知識需要不斷積累、總結和沉澱,思考和寫作是成長的催化劑
內容目錄
一、線程Thread
.NET中線程操作封裝為了Thread類,可以讓開發者對線程進行直觀操作。Thread提供了實例方法用於管理線程的生命周期和靜態方法用於控制線程的一些訪問存儲等一些外在的屬性,相當於工作空間環境變量了
1、生命周期
線程的生命周期有創建、啟動、可能掛起、等待、恢復、異常、然後結束。用Thread類可以容易控制一個線程的全生命周期
Thread類的構造函數重載可以接受ThreadStart無參數和ParameterizedThreadStart有參數的委託,然後調用實例的Start()方法啟動線程。Thread的構造函數的帶有參數的委託,參數是一個object類型,因為我們可以傳入任何信息
Thread t1 = new Thread(() => {
Console.WriteLine($"新線程 {Thread.CurrentThread.ManagedThreadId.ToString("00")}");
});
t1.Start();
Thread t2 = new Thread((obj) => {
Console.WriteLine($"新線程 {Thread.CurrentThread.ManagedThreadId.ToString("00")},參數 {obj.ToString()}");
});
t2.Start("hello kitty");
線程啟動后,可以調用線程的Suspend()掛起線程,線程就會處於休眠狀態(不繼續執行線程內代碼),調用Resume()喚醒線程,還有一個不太建議使用的Abort()通過拋出異常的方式來銷毀線程,隨後線程的狀態就會變為AbortRequested
常用的還有線程的等待,在主線程上啟用工作線程后,有時需要等待工作線程的完成后,主線程才繼續工作。可以調用實例方法Join(),當然我們可以傳入時間參數來表明我主線程最多等你多久
2、後台線程
上一章我們知道Thread默認創建的是前台線程,前台線程會阻止系統進程的退出,就是啟動之後一定要完成任務的,後台線程會伴隨着進程的退出而退出。通過設置屬性IsBackground=true改為後台線程。另外還可以通過設置Priority指定線程的優先級。但這個並不總會如你所想設置了高優先級就一定最先執行。操作系統會優化調度,這也是線程不太好控制的原因之一
3、靜態方法
上面介紹的都是Tread的實例方法,Thread還有一些常用靜態方法。有時線程設置不當,會有些意想不到的的bug
1.線程本地存儲
AllocateDataSlot和AllocateNamedDataSlot用於給所有線程分配一個數據槽。像下面例子所示,如果不在子線程中給數據槽中放入數據,是獲取不到其他線程往裡面放的數據。
var slot= Thread.AllocateNamedDataSlot("testSlot");
//Thread.FreeNamedDataSlot("testSlot");
Thread.SetData(slot, "hello kitty");
Thread t1 = new Thread(() => {
//Thread.SetData(slot, "hello kitty");
var obj = Thread.GetData(slot);
Console.WriteLine($"子線程:{obj}");//obj沒有值
});
t1.Start();
var obj2 = Thread.GetData(slot);
Console.WriteLine($"主線程:{obj2}");
在聲明數據槽的時候.NET提醒我們如果要更好的性能,請使用ThreadStaticAttribute標記字段。什麼意思?我們來看下面這個例子
//
// 摘要:
// 在所有線程上分配未命名的數據槽。 為了獲得更好的性能,請改用以 System.ThreadStaticAttribute 特性標記的字段。
//
// 返回結果:
// 所有線程上已分配的命名數據槽。
public static LocalDataStoreSlot AllocateDataSlot();
例子中的如果不在靜態字段上標記ThreadStatic輸出結果就會一致。ThreadStatic標記指示各線程的靜態字段值是否唯一
[ThreadStatic]
static string name = string.Empty;
public void Function()
{
name = "kitty";
Thread t1 = new Thread(() => {
