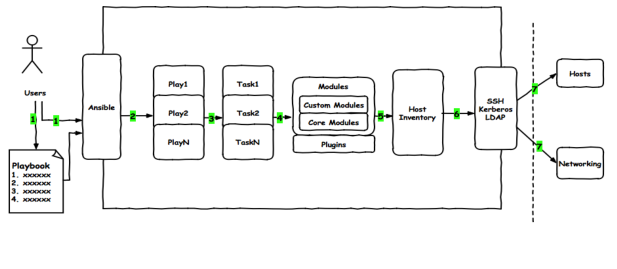
一、playbook簡介
ansiblie的任務配置文件被稱為playbook,俗稱“劇本”,每一個劇本(playbook)中都包含了一系列的任務,這每個任務在ansible中又被稱為“戲劇”(play),一個劇本中包含多齣戲劇。。
前文我們了解了ansible有兩種執行方式ad-hoc和ansible-playbook,ad-hoc主要用於臨時命令的執行,而playbook我們可以理解為ad-hoc的集合,有點類似shell腳本,ad-hoc就相當於shell腳本里的某條任務語句,playbook就相當於整個shell腳本。playbook是由一個或多個“play”組成的列表,play的主要功能在於將預定義的一組主機,裝扮成事先通過ansible中的task定義好的角色。task實際是調用ansible的一個模塊,將多個play組織在一個playbook中,即可以讓他們聯合起來,按事先編排的機制執行預定義的動作。
如以上圖示,用戶可以把多條任務(ad-hoc任務)寫到playbook中,用戶用ansible-playbook命令調用執行編排好的playbook,ansible會讀取playbook中的每一條play和task,並按照playbook中的順序從上至下依次執行,ansible會調用每個task中定義的模塊去依次執行相應的任務,並按照playbook中指定的主機去主機清單里匹配對應的主機,然後通過ssh認證,把編譯好的相應的任務文件發送到對應的主機或網絡設備上執行,最後返回執行的狀態。
二、YAML簡介
playbook採用yaml語言編寫,yaml是一個可讀性高的用來表達資料序列格式的語言,它參考了其他很多種語言,包括:XML、C語言、python、perl以及电子郵箱格式RFC2822等。Clark Evans在2001年首次發表了這種語言,另外Ingy döt Net與Oren Ben-Kiki也是這語言的共同設計者。YAML( YAML Ain’t Markup Language),即yaml不是標記語言。不過在開發這種語言時,yaml的意思其實是:”Yet Another Markup Language”(仍是一種標記語言)
ymal特性
1)YAML的可讀性好
2)YAML和腳本語言的交互性好
3)YAML使用實現語言的數據類型
4)YAML有一個一致的信息模板
5)YAML易於實現,可以基於流程處理,表達能力強,擴展性好
更多的內容及規範請參考官方文檔
三、playbook語法簡介
1)需要以“—”(3個減號)開始,且需頂行首寫。另外還有選擇性的連續三個點號(…)用來表示文件的結尾。
2)次行開始正常寫playbook的內容,建議次行寫該playbook的功能,當然不寫也是可以的。
3)使用“#”號註釋代碼。
4)縮進必須統一,不能空格tab混用。
5)縮進的級別必須是一致的,同樣的縮進代表同樣級別,程序判別配置的級別是通過縮進結合換行來實現的。
6)YAML文件內容和Linux系統大小寫判斷方式一直,區分大小寫(大小寫敏感),k/v的值均大小寫敏感。
7)k/v的值可同行寫也可換行寫。同行使用“:”分隔,換行寫需要以“-”分隔。
8)v可以是字符串,也可以另外一個列表,當然也可以是字典。
9)一個完整的代碼塊功能最少需要有name:xxx(對任務的描述)。
10)一個name只能包括一個task
11)yaml文件擴展名通常為yml或yaml
list:列表,其所有元素均使用“-”開頭
示例:
--- # A list of tasty fruits - apple - orange - strawberry - mango ~
dictionary:字典,通常由多個key與value構成
示例:
--- #An employee record name: example developer job: developer skill: elite
當然也可以將key:value放置於{}中進行表示,用“,”分隔多個key:value
示例:
---
#An employee record
{name: example developer,job: developer, skill: elite}
~
YAML的語法和其他高階語言類似,並且可以簡單表達清單、散列表、標量等數據結構。其結構(Structure)通過空格來展示,序列(Sequence)里的項用”-“來代表,Map里的鍵值對用”:”分隔。
示例:
---
name: John Smith
age: 41
gender: Male
spouse:
name: Jane Smith
age: 37
gender: Female
children:
- name: Jimmy Smith
age: 17
gender: Male
- name: Jenny Smith
age: 13
gender: Female
~
四、playbook核心元素
1)hosts :指定執行任務的遠程主機列表(主機清單定義的主機組或單個主機,支持前面的說的主機模式匹配)
2)tasks :任務集
3)varniables :內置變量或自定義變量在playbook中調用
4)templates :模板,可替換模板文件中的變量並實現一些簡單邏輯的文件
5)handlers 和 notity結合使用,由特定條件出發的操作,滿足條件方才執行,否則不執行
6)tags標籤 :給指定的任務貼上標籤,我們在執行playbook的時候可以根據標籤選擇性的挑選部分代碼執行,如 ansible-playbook -t tagsname useradd.yml ,這條命令的意思就是在useradd.yml中挑選標籤名為tagsname的任務執行
五、playbook基礎組件
1)hosts:
playbook中的每一個play的目的都是為了讓特定主機以某個指定的用戶身份執行任務。hosts用於指定要執行任務的主機,須事先定義在主機清單中。hosts指定主機的形式同樣支持像主機清單中定義的那樣,支持通配,支持主機模式匹配與或非,支持IP地址,當然也支持混合匹配與或非。
示例:在websers組,但不再dbsers組,可以這樣定義hosts
--- - hosts: websers:!dbsers
2)remote_user:可用於host和task中,也可以通過指定其通過sudo的方式在遠程執行任務,其可用於play全局或某個任務;此外,甚至可以在sudo時使用用sudo_user指定sudo時切換的用戶,如下所示
---
- hosts: websers:!dbsers
remote_user: root
tasks:
- name: test connection
ping:
remote_user: qiuhom
sudo: yes
sudo_user: qiuping
說明:默認sudo 為root,上例指定了sudo_user 為qiuping,上述任務同sudo -u qiuping ping xxxx(代表某主機)命令一樣的意思,當然在使用sudo 時 我們還需要在目標主機上對qiuhom授權,要讓qiuhom這個用戶具有代表qiuping的權限去執行ping命令。
3)task列表和action:play的主體部分是task list,task list 中的各任務按次序逐個在hosts中指定的所有主機上執行,即在所有主機上完成第一個任務后,再開始第二個任務;task的目的是使用指定的參數執行模塊,而在模塊參數中可以使用變量,模塊執行時是冪等的,這意味着多次執行時是安全的,其結果均一致;每個task都應該有其name,用於playbook的執行結果輸出,建議其內容能清晰地描述任務步驟,如未提供name,則action的結果將用於輸出。
