點贊再看,養成習慣,微信搜索【三太子敖丙】關注這個互聯網苟且偷生的工具人。
本文 GitHub https://github.com/JavaFamily 已收錄,有一線大廠面試完整考點、資料以及我的系列文章。
前言
鎖我想不需要我過多的去說,大家都知道是怎麼一回事了吧?
在多線程環境下,由於上下文的切換,數據可能出現不一致的情況或者數據被污染,我們需要保證數據安全,所以想到了加鎖。
所謂的加鎖機制呢,就是當一個線程訪問該類的某個數據時,進行保護,其他線程不能進行訪問,直到該線程讀取完,其他線程才可使用。
還記得我之前說過Redis在分佈式的情況下,需要對存在併發競爭的數據進行加鎖,老公們十分費解,Redis是單線程的嘛?為啥還要加鎖呢?
看來老公們還是年輕啊,你說的不需要加鎖的情況是這樣的:
單個服務去訪問Redis的時候,確實因為Redis本身單線程的原因是不用考慮線程安全的,但是,現在有哪個公司還是單機的呀?肯定都是分佈式集群了嘛。
老公們你看下這樣的場景是不是就有問題了:
你們經常不是說秒殺嘛,拿到庫存判斷,那老婆告訴你分佈式情況就是會出問題的。
我們為了減少DB的壓力,把庫存預熱到了KV,現在KV的庫存是1。
- 服務A去Redis查詢到庫存發現是1,那說明我能搶到這個商品對不對,那我就準備減一了,但是還沒減。
- 同時服務B也去拿發現也是1,那我也搶到了呀,那我也減。
- C同理。
- 等所有的服務都判斷完了,你發現誒,怎麼變成-2了,超賣了呀,這下完了。
老公們是不是發現問題了,這就需要分佈式鎖的介入了,我會分三個章節去分別介紹分佈式鎖的三種實現方式(Zookeeper,Redis,MySQL),說出他們的優缺點,以及一般大廠的實踐場景。
正文
一個騷里騷氣的面試官啥也沒拿的就走了進來,你一看,這不是你老婆嘛,你正準備叫他的時候,發現他一臉嚴肅,死鬼還裝嚴肅,肯定會給我放水的吧。
B站搜:三太子敖丙
咳咳,我們啥也不說了,開始今天的面試吧。
正常線程進程同步的機制有哪些?
- 互斥:互斥的機制,保證同一時間只有一個線程可以操作共享資源 synchronized,Lock等。
- 臨界值:讓多線程串行話去訪問資源
- 事件通知:通過事件的通知去保證大家都有序訪問共享資源
- 信號量:多個任務同時訪問,同時限制數量,比如發令槍CDL,Semaphore等
那分佈式鎖你了解過有哪些么?
分佈式鎖實現主要以Zookeeper(以下簡稱zk)、Redis、MySQL這三種為主。
那先跟我聊一下zk吧,你能說一下他常見的使用場景么?
他主要的應用場景有以下幾個:
- 服務註冊與訂閱(共用節點)
- 分佈式通知(監聽znode)
- 服務命名(znode特性)
- 數據訂閱、發布(watcher)
- 分佈式鎖(臨時節點)
zk是啥?
他是個數據庫,文件存儲系統,並且有監聽通知機制(觀察者模式)
存文件系統,他存了什麼?
節點
zk的節點類型有4大類
-
持久化節點(zk斷開節點還在)
-
持久化順序編號目錄節點
-
臨時目錄節點(客戶端斷開後節點就刪除了)
-
臨時目錄編號目錄節點
節點名稱都是唯一的。
節點怎麼創建?
我特么,這樣問的么?可是我面試只看了分佈式鎖,我得好好想想!!!
還好我之前在自己的服務器搭建了一個zk的集群,我剛好跟大家回憶一波。
create /test laogong // 創建永久節點
那臨時節點呢?
create -e /test laogong // 創建臨時節點
臨時節點就創建成功了,如果我斷開這次鏈接,這個節點自然就消失了,這是我的一個zk管理工具,目錄可能清晰點。
如何創建順序節點呢?
create -s /test // 創建順序節點
臨時順序節點呢?
我想聰明的老公都會搶答了
create -e -s /test // 創建臨時順序節點
我退出后,重新連接,發現剛才創建的所有臨時節點都沒了。
開篇演示這麼多呢,我就是想給大家看到的zk大概的一個操作流程和數據結構,中間涉及的搭建以及其他的技能我就不說了,我們重點聊一下他在分佈式鎖中的實現。
zk就是基於節點去實現各種分佈式鎖的。
就拿開頭的場景來說,zk應該怎麼去保證分佈式情況下的線程安全呢?併發競爭他是怎麼控制的呢?
