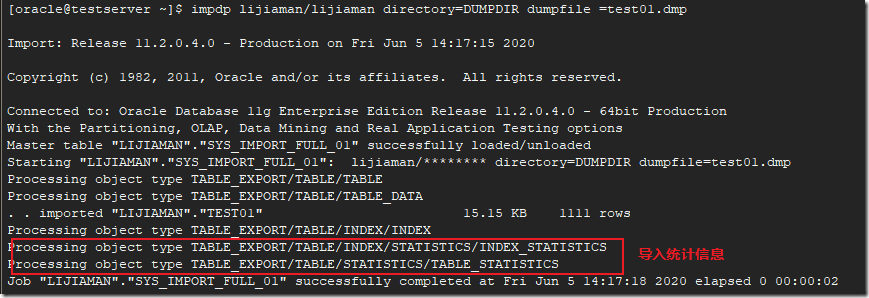
上文簡要總結了一些AOP的基本概念,並在此基礎上敘述了Spring AOP的基本原理,並且輔以一個簡單例子幫助理解。從本文開始,我們要開始深入到源碼層面來一探Spring AOP魔法的原理了。
要使用Spring AOP,第一步是要將這一功能開啟,一般有兩種方式:
- 通過xml配置文件的方式;
- 通過註解的方式;
1. 配置文件開啟AOP功能
我們先來看一下配置文件的方式,這個上文也提到過,在xml文件中加上對應的標籤,而且別忘了加上對應的名稱空間(即下面的xmlns:aop。。。):
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.springframework.org/schema/beans" xmlns:aop = "http://www.springframework.org/schema/aop" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.0.xsd"> <aop:aspectj-autoproxy/> </beans>
這裡是通過標籤<aop:aspectj-autoproxy/>來完成開啟AOP功能,這是一個自定義標籤,需要自定義其解析,而這些spring都已經實現好了,前面專門寫過一篇文章講述spring是如何解析自定義xml標籤的,我們這裏大致回顧一下解析流程:
- 定義一個XML文件來描述你的自定義標籤元素;
- 創建一個Handler,擴展自NamespaceHandlerSupport,用於註冊下面的parser;
- 創建若干個BeanDefinitionParser的實現,用來解析XML文件中的定義;
- 將上述文件註冊到Spring中,這裏其實是做一下配置;
我們就不照着這個步驟來了,我們直接參考spring對這個自定義標籤的解析過程,上面的4個步驟只是作為參考,在整個解析過程中都會涉及到。
前面講解析自定義xml標籤時候提到過,解析的流程大致如下:
- 首先會去獲取自定義標籤對應的名稱空間;
- 然後根據名稱空間找到對應的NamespaceHandler;
- 調用自定義的NamespaceHandler進行解析;
1.1 獲取名稱空間
這裏<aop:aspectj-autoproxy/>對應的名稱空間是什麼呢?在上面的開啟aop的配置文件裏面名稱空間那裡給出了一些線索,其實就是下面這個:
http://www.springframework.org/schema/aop
至於名稱空間的獲取,也無甚好說的,其實就是直接調用org.w3c.dom.Node提供的相應方法來完成名稱空間的提取。
1.2 獲取handler
然後又是如何根據名稱空間找到對應的NamespaceHandler呢?之前也說到過,在找對應的NamespaceHandler時會去META-INF/spring.handlers這個目錄下加載資源文件,我們來找一下spring.handlers這個文件看看(需要去spring-aop對應的jar報下找):
http\://www.springframework.org/schema/aop=org.springframework.aop.config.AopNamespaceHandler
看到沒,這裡是以key-value的形式維護着名稱空間和對應handler的關係的,所以對應的handler就是這個AopNamespaceHandler。spring根據名稱空間找到這個handler之後,會通過反射的方式將這個類加載,並緩存起來。
1.3 解析標籤
上面的handler只有一個自定義的方法:
public void init() { // In 2.0 XSD as well as in 2.1 XSD. registerBeanDefinitionParser("config", new ConfigBeanDefinitionParser()); registerBeanDefinitionParser("aspectj-autoproxy", new AspectJAutoProxyBeanDefinitionParser()); registerBeanDefinitionDecorator("scoped-proxy", new ScopedProxyBeanDefinitionDecorator()); // Only in 2.0 XSD: moved to context namespace as of 2.1 registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser()); }
這是一個初始化方法,在加載的時候會執行,主要作用就是註冊一些解析器,這裏我們主要關注AspectJAutoProxyBeanDefinitionParser,這就是我們要找的,它的作用就是解析<aop:aspectj-autoproxy/>標籤的。主要流程就是,spring會調用上一步拿到的AopNamespaceHandler的parse()方法,在這個方法裏面,會將解析的工作委託給AspectJAutoProxyBeanDefinitionParser來完成具體解析工作,我們就來看一下具體幹了啥吧。
開始解析的工作從這裏開始:
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
此時我們拿到的handler其實是我們自定義的AopNamespaceHandler了,但是它並沒有實現parse()方法,所以這裏這個應該是調用的父類(NamespaceHandlerSupport)中的parse()方法:
public BeanDefinition parse(Element element, ParserContext parserContext) { // 尋找解析器並進行解析操作 return findParserForElement(element, parserContext).parse(element, parserContext); } private BeanDefinitionParser findParserForElement(Element element, ParserContext parserContext) { // 獲取元素名稱,也就是<aop:aspectj-autoproxy/>中的aspectj-autoproxy String localName = parserContext.getDelegate().getLocalName(element); // 根據aspectj-autoproxy找到對應的解析器,也就是在registerBeanDefinitionParser("aspectj-autoproxy", new AspectJAutoProxyBeanDefinitionParser()); // 註冊的解析器 BeanDefinitionParser parser = this.parsers.get(localName); if (parser == null) { parserContext.getReaderContext().fatal( "Cannot locate BeanDefinitionParser for element [" + localName + "]", element); } return parser; }