Console.WriteLine($"子線程:{name}");//輸出空
});
t1.Start();
Console.WriteLine($"主線程:{name}");//輸出kitty
}
還有一個ThreadLocal提供線程數據的本地存儲,用法和上面一樣,在每個線程中聲明數據僅供自己使用
ThreadLocal<string> local = new ThreadLocal<string>() { };
local.Value = "hello kitty";
Thread t = new Thread(() => {
Console.WriteLine($"子線程:{local.Value}");
});
t.Start();
Console.WriteLine($"主線程:{local.Value}");
上面的靜態方法用於線程的本地存儲TLS(Thread Local Storage),Thread.Sleep方法在開發調試時也是經常用的,讓線程掛起指定的時間來模擬耗時操作
2.內存柵欄
先說一個常識問題,為什麼我們發布版本時候要用Release發布?Release更小更快,做了很多優化,但優化對我們是透明的(計算機里透明認為是個黑盒子,內部邏輯細節對我們不開放,和生活中透明意味着完全掌握了解不欺瞞剛好相反),一般優化不會影響程序的運行,我們先借用網上的一個例子
bool isStop = false;
Thread t = new Thread(() => {
bool isSuccess = false;
while (!isStop)
{
isSuccess = !isStop;
}
});
t.Start();
Thread.Sleep(1000);
isStop = true;
t.Join();
Console.WriteLine("主線程執行結束");
上面例子如果在debug下能正確執行完直到輸出“主程序執行結束”,然而在release下卻一直會等待子線程的完成。這裏子線程中isStop一直為false。首先這是一個由多線程共享變量引起的問題,所以我們建議最好的解決辦法就是盡量不共享變量,其次可以使用Thread.MemoryBarrier和VolatileRead/Write以及其他鎖機制犧牲一點性能來換取數據的安全。(上面例子測試如果在子線程while中進行Console.writeLine操作,奇怪的發現release下也能正常輸出了,猜測應該是進行了內存數據的更新)
release優化會將t線程中的isStop變量的值加載到CPU Cache中,而主線程修改了isStop值在內存中,所以子線程拿不到更新后的值,造成數據不一致。那麼解決辦法就是取值時從內存中獲取。Thread.MemoryBarrier()就可以讓在此方法之前的內存寫入都及時的從CPU Cache中更新到內存中,在此之後的內存讀取都要從內存中獲取,而不是CPU Cache。在例子中的while內增加Thread.MemoryBarrier()就能避免數據不一致問題。VolatileRead/Write是對MemoryBarrier的分開解釋,從處理器讀取,從處理器寫入。
4、返回值
前面聲明線程時,可以傳遞參數,那麼想要有返回值該如何去做呢?Thread並沒有提供返回值的操作,後面.NET給出的對Thead的高級封裝給出了解決方案,直接使用即可。那目前我們使用thread類就要自己實現下帶有返回值的線程操作,都是通過委託實現的,這裏簡單介紹一種,(共享外部變量也是可以,不建議)
private Func<T> ThreadWithReturn<T>(Func<T> func)
{
T t = default(T);
Thread thread = new Thread(() =>
{
t = func.Invoke();
});
thread.Start();
return () =>
{
thread.Join();
return t;
};
}
//調用
Func<int> func = this.ThreadWithReturn<int>(() =>
{
Thread.Sleep(2000);
return DateTime.Now.Millisecond;
});
int iResult = func.Invoke();
二、線程池ThreadPool
.NET起初提供Thread線程類,功能很豐富,API也很多,所以使用起來比較困難,況且線程還不都是很像理想中運行,所以從2.0開始提供了ThreadPool線程池靜態類,全是靜態方法,隱藏了諸多Thread的接口,讓線程使用起來更輕鬆。線程池可用於執行任務、發送工作項、處理異步 I/O、代表其他線程等待以及處理計時器。