為了模擬併發競爭這樣一個情況,我寫了點偽代碼,大家可以先看看
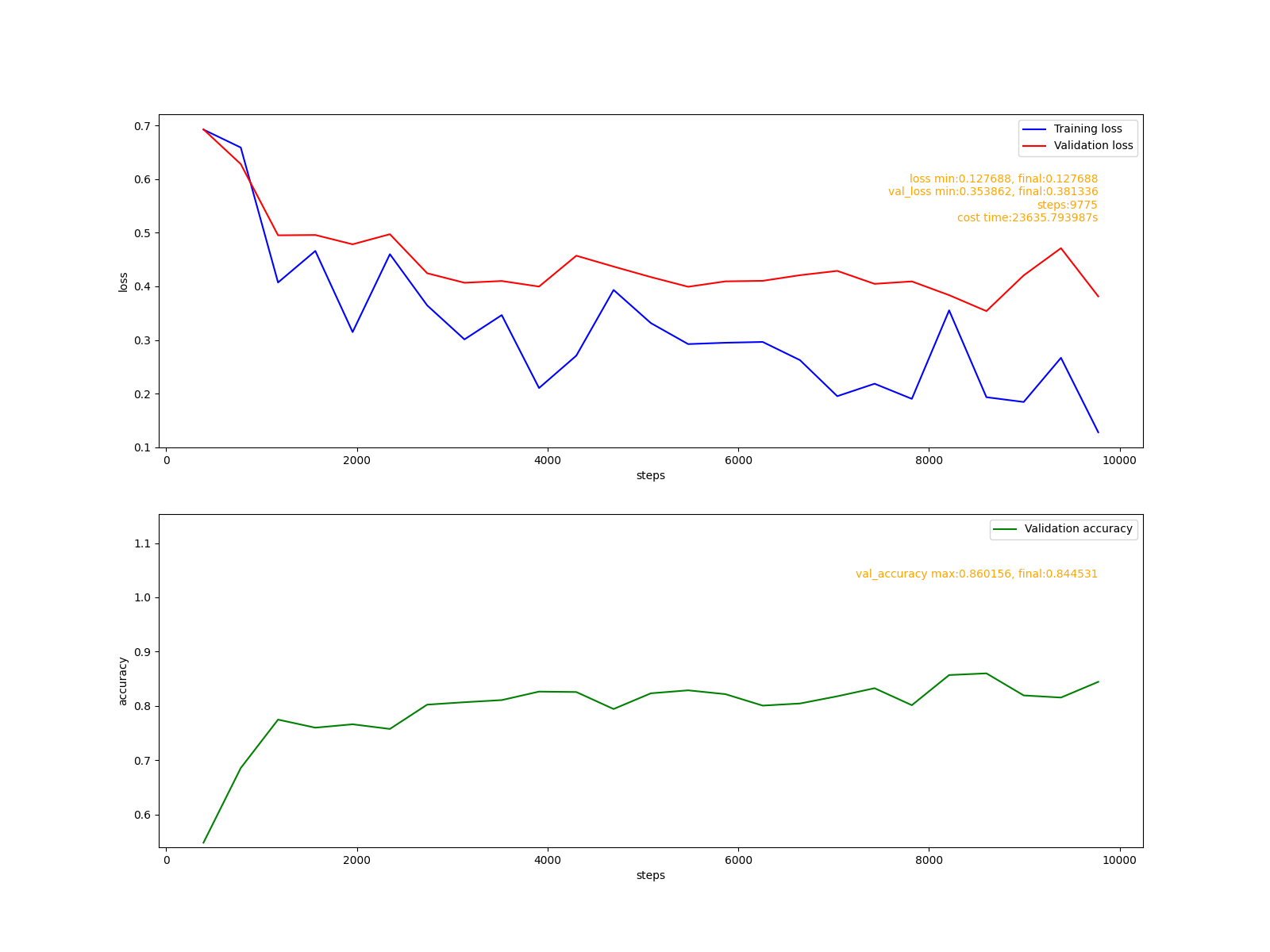
我定義了一個庫存inventory值為1,還用到了一個CountDownLatch發令槍,等10個線程都就緒了一起去扣減庫存。
是不是就像10台機器一起去拿到庫存,然後扣減庫存了?
所有機器一起去拿,發現都是1,那大家都認為是自己搶到了,都做了減一的操作,但是等所有人都執行完,再去set值的時候,發現其實已經超賣了,我打印出來給大家看看。
是吧,這還不是超賣一個兩個的問題,超賣7個都有,代碼裏面明明判斷了庫存大於0才去減的,怎麼回事開頭我說明了。
那怎麼解決這個問題?
sync,lock也只能保證你當前機器線程安全,這樣分佈式訪問還是有問題。
上面跟大家提到的zk的節點就可以解決這個問題。
zk節點有個唯一的特性,就是我們創建過這個節點了,你再創建zk是會報錯的,那我們就利用一下他的唯一性去實現一下。
怎麼實現呢?
上面不是10個線程嘛?
我們全部去創建,創建成功的第一個返回true他就可以繼續下面的扣減庫存操作,後續的節點訪問就會全部報錯,扣減失敗,我們把它們丟一個隊列去排隊。
那怎麼釋放鎖呢?
