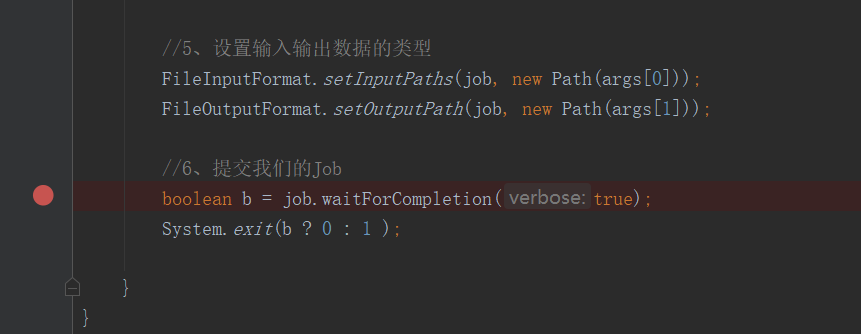
說到,我們可以在 BeanPostProcessor 中對 bean 的初始化前化做手腳,當時也說了,我完全可以生成一個代理類丟回去。
代理類肯定要為用戶做一些事情,不可能像學設計模式的時候創建個代理類,然後簡單的在前面打印一句話,後面打印一句話,這叫啥事啊,難怪當時聽不懂。最好是這個方法的前後過程可以自戶自己定義。
小明說,這還不好辦,cglib 已經有現成的了,jdk 也可以實現動態代理,看 mybatis 其實也是這麼乾的,不然你想它一個接口怎麼就能找到 xml 的實現呢,可以參照下 mybatis 的代碼。
所以首先學習下 cglib 和 jdk 的動態代理,我們來模擬下 mybatis 是如何通過接口來實現方法調用的
cglib
目標接口:
public interface UserOperator {
User queryUserByName(String name);
}
代理處理類:
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
public class ProxyHandle implements MethodInterceptor{
// 實現 MethodInterceptor 的代理攔截接口
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("獲取到 sqlId:"+method);
System.out.println("獲取到執行參數列表:"+args[0]);
System.out.println("解析 spel 表達式,並獲取到完整的 sql 語句");
System.out.println("執行 sql ");
System.out.println("結果集處理,並返回綁定對象");
return new User("sanri",1);
}
}
真正調用處:
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(UserOperator.class);
enhancer.setCallback(new ProxyHandle());
//可以把這個類添加進 ioc 容器,這就是真正的代理類
UserOperator userOperator = (UserOperator) enhancer.create();
User sanri = userOperator.queryByName("sanri");
System.out.println(sanri);
jdk
import java.lang.reflect.InvocationHandler;
public class ProxyHandler implements InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("獲取到 sqlId:"+method);
System.out.println("獲取到執行參數列表:"+args[0]);
System.out.println("解析 spel 表達式,並獲取到完整的 sql 語句");
System.out.println("執行 sql ");
System.out.println("結果集處理,並返回綁定對象");
return new User("sanri",1);
}
}
真正調用處:
UserOperator proxyInstance = (UserOperator)Proxy.newProxyInstance(ClassLoader.getSystemClassLoader(), new Class[]{UserOperator.class}, new ProxyHandler());
User sanri = proxyInstance.queryByName("sanri");
System.out.println(sanri);
注:jdk 只能支持代理接口,但 cglib 是接口和實體類都可以代理; jdk 是使用實現接口方式,可以多實現,但 cglib 是繼承方式,也支持接口方式。
代理模式和裝飾模式的區別:
從這也可以看到代理模式和裝飾模式的區別 ,代理模式的方法簽名一般是不動的,但裝飾模式是為了方法的增強,一般會使用別的更好的方法來代替原方法。
如何織入
回到正文,這時我們已經可以創建一個代理類了,如何把用戶行為給弄進來呢,哎,又只能 回調 了,我們把現場信息給用戶,用戶實現我的接口,然後我找到接口的所有實現類進行順序調用,但這時候小明想到了幾個問題
- 用戶不一定每個方法都要做代理邏輯,可能只是部分方法需要,我們應該能夠識別出是哪些方法需要做代理邏輯 (Pointcut)
- 方法加代理邏輯的位置,方法執行前(Before),方法執行后(After),方法返回數據后(AfterReturning),方法出異常后(AfterThrowing),自定義執行(Around)
根據單一職責原則,得寫五個接口,每個接口要包含 getPointCut() 方法和 handler() 方法,或者繞過單一職責原則,在一個接口中定義 6 個方法,用戶不想實現留空即可。總得來說,用戶只需要提交一份規則給我就行,這個規則你不管是用 json,xml ,或者 註解的方式,只要我能夠識別在 這個 pointcut 下,需要有哪些自定義行為,在另一個 pointcut 下又有哪些自定義行為即可。
現拿到用戶行為了和切點了,還需要創建目標類的代理類,並把行為給綁定上去,在什麼時候創建代理類呢,肯定在把 bean 交給容器的時候悄悄的換掉啊, 說到 bean 有一個生命周期是用於做所有 bean 攔截的,並且可以在初始化前和初始化後進行攔截,沒錯,就是 BeanPostProcessor 我們可以在初始化後生成代理類。