tasks:任務列表,它有兩種格式如下
(1)action: module arguments
(2)module: arguments ##建議使用
注意:shell模塊和command模塊後面跟的是命令,而非key=value
如果某項任務的狀態在運行後為changed時,可通過“notify”通知給相應的handlers;當然任務可以通過“tags”打標籤,可以在ansible-playbook命令上使用-t指定進行指定其標籤名調用。
示例:
[qiuhom@test ~]$cat test.yml
---
- hosts: websers:!dbsers
remote_user: root
tasks:
- name: test connection
ping:
remote_user: qiuhom
sudo: yes
sudo_user: qiuping
tags: test
- name: test command
shell: /bin/ls /home/qiuhom/
[qiuhom@test ~]$ansible-playbook -t test test.yml
說明:用-t 指定標籤名,表示只運行所指定標籤所在的任務,當然同名的標籤可以在多條任務中,一個任務也可以有多個標籤。
如果命令或腳本的退出碼不為零,可用使用如下方式忽略或跳過繼續執行以下代碼
---
- hosts: websers:!dbsers
remote_user: root
tasks:
- name: run this command and ignore the result
shell: /usr/sbin/ip addr show eth0 || /bin/true
- name: run this command and ignore the result
shell: /usr/sbin/ip addr show eth0
ignore_errors: True
說明:兩種方式都可以跳過出錯的命令而不打斷playbook,繼續執行以下的代碼,前者使用的短路或的特性,後者使用ignore_errors參數來控制
六、playbook運行的方式
ansible-playbook <filename.yml> ... [options]
常用選項:
-C , –check : 只檢查可能會發生的改變,但不真正執行操作,相當於空跑一遍playbook,測試下是否和自己預想的結果一樣,但它不會真正的去遠端主機上執行。常用於測試寫的playbook語法是否有誤。
–list-hosts :列出playbook指定運行任務所匹配的主機
–list-tags :列出playbook中所有標籤名稱列表
–list-tasks :列出playbook中所有任務名稱及標籤名稱
–limit 主機列表 :只針對指定主機列表中的主機執行當前playbook(指定主機列表必須是在playbook里定義的主機列表範圍內)
-v,-vv,-vvv : 显示執行playbook的過程,-v,显示較簡單,-vv显示較詳細,-vvv显示整個過程(非常詳細)
[root@test ~]#cat test.yml
---
- hosts: websers
remote_user: root
tasks:
- name: run this command
shell: hostname
tags: hostname
ignore_errors: True
- name: show ip addr
shell: /sbin/ip addr show
tags: showip
[root@test ~]#ansible-playbook test.yml --list-hosts
playbook: test.yml
play #1 (websers): websers TAGS: []
pattern: [u'websers']
hosts (2):
192.168.0.128
192.168.0.218
[root@test ~]#ansible-playbook test.yml --list-tags
playbook: test.yml
play #1 (websers): websers TAGS: []
TASK TAGS: [hostname, showip]
[root@test ~]#ansible-playbook test.yml --list-tasks
playbook: test.yml
play #1 (websers): websers TAGS: []
tasks:
run this command TAGS: [hostname]
show ip addr TAGS: [showip]
[root@test ~]#ansible-playbook test.yml --limit 192.168.0.218
PLAY [websers] ********************************************************************************************************
TASK [Gathering Facts] ************************************************************************************************
ok: [192.168.0.218]
TASK [run this command] ***********************************************************************************************
changed: [192.168.0.218]
TASK [show ip addr] ***************************************************************************************************
changed: [192.168.0.218]
PLAY RECAP ************************************************************************************************************
192.168.0.218 : ok=3 changed=2 unreachable=0 failed=0
[root@test ~]#ansible-playbook test.yml --limit 192.168.0.218 -v
Using /etc/ansible/ansible.cfg as config file
PLAY [websers] ********************************************************************************************************
TASK [Gathering Facts] ************************************************************************************************
