前言
在工業互聯網以及物聯網的影響下,人們對於机械的管理,机械的可視化,机械的操作可視化提出了更高的要求。如何在一個系統中完整的显示机械的運行情況,机械的運行軌跡,或者机械的机械動作顯得尤為的重要,因為這會幫助一個不了解這個机械的小白可以直觀的了解机械的運行情況,以及机械的所有可能發生的動作,對於三一或者其它國內國外重工机械的公司能夠有一個更好的展示或者推廣。
挖掘機,又稱挖掘机械(excavating machinery),從近幾年工程机械的發展來看,挖掘機的發展相對較快,挖掘機已經成為工程建設中最主要的工程机械之一。所以該系統實現了對挖掘機的 3D 可視化,在傳統行業一般都是基於 Web SCADA 的前端技術來實現 2D 可視化監控,而且都是 2D 面板部分數據的監控,從後台獲取數據前台显示數據,但是對於挖掘機本身來說,挖掘機的模型,挖掘機的動作,挖掘機的運行可視化卻是更讓人眼前一亮的,所以該系統對於挖機的 3D 模型做出了動作的可視化,大體包括以下幾個方面:
- 前進後退 — 用戶可以通過鍵盤 wasd 實現前後左右,或者點擊 2D 界面 WASD 來實現挖機的前進後退。
- 機身旋轉 — 用戶可以通過鍵盤左右鍵實現機身的旋轉,或者點擊 2D 界面 < > 來實現挖機機身的旋轉。
- 大臂旋轉 — 用戶可點擊 2D 界面第一個滑塊部分實現大臂的旋轉。
- 小臂旋轉 — 用戶可點擊 2D 界面第二個滑塊部分實現小臂的旋轉。
- 挖斗挖掘 — 用戶可點擊 2D 界面第三個滑塊部分實現挖斗部分的旋轉挖掘。
- 挖機動畫 — 用戶可點擊 2D 界面鏟子圖標,點擊之後系統會把挖機本身幾個動畫做一個串聯展示。
本篇文章通過對挖掘機可視化場景的搭建,挖機机械動作代碼的實現進行闡述,幫助我們了解如何使用 實現一個挖掘機的可視化。
預覽地址:
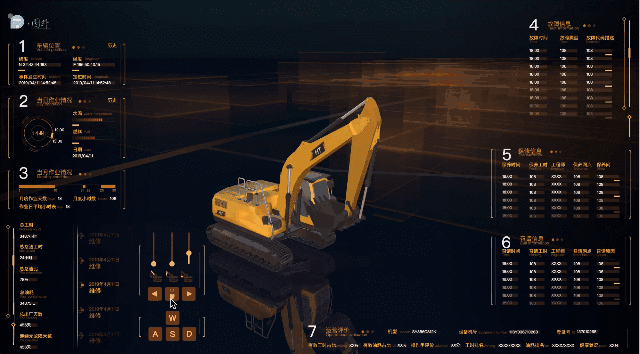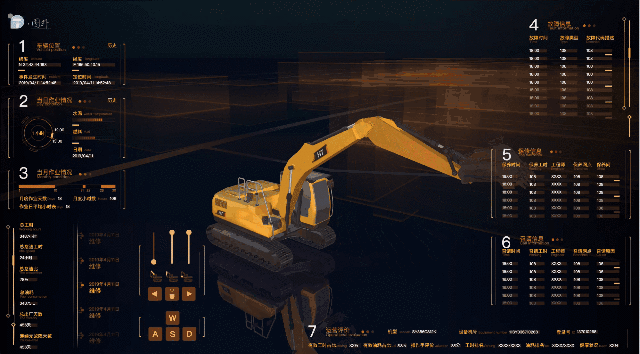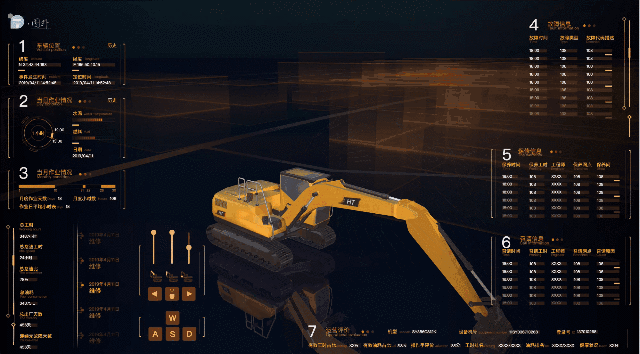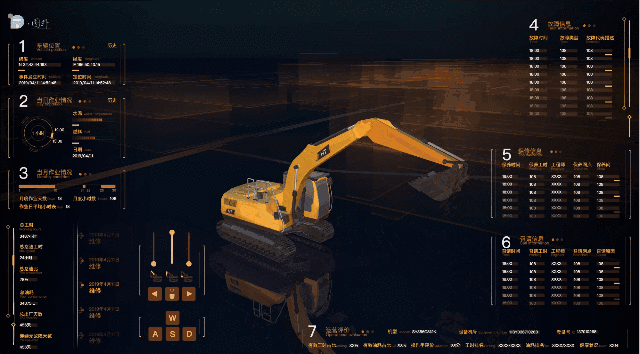
界面效果預覽
挖機机械運動效果
通過上面 gif 圖片可以看出挖掘機的幾個主要動作。
挖機挖斗運動效果
滑動頁面的第三個滑桿控制挖斗的旋轉挖掘。
挖機機身運動
通過上面 gif 圖片可以看出挖掘機的前進後退以及機身旋轉幾個運動。
場景搭建
該 3D 場景中所有形狀都是用 HT 內部的牆面工具進行構建,通過設置牆面透明屬性 shape3d.transparent 為 true 以及對構建出的牆面進行貼圖來構造出場景中的類似建築的显示效果,具體的樣式可以參考 HT 的 ,場景效果:
通過上圖我們可以看到場景中有許許多多的牆面建築,所以它們有許多相同的地方,例如樣式以及貼圖都是一樣的,所以在 HT 中可以通過批量的操作對這些牆面進行處理,批量的意思指的是在當前未處理的情況下的牆面圖元是一個個獨立繪製的模型,所以性能會比較差,而當一批圖元聚合成一個大模型進行一次性的繪製時,則會極大提高 WebGL 刷新性能,這就是批量所以要做的事情,具體可以參考 HT 的 。
該系統 2d 面板部分則也是通過 HT 的矢量進行繪製,面板部分主要包括當前挖機的作業情況,工作時間,保修信息,故障信息等,通過二維的方式展示這些數據信息,面板截圖:
机械運動代碼分析
該系統中挖機的動作是十分的重要和關鍵的,大小臂運動時液壓杠該如何運動,挖斗運動時液壓桿,旋轉點零件,以及連接到挖鬥上的零部件如何聯動起來是關鍵點,机械動畫中用到大部分數學知識進行點面位置的計算,以下是幾個關鍵的數學知識點作為基礎:
在數學中,向量(也稱為幾何向量、矢量),指具有大小和方向的量。它可以形象化地表示為帶箭頭的線段。系統中會通過向量的叉乘算出與某個面垂直的向量即法向量,在計算挖斗旋轉時需要計算出與挖斗面垂直的法向量來進行點的計算,HT 中封裝了 ht.Math 的數學函數,裏面的 ht.Math.Vector2 指的即為二維向量,ht.Math.Vector3 則為三維的向量,可以傳入三個數值進行初始化向量,向量的原型中有 cross 方法用來計算兩個向量的法向量,例如以下偽代碼:
1 var Vector3 = ht.Math.Vector3;
2 var a = new Vector3([10, 10, 0]);
3 var b = new Vector3([10, 0, 0]);
4 var ab = a.clone().cross(b);
以上代碼中 ab 即為計算法向量,a.clone 是為了避免 cross 運算會修改原本的 a 內容,所以克隆出一個新的向量進行叉乘,以下為示意圖:
挖斗机械運動分析
在進行挖斗部分的机械代碼時會將挖斗的位置以及挖斗所有連接點的設備轉化為相對於某個節點的相對位置,例如節點 A 在世界中的坐標為 [100, 100, 100],世界中還有一個節點 B,而且節點 B 的坐標為 [10, 10, 10] 則節點 A 相對於節點 B 的相對位置即為 [90, 90, 90],因為在計算挖斗的位置時,挖機可能此時已經運動到某一點或者旋轉到某一個軸,所以此時不能使用相對世界的坐標,需要使用相對挖機機身的相對坐標來進行計算,代碼中提供了 toLocalPostion(node, worldPosition) 用來將世界的坐標 worldPosition 轉化為相對 node 的相對坐標,以下為代碼實現:
1 var Matrix4 = ht.Math.Matrix4,
2 Vector3 = ht.Math.Vector3;
3 var mat = new Matrix4().fromArray(this.getNodeMat(g3d, node)),
4 matInverse = new Matrix4().getInverse(mat),
5 position = new Vector3(worldPosition).applyMatrix4(matInverse);
6 return position.toArray();
該函數的返回值即為相對坐標,挖機中需要轉化的坐標為連接着挖斗以及小臂的兩個零部件,系統中用 armHinge 以及 bucketHinge 來分別表示小臂樞紐以及挖斗樞紐這兩個零部件,可以從側面來看挖斗的動作,從下圖可以看出,關鍵點是算出交點 P 的坐標,交點 P 的坐標則是以 armHinge 與 bucketHinge位置為圓心,armHinge 與 bucketHinge 的長度為半徑的兩個圓的交點,而且這兩個圓的圓心在挖斗旋轉的過程中是不斷變化的,所以需要通過數學計算不斷算出交點的位置,以下為示意圖:
通過上圖可以知道交點的位置有兩個 p1 以及 p2,程序中通過計算圓心 1 與圓心 2 構成的向量 c2ToC1,以下為偽代碼:
1 var Vector2 = ht.Math.Vector2;
2 var c2ToC1 = new Vector2({ x: c1.x, y: c1.y }).sub(new Vector2({ x: c2.x, y: c2.y }));
c1 和 c2 為 armHinge 以及 bucketHinge 的圓心坐標,接下來是計算圓心 2 與點 p1 以及 p2 構成的向量 c2ToP1 以及 c2ToP2,以下為偽代碼:
1 var Vector2 = ht.Math.Vector2;