1、工作隊列
常用ThreadPool線程池靜態方法QueueUserWorkItem用於將方法排入線程池隊列中執行,如果線程池中有閑置線程就會執行,QueueUserWorkItem方法的參數可以指定一個回調函數委託並且傳入參數,像下面這樣
ThreadPool.QueueUserWorkItem((obj) => {
Console.WriteLine($"線程池中線程 {Thread.CurrentThread.ManagedThreadId.ToString("00")} ,傳入 {obj.ToString()}");
},"hello kitty");
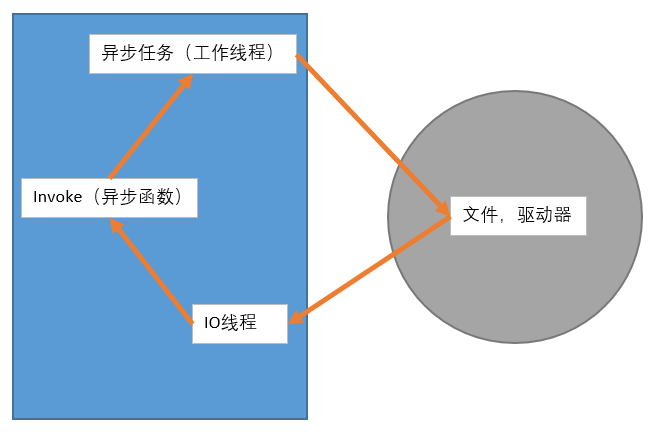
2、工作線程和IO線程
一般異步任務的執行,不涉及到網絡文件等IO操作的,計算密集型,開發者來調用。而IO線程一般用在文件網絡上,是CLR調用的,開發者無需管。工作線程發起文件訪問調用,由驅動器完成后通知IO線程,IO線程則執行異步任務的回調函數
獲取和設置最小最大的工作線程和IO線程
ThreadPool.GetMaxThreads(out int workerThreads, out int completionPortThreads);
ThreadPool.GetMinThreads(out int workerThreads, out int completionPortThreads);
ThreadPool.SetMaxThreads(16, 16);
ThreadPool.SetMinThreads(8, 8);
3、和Thread區別
如果計算機只有8個核,同時可以有8個任務運行。現在我們有10個任務需要運行,用Thread就需要創建10個線程,用ThreadPool可能只需要利用8個線程就行,節約了空間和時間。線程池中的線程默認先啟動最小線程數量的線程,然後根據需要增減數量。線程池使用起來簡單,但也有一些限制,線程池中的線程都是後台線程,不能設置優先級,常用於耗時較短的任務。線程池中線程也可以阻塞等待,利用ManualResetEvent去通知,但一般不會使用。
4、定時器
.NET中有很多可以實現定時器的功能,在ThreadPool中,我們可以利用RegisterWaitForSingleObject來註冊一個指定時間的委託等待。像下面這樣,將每隔一秒就輸出消息
ThreadPool.RegisterWaitForSingleObject(new AutoResetEvent(true), new WaitOrTimerCallback((obj, b) =>
{
Console.WriteLine($"obj={obj},tid={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
}),"hello kitty",1000,false);
我們平常見過比較多的還是timer類,timer類在.net內是好幾個地方都有的,在System.Threading、
System.Timer、System.Windows.Form、System.Web.UI等裏面都有Timer,後面都是在第一個System.Threading里的Timer擴展
System.Threading.Timer timer = new System.Threading.Timer((obj) =>
{
Console.WriteLine($"obj={obj},tid={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
},"hello kitty",1000,1000);
timer的底層有一個TimerQueue,利用ThreadPool.UnsafeQueueUserWorkItem來完成定時功能,和上面我們使用的ThreadPool定時器有一點區別
實際開發中,簡單定時timer就夠用,但一般業務場景比較複雜,需要定製個性化的定時器,比如每月幾號執行,每月第幾個星期幾,幾點執行,工作日執行等。因此我們使用Quarz.NET定時框架,後面框架整合時會用到,用起來也是很簡單的
先就啰嗦這兩點吧,下一篇應該是Task、Parallel以及Async/Await,然後總結介紹下C#的線程模式、線程同步鎖機制、異常處理,線程取消,線程安全集合和常見的線程問題
天長水闊,見字如面,隨緣更新,拜了個拜~
可關注主頁公號獲取更多哈
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!