首先是尋找元素對應的解析器,然後調用其parse()方法。結合我們前面的示例,其實就是首先獲取在AopNamespaceHandler類中的init()方法中註冊對應的AspectJAutoProxyBeanDefinitionParser實例,並調用其parse()方法進行進一步解析:
public BeanDefinition parse(Element element, ParserContext parserContext) { AopNamespaceUtils.registerAspectJAnnotationAutoProxyCreatorIfNecessary(parserContext, element); extendBeanDefinition(element, parserContext); return null; } // 下面的代碼在AopConfigUtils中 public static void registerAspectJAnnotationAutoProxyCreatorIfNecessary( ParserContext parserContext, Element sourceElement) { BeanDefinition beanDefinition = AopConfigUtils.registerAspectJAnnotationAutoProxyCreatorIfNecessary( parserContext.getRegistry(), parserContext.extractSource(sourceElement)); useClassProxyingIfNecessary(parserContext.getRegistry(), sourceElement); registerComponentIfNecessary(beanDefinition, parserContext); } public static BeanDefinition registerAspectJAnnotationAutoProxyCreatorIfNecessary(BeanDefinitionRegistry registry, Object source) { return registerOrEscalateApcAsRequired(AnnotationAwareAspectJAutoProxyCreator.class, registry, source); } private static BeanDefinition registerOrEscalateApcAsRequired(Class cls, BeanDefinitionRegistry registry, Object source) { Assert.notNull(registry, "BeanDefinitionRegistry must not be null"); if (registry.containsBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME)) { BeanDefinition apcDefinition = registry.getBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME); if (!cls.getName().equals(apcDefinition.getBeanClassName())) { int currentPriority = findPriorityForClass(apcDefinition.getBeanClassName()); int requiredPriority = findPriorityForClass(cls); if (currentPriority < requiredPriority) { apcDefinition.setBeanClassName(cls.getName()); } } return null; } RootBeanDefinition beanDefinition = new RootBeanDefinition(cls); beanDefinition.setSource(source); beanDefinition.getPropertyValues().add("order", Ordered.HIGHEST_PRECEDENCE); beanDefinition.setRole(BeanDefinition.ROLE_INFRASTRUCTURE); registry.registerBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME, beanDefinition); return beanDefinition; }
上面這一堆代碼最核心的部分就在後兩個方法中,就是完成了對AnnotationAwareAspectJAutoProxyCreator類的註冊,到這裏對自定義標籤<aop:aspectj-autoproxy/>的解析也就完成了,可以看到其最核心的部分就是完成了對AnnotationAwareAspectJAutoProxyCreator類的註冊,那為什麼註冊了這個類就開啟了aop功能呢?這裏先賣個關子,後面詳細說。
這裏再回過頭來看一下上面說到的spring對自定義標籤解析的4個步驟,其實第一步的schema對應的是在org.springframework.aop.config路徑下的spring-aop-3.0.xsd文件,其映射關係是維護在META-INF/spring.schemas文件中的,而spring-aop-3.0.xsd的主要作用就是描述自定義標籤。
當通過META-INF/spring.handlers找到對應的AopNamespaceHandler,並通過在其加載后執行init()方法過程中完成了AspectJAutoProxyBeanDefinitionParser的註冊,有這個parser再來完成對自定義標籤的解析工作,這對應上面4個步驟中的第二步和第三部。至於第四步的配置工作,無非就是將spring.schemas和spring.handlers這兩個配置文件放在META-INF/目錄下罷了。