ok: [192.168.0.218]
TASK [run this command] ***********************************************************************************************
changed: [192.168.0.218] => {"changed": true, "cmd": "hostname", "delta": "0:00:00.002139", "end": "2019-11-16 23:11:02.996962", "rc": 0, "start": "2019-11-16 23:11:02.994823", "stderr": "", "stderr_lines": [], "stdout": "localhost.localdomain", "stdout_lines": ["localhost.localdomain"]}
TASK [show ip addr] ***************************************************************************************************
changed: [192.168.0.218] => {"changed": true, "cmd": "/sbin/ip addr show", "delta": "0:00:00.002604", "end": "2019-11-16 23:11:03.733004", "rc": 0, "start": "2019-11-16 23:11:03.730400", "stderr": "", "stderr_lines": [], "stdout": "1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN \n link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00\n inet 127.0.0.1/8 scope host lo\n inet6 ::1/128 scope host \n valid_lft forever preferred_lft forever\n2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000\n link/ether 00:0c:29:e8:f6:7b brd ff:ff:ff:ff:ff:ff\n inet 192.168.0.218/24 brd 192.168.0.255 scope global eth0\n inet6 fe80::20c:29ff:fee8:f67b/64 scope link \n valid_lft forever preferred_lft forever\n3: pan0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN \n link/ether d2:7a:38:cf:27:60 brd ff:ff:ff:ff:ff:ff", "stdout_lines": ["1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN ", " link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00", " inet 127.0.0.1/8 scope host lo", " inet6 ::1/128 scope host ", " valid_lft forever preferred_lft forever", "2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000", " link/ether 00:0c:29:e8:f6:7b brd ff:ff:ff:ff:ff:ff", " inet 192.168.0.218/24 brd 192.168.0.255 scope global eth0", " inet6 fe80::20c:29ff:fee8:f67b/64 scope link ", " valid_lft forever preferred_lft forever", "3: pan0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN ", " link/ether d2:7a:38:cf:27:60 brd ff:ff:ff:ff:ff:ff"]}
PLAY RECAP ************************************************************************************************************
192.168.0.218 : ok=3 changed=2 unreachable=0 failed=0
[root@test ~]#
說明:–limit 所指定的主機必須是在playbook中所指定的主機範圍內。
七、playbook vs shell scripts
1)shell腳本如下:
#!/bin/bash # 安裝Apache yum install --quiet -y httpd # 複製配置文件 cp /tmp/httpd.conf /etc/httpd/conf/httpd.conf cp/tmp/vhosts.conf /etc/httpd/conf.d/ # 啟動Apache,並設置開機啟動 service httpd start chkconfig httpd on
2)playbook
---
- hosts: websers
remote_user: root
tasks:
- name: create apache group
group: name=apache gid=80 system=yes
- name: create apache user
user: name=apache uid=80 group=apache system=yes shell=/sbin/nologin home=/var/www/html
- name: install httpd
yum: name=httpd
- name: copy config file
copy: src=/tmp/httpd.conf dest=/etc/httpd/conf/
- name: copy config 2 file
copy: src=/tmp/vhosts.conf dest=/etc/httpd/conf.d/
- name: start httpd service
service: name=httpd state=started enabled=yes
說明:兩者都是實現同樣的目的,很明顯playbook的優勢要比腳本的優勢多,playbook 可以針對很多台主機進行任務執行,而腳本只可以在某一台主機上執行;腳本重複執行沒有冪等性,很有可能帶來很多錯誤,而playbook卻不會有這樣的苦惱。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益