庫使用ROW+RC(Read Committed)模式隔離級別,很大程度上提高數據庫的讀寫并行度,提高數據庫的性能。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整




![[NLP] Adaptive Softmax](https://www.3chy2.com.tw/wp-content/uploads/2020/03/587cbe7b1de3b6c09b5cd3a70e52a253.jpg)