刪除節點咯,刪了再通知其他的人過來加鎖,依次類推。
我們實現一下,zk加鎖的場景。
是不是,只有第一個線程能扣減成功,其他的都失敗了。
但是你發現問題沒有,你加了鎖了,你得釋放啊,你不釋放後面的報錯了就不重試了。
那簡單,刪除鎖就釋放掉了,Lock在finally裏面unLock,現在我們在finally刪除節點。
加鎖我們知道創建節點就夠了,但是你得實現一個阻塞的效果呀,那咋搞?
死循環,遞歸不斷去嘗試,直到成功,一個偽裝的阻塞效果。
怎麼知道前面的老哥刪除節點了嗯?
監聽節點的刪除事件
但是你發現你這樣做的問題沒?
是的,會出現死鎖。
第一個仔加鎖成功了,在執行代碼的時候,機器宕機了,那節點是不是就不能刪除了?
你要故作沉思,自問自答,時而看看遠方,時而看看面試官,假裝自己什麼都不知道。
哦我想起來了,創建臨時節點就好了,客戶端連接一斷開,別的就可以監聽到節點的變化了。
嗯還不錯,那你發現還有別的問題沒?
好像這種監聽機制也不好。
怎麼個不好呢?
你們可以看到,監聽,是所有服務都去監聽一個節點的,節點的釋放也會通知所有的服務器,如果是900個服務器呢?
這對服務器是很大的一個挑戰,一個釋放的消息,就好像一個牧羊犬進入了羊群,大家都四散而開,隨時可能幹掉機器,會佔用服務資源,網絡帶寬等等。
這就是羊群效應。
那怎麼解決這個問題?
繼續故作沉思,啊啊啊,好難,我的腦袋。。。。
你TM別裝了好不好?
好的,臨時順序節點,可以順利解決這個問題。
怎麼實現老公你先別往下看,先自己想想。
之前說了全部監聽一個節點問題很大,那我們就監聽我們的前一個節點,因為是順序的,很容易找到自己的前後。
和之前監聽一個永久節點的區別就在於,這裏每個節點只監聽了自己的前一個節點,釋放當然也是一個個釋放下去,就不會出現羊群效應了。
以上所有代碼我都會開源到我的https://github.com/AobingJava/Thanos其實上面的還有瑕疵,大家可以去拉下來改一下提交pr,我會看合適的會通過的。
你說了這麼多,挺不錯的,你能說說ZK在分佈式鎖中實踐的一些缺點么?
Zk性能上可能並沒有緩存服務那麼高。
因為每次在創建鎖和釋放鎖的過程中,都要動態創建、銷毀瞬時節點來實現鎖功能。
ZK中創建和刪除節點只能通過Leader服務器來執行,然後將數據同步到所有的Follower機器上。(這裏涉及zk集群的知識,我就不展開了,以後zk章節跟老公們細聊)
還有么?
使用Zookeeper也有可能帶來併發問題,只是並不常見而已。
由於網絡抖動,客戶端可ZK集群的session連接斷了,那麼zk以為客戶端掛了,就會刪除臨時節點,這時候其他客戶端就可以獲取到分佈式鎖了。
就可能產生併發問題了,這個問題不常見是因為zk有重試機制,一旦zk集群檢測不到客戶端的心跳,就會重試,Curator客戶端支持多種重試策略。
多次重試之後還不行的話才會刪除臨時節點。
Tip:所以,選擇一個合適的重試策略也比較重要,要在鎖的粒度和併發之間找一個平衡。
有更好的實現么?
基於Redis的分佈式鎖
能跟我聊聊么?
我看看了手上的表,老公,今天天色不早了,你全問完了,我怎麼多水幾篇文章呢?
行確實很晚了,那你回家去把家務幹了吧?
我????
=
總結
zk通過臨時節點,解決掉了死鎖的問題,一旦客戶端獲取到鎖之後突然掛掉(Session連接斷開),那麼這個臨時節點就會自動刪除掉,其他客戶端自動獲取鎖。
zk通過節點排隊監聽的機制,也實現了阻塞的原理,其實就是個遞歸在那無限等待最小節點釋放的過程。
我上面沒實現鎖的可重入,但是也很好實現,可以帶上線程信息就可以了,或者機器信息這樣的唯一標識,獲取的時候判斷一下。
zk的集群也是高可用的,只要半數以上的或者,就可以對外提供服務了。
這周會寫完Redis和數據庫的分佈式鎖的,老公們等好。
我是敖丙,一個在互聯網苟且偷生的工具人。
最好的關係是互相成就,老公們的「三連」就是丙丙創作的最大動力,我們下期見!
注:如果本篇博客有任何錯誤和建議,歡迎老公們留言,老公你快說句話啊!
文章持續更新,可以微信搜索「 三太子敖丙 」第一時間閱讀,回復【資料】【面試】【簡歷】有我準備的一線大廠面試資料和簡歷模板,本文 GitHub https://github.com/JavaFamily 已經收錄,有大廠面試完整考點,歡迎Star。
你知道的越多,你不知道的越多
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準