2 var c2ToP1 = new Vector2({ x: p1.x, y: p1.y }).sub(new Vector2({ x: c2.x, y: c2.y }));
3 var c2ToP2 = new Vector2({ x: p2.x, y: p2.y }).sub(new Vector2({ x: c2.x, y: c2.y }));
通過上述操作我們可以獲得三個向量 c2ToC1,c2ToP1,c2ToP2 所以我們可以用到我上述講的向量叉乘的概念進行 p1 與 p2 點的選取,通過向量 c2ToC1 與 c2ToP1,以及向量 c2ToC1 與 c2ToP2 分別進行叉乘得到的結果肯定一個是大於 0 一個小於 0,二維向量的叉乘可以直接把它們視為 3d 向量,z軸補 0 的三維向量,不過二維向量叉乘的結果 result 不是向量而是數值,如果 result > 0 時,那麼 a 正旋轉到 b 的角度為 <180°,如果 k < 0,那麼 a 正旋轉到 b 的角度為 >180°,如果 k = 0 那麼a,b向量平行,所以通過上面的理論知識我們可以知道結果肯定是一個大於 0 一個小於 0,我們可以在程序中測下可以知道我們需要獲取的是大於 0 的那個點 P1,所以每次可以通過上述的方法進行兩個交點的選擇。
以下為挖斗部分動畫的執行流程圖:
通過上述運算之後我們可以獲取到最終需要的點 P 坐標,點 P 坐標即為挖斗與小臂連接部分的一個重要點,獲取該點之後我們可以通過 HT 中提供的 lookAtX 函數來實現接下來的操作,lookAtX 函數的作用為讓某個物體看向某一點,使用方式如下:
1 node.lookAtX(position, 'bottom');
node 即為需要看向某一個點的節點,position 為看向的點的坐標,第二個參數有六個枚舉值可以選擇,分別為 ‘bottom’,’back’,’front’,’top’,’right’,’left’,第二個參數的作用是當我們需要把某個物體看向某一個點的時候我們也要指定該物體的哪一個面看向該點,所以需要提供第二個參數來明確,獲取到該函數之後我們可以通過將 bucketHinge 看向點 P,armHinge 看向點 P,就可以保持這兩個連接的設備永遠朝向該點,以下為部分偽代碼:
1 bucketHinge.lookAtX(P, 'front');
2 armHinge.lookAtX(P, 'bottom');
所以通過上述操作之後我們已經把挖斗部分的兩個關鍵零件的位置已經擺放正確,接下來是要正確的擺放與挖斗連接的小臂上液壓部分的位置,下一部分為介紹該節點如何進行擺放。
液壓聯動分析
在場景中我們可以看到液壓主要分為兩個部分,一部分為白色的較細的液壓桿,一部分為黑色的較厚的液壓桿,白色的液壓桿插在黑色的液壓桿中,所以在小臂或者挖斗旋轉的過程中我們要保持兩個節點始終保持相對的位置,通過上一步驟中我們可以知道 lookAtX 這個函數的作用,所以在液壓桿部分我們也是照樣用該函數來實現。
在上一步我們獲取到了挖斗旋轉過程中的關鍵點 P,所以在挖斗旋轉的過程我們小臂上的液壓桿也要相應的進行變化,具體的操作就是將小臂的白色液壓桿的位置設置為上步中計算出來的點 P 的位置,當然需要把白色液壓桿的錨點進行相應的設置,之後讓白色液壓桿 lookAt 黑色液壓桿,同時讓黑色液壓桿 lookAt 白色液壓桿,這樣下來兩個液壓桿都在互相看着對方,所以它們呈現出來的效果就是白色液壓桿在黑色液壓桿中進行伸縮,以下為偽代碼:
1 bucketWhite.p3(P);
2 bucketWhite.lookAtX(bucketBlack.p3(), 'top');
3 bucketBlack.lookAtX(P, 'bottom');
代碼中 bucketWhite 節點即為小臂上白色液壓桿,bucketBlack 節點為小臂上黑色液壓桿,通過以上的設置就可以實現伸縮的動畫效果,以下為液壓的運行圖:
同理挖機身上的大臂的液壓動作以及機身與大臂連接部分的液壓動作都是使用上面的方法來實現,以下為這兩部分的代碼:
1 rotateBoom: (rotateVal) = >{
2 excavatorBoomNode.setRotationX(dr * rotateVal);
3 let archorVector = [0.5 - 0.5, 0.56 - 0.5, 0.22 - 0.5];
4 let pos = projectUtil.toWorldPosition(g3d, excavatorBoomNode, archorVector);
5 boomWhite.lookAtX(boomBlack.p3(), 'bottom');
6 boomBlack.lookAtX(pos, 'top');
7 },
8 rotateArm: (rotateVal) = >{
9 projectUtil.applyRelativeRotation(excavatorArmNode, excavatorBoomNode, -rotateVal);
10 let archorVector = [0.585 - 0.5, 0.985 - 0.5, 0.17 - 0.5];
11 let pos = projectUtil.toWorldPosition(g3d, excavatorArmNode, archorVector);
12 armWhite.lookAtX(armBlack.p3(), 'bottom');
13 armBlack.lookAtX(pos, 'top');
14 }
我將兩部分的運動封裝為兩個函數 rotateBoom 以及 rotateArm 分別是大臂與機身連接處的液壓運動與大臂上的液壓運動,在該部分中為了精確的獲取看向的點,我通過 toWorldPosition 方法將相對坐標轉化為世界坐標,相對坐標為黑白液壓桿的錨點坐標,轉化為相對大臂或者機身的世界坐標。
基本運動分析
挖機的基本運動包括前進後退,機身旋轉,這一部分會相對上面的運動簡單許多,在 HT 的三維坐標系中,不斷修改挖機機身的 x,y,z 的坐標值就可以實現挖機的前進後退,通過修改機身的 y 軸旋轉角度則可以控制機身的旋轉,當然挖機身體上的所有其它零部件需要吸附在機身身上,當機身進行旋轉時其它零部件則會進行相應的旋轉,在進行前進的時候挖機底部的履帶會進行對應的滾動,當然履帶我們這邊是用了一個履帶的貼圖貼在上面,當挖機前進的時候修改貼圖的偏移值就可以實現履帶的滾動,修改偏移值的偽代碼如下:
1 node.s('shape3d.uv.offset', [x, y]);
上面的 x,y 分別為 x 軸與 y 軸方向的偏移值,在挖機前進後退的過程中不斷修改 y 的值可以實現履帶的滾動效果,具體的文檔說明可以查看
在挖機前進後退的過程中我們可以 wasd 四個鍵同時按下,並且可以對按鍵進行一直的響應,在 js 中可以通過 document.addEventListener(‘keydown’, (e) => {}) 以及 document.addEventListener(‘keyup’, (e) => {}) 進行監聽,但是這隻能每次執行一次需要執行的動作,所以我們可以在外部起一個定時器,來執行 keydown 時候需要不斷執行的動作,可以用一個 keyMap 來記錄當前已經點擊的按鍵,在 keydown 的時候紀錄為 true 在 keyup 的時候記錄為 false,所以我們可以在定時器中判斷這個 bool 值,當為 true 的時候則執行相應的動作,否則不執行,以下為對應的部分關鍵代碼:
1 let key_pressed = {