這裏需要注意,並不是所有類都需要創建代理。我們可以這樣檢測,讓 pointcut 提供一個方法用於匹配當前方法是否需要代理,當然這也是 pointcut 的職責,如果當前類有一個方法需要代理,那麼當前類是需要代理的,否則認為不需要代理,這麼做需要遍歷所有類的所有方法,如果運氣差的話,看上去很耗費性能 ,但 spring 也是這麼乾的。。。。。。優化的方案可以這麼玩,如果方法需要代理,在類上做一個標識,如果類上存在這個標識,則可以直接創建代理類。
現在我們把用戶行為綁定到代理類,根據上面 jdk 動態代理和 cglib 動態代理的學習,我們發現,它們都有一個共同的傢伙,那就是方法攔截,用於攔截目標類的當前正在執行的方法,並增強其功能,我們可以在創建代理類的時候找到所有的用戶行為並按照順序和類型依次綁定,可以用責任鏈模式。
看一下 spring 是怎麼玩的
spring 也是在 BeanPostProcessor 接口的 postProcessAfterInitialization 生命周期進行攔截,具體的類為 AspectJAwareAdvisorAutoProxyCreator
spring 配置切面有兩種方式,使用註解和使用配置,當然,現在流行註解的方式,更方便,但不管是配置還是註解,最後都會被解析成 Advisor(InstantiationModelAwarePointcutAdvisorImpl),spring 查找了所有實現 Advisor 的類,源代碼在 BeanFactoryAdvisorRetrievalHelper.findAdvisorBeans
advisorNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(this.beanFactory, Advisor.class, true, false);
緊接着,spring 會使使用 Advisor 中的 pointcut 來看當前類是否需要創建代理類,跟進方法可以看到 canApply 方法中是遍歷了所有方法一個個匹配來看是否需要創建代理類的,如果有一個需要,則直接返回 true 。當然 spring 更嚴謹一些,它考慮到了可能有接口的方法需要有代理,我上面說在類加標識是不正確的。
然後通過 createProxy 創建了代理類,裏面有區分 cglib 還是 aop ,下面單拿 cglib 來說
在 CglibAopProxy.getProxy 中對類進行增強,主要看 Enhancer 類是如何設置的就好了,有一個 callback 參數 ,我們一般是第 0 個 callback 也即 DynamicAdvisedInterceptor 它是一個 cglib 的 MethodInterceptor
它重寫的是 MethodInterceptor 的 intercept 方法,下面看這個方法,this.advised 是前面傳過來的用戶行為,getInterceptorsAndDynamicInterceptionAdvice 把 Advisor 適配成了 org.aopalliance.intercept.MethodInterceptor 分別對應切面的五種行為
AbstractAspectJAdvice
|- AspectJAfterReturningAdvice
|- AspectJAfterAdvice implements org.aopalliance.intercept.MethodInterceptor
|- AspectJAroundAdvice implements org.aopalliance.intercept.MethodInterceptor
|- AspectJAfterThrowingAdvice implements org.aopalliance.intercept.MethodInterceptor
|- AspectJMethodBeforeAdvice
最後它封裝一個執行器,根據順序調用攔截器鏈,也即用戶行為列表,封裝執行的時候是強轉 org.aopalliance.intercept.MethodInterceptor 來執行的,但 AspectJAfterReturningAdvice 和 AspectJMethodBeforeAdvice 沒有實現 org.aopalliance.intercept.MethodInterceptor 怎麼辦,所以 spring 在獲取用戶行為鏈的時候增加了一個適配器,專門用於把這兩種轉換成 MethodInterceptor
其它說明
來個示例更容易理解
我們除了使用 @Aspect 註解把切面規則告訴 spring 外,也可以學本身 aop 的實現,我們自己定義一個 Advisor ,因為 spring 就是掃描這個的,然後實現 pointcut 和 invoke 方法,一樣可以實現 aop 。
聯繫上文: 我們來看看 spring 的 redis-cache 是如何做切面的
文章說到,主要工作的類是 CacheInterceptor 它是一個 org.aopalliance.intercept.MethodInterceptor
Advisor 是 BeanFactoryCacheOperationSourceAdvisor 也就是說創建代理類會掃描到這個類,最後執行會把其轉成 MethodInterceptor,因為它是一個 PointcutAdvisor ,查看 DefaultAdvisorChainFactory.getInterceptorsAndDynamicInterceptionAdvice 方法,第一個就是把 PointcutAdvisor 轉成 MethodInterceptor 繼續進入獲取攔截器的方法,可以知道就是獲取的 advice 屬性 CacheInterceptor
一點小推廣
創作不易,希望可以支持下我的開源軟件,及我的小工具,歡迎來 gitee 點星,fork ,提 bug 。
Excel 通用導入導出,支持 Excel 公式
博客地址:
gitee:
使用模板代碼 ,從數據庫生成代碼 ,及一些項目中經常可以用到的小工具
博客地址:
gitee:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?