關於這部分解析過程,寫得不是非常詳細,如果有不明白,可以參考之前一篇文章,講spring是如何解析自定義xml標籤。
2. 註解方式開啟aop
另一種開啟spring aop的方式是通過註解的方式,使用的註解是@EnableAspectJAutoProxy,可以通過配置類的方式完成註冊:
@Configuration @EnableAspectJAutoProxy public class AppConfig { }
也可以在啟動類上直接加上這個註解,這在springboot中比較常見,其實質也是上面的方式。通過這種方式配置之後,就開啟了aop功能,那具體又是如何實現的呢?我們看一下這個註解:
@Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @Documented @Import(AspectJAutoProxyRegistrar.class) public @interface EnableAspectJAutoProxy { /** * Indicate whether subclass-based (CGLIB) proxies are to be created as opposed * to standard Java interface-based proxies. The default is {@code false}. */ boolean proxyTargetClass() default false; /** * Indicate that the proxy should be exposed by the AOP framework as a {@code ThreadLocal} * for retrieval via the {@link org.springframework.aop.framework.AopContext} class. * Off by default, i.e. no guarantees that {@code AopContext} access will work. * @since 4.3.1 */ boolean exposeProxy() default false; }
這裏我們的關注點是其通過@Import(AspectJAutoProxyRegistrar.class)引入了AspectJAutoProxyRegistrar,那這又是什麼?
class AspectJAutoProxyRegistrar implements ImportBeanDefinitionRegistrar { /** * Register, escalate, and configure the AspectJ auto proxy creator based on the value * of the @{@link EnableAspectJAutoProxy#proxyTargetClass()} attribute on the importing * {@code @Configuration} class. */ @Override public void registerBeanDefinitions( AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) { AopConfigUtils.registerAspectJAnnotationAutoProxyCreatorIfNecessary(registry); AnnotationAttributes enableAspectJAutoProxy = AnnotationConfigUtils.attributesFor(importingClassMetadata, EnableAspectJAutoProxy.class); if (enableAspectJAutoProxy != null) { if (enableAspectJAutoProxy.getBoolean("proxyTargetClass")) { AopConfigUtils.forceAutoProxyCreatorToUseClassProxying(registry); } if (enableAspectJAutoProxy.getBoolean("exposeProxy")) { AopConfigUtils.forceAutoProxyCreatorToExposeProxy(registry); } } } }
看到這裏,是不是有點眼熟了呢?是的,其實它也是和上面說的xml配置使用的方式一樣,通過AopConfigUtils來完成AnnotationAwareAspectJAutoProxyCreator類的註冊。是不是比xml配置文件的方式方便許多呢。
4. 開啟aop的魔法
通過前面的學習我們了解了可以通過Spring自定義配置完成對AnnotationAwareAspectJAutoProxyCreator類型的自動註冊,而這個類到底是做了什麼工作來實現AOP的操作呢?這裏還是先來看一下AnnotationAwareAspectJAutoProxyCreator的類層次結構:
這裡有一個很重要的點,就是AnnotationAwareAspectJAutoProxyCreator實現了BeanPostProcessor接口。在IOC部分的文章中有詳細說過,Spring在加載Bean的過程中會在實例化bean前後調用BeanPostProcessor的相關方法(相關邏輯是在initializeBean方法中,調用postProcessBeforeInitialization、postProcessAfterInitialization方法),而AOP的魔法就是從這裏開始的。
每次看到這裏,我內心對spring的軟件架構設計都是湧現出無比的佩服,通過後處理器的方式來做擴展,對原有模塊是沒有任何改動,也不會產生耦合,spring親自踐行着對修改關閉,對擴展開放的原則。
3. 總結
本文我們學習了spring是如何開啟aop功能的,無論是通過xml配置文件方式,還是通過Java config這種註解的方式,其最終都是完成了將AnnotationAwareAspectJAutoProxyCreator這個類註冊到spring容器當中,那這個類又有什麼魔法,可以達到將其註冊到容器即達到開啟aop的功效,其實其繼承自BeanPostProcessor接口,通過後處理器的方式擴展出了開啟spring aop的功能。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!