2 65 : {
3 status: false,
4 action: turnLeft
5 },
6 87 : {
7 status: false,
8 action: goAhead
9 },
10 68 : {
11 status: false,
12 action: turnRight
13 },
14 83 : {
15 status: false,
16 action: back
17 },
18 37 : {
19 status: false,
20 action: bodyTurnLeft
21 },
22 39 : {
23 status: false,
24 action: bodyTurnRight
25 }
26 };
27 setInterval(() = >{
28 for (let key in key_pressed) {
29 let {
30 status,
31 action
32 } = key_pressed[key];
33 if (status) {
34 action();
35 }
36 }
37 },
38 50);
39 document.addEventListener('keydown', (event) = >{
40 let keyCode = event.keyCode;
41 key_pressed[keyCode] && (key_pressed[keyCode].status = true);
42 event.stopPropagation();
43 },
44 true);
45 document.addEventListener('keyup', (event) = >{
46 let keyCode = event.keyCode;
47 key_pressed[keyCode] && (key_pressed[keyCode].status = false);
48 event.stopPropagation();
49 },
50 true);
從上面代碼可以看出我在 key_pressed 變量中記錄對應按鍵以及按鍵對應的 action 動作,在 keydown 與 keyup 的時候對應修改當前 key 的 status 的狀態值,所以可以在 Interval 中根據 key_pressed 這個變量的 status 值執行對應的 action 動作,以下為執行流程圖:
HT 的輕量化,自適應讓當前系統在手機端也能流暢的運行,當然目前移動端與電腦端的 2D 圖紙部分是加載不同的圖紙,在移動端的 2D 部分只留下操作挖機的操作部分,其它部分進行了相應的捨棄,不然在移動端小屏幕下無法展示如此多的數據,在 3D 場景部分都是共用同一個場景,通過場景搭建部分的批量操作使得 3D 在手機端也十分流暢的運行,以下為手機端運行截圖:
總結
物聯網已經融入了現代生活,通過內嵌到机械設備中的电子設備,我們能夠完成對机械設備的運轉、性能的監控,以及對机械設備出現的問題進行及時的預警。在該系統 2D 面板監控部分就是對採集過來的數據進行可視化的展示,而且我們可以藉助大數據和物聯網技術,將一台台机械通過機載控制器、傳感器和無線通訊模塊,與一個龐大的網絡連接,每揮動一鏟、行動一步,都形成數據痕迹。大數據精準描繪出基礎建設開工率等情況,成為觀察固定資產投資等經濟變化的風向標。所以在實現上述挖機動作之後,通過與挖機傳感器進行連接之後,可以將挖掘機此時的真實動作通過數據傳遞到系統,系統則會根據動作進行相應的真實操作,真正實現了挖機與網絡的互聯互通。
程序運行截圖:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※新北清潔公司,居家、辦公、裝潢細清專業服務