原文地址
讓我們從實際需求出發,看看問題出在哪裡,並在此基礎上認識和學習使用 Hazel。
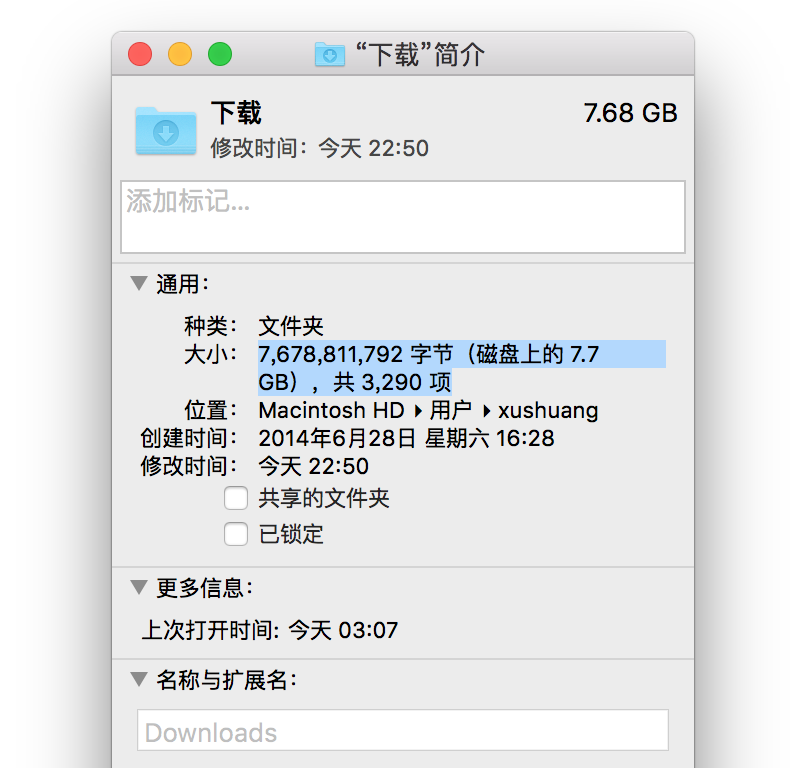
電腦隨着使用時間的增長,其中的文件也在瘋狂的增長,時間長了也就會出現各種混亂:大量文件堆放在一起,舊文件很少清理,分不清哪些文件還有用,找不到需要的文件等等。
今天我們就以「下載」和「桌面」為例,聊一聊如何整理我們的電腦。
Downloads:下載的文件很少處理,時間一長就各種堆積……
Desktop:經常把臨時文件存放在此,方便拖拽使用,但時間一長,就是各種凌亂……
既然知道了問題所在,那麼我們就來着手整理吧。
理清整理思路
首先是確定整理思路,比如如何界定一個文件是否還有用,如何界定它屬於什麼分類等,對應的操作一般是刪除(比如不再需要的或重複的文件)或存檔(學習資料或工作材料等分類存儲),知道如何處理一個文件就很好辦了,剩下的就都是體力活兒。
雖然這不是一件特別麻煩的事,但是我們也經常忘記或「懶得整理」。這有點類似於打掃房間,當我們沒有時間或者經常忘記時,可以買一台掃地機器人幫助我們打掃,同樣的,在 Mac 上也有這樣一台「機器人」,它就是 Hazel。
Hazel 是什麼?
Hazel 是一款可以自動監控並整理文件夾的工具,其官網的介紹就是簡單的一句話:Automated Organization for Your Mac。
它的使用有點類似於網絡服務 IFTTT,你可以設定一個 if 條件,如果被監控的文件夾出現符合條件的項,那麼對其執行 then 的操作(也可以通過郵箱的收件過濾規則來理解)。
Hazel 不是一款新工具,它已經有了很長的歷史,其第一個版本在 2006 年底就已經發布,在今年 5 月 4 號,Hazel 發布了 4.0 版本,新增了規則同步(文末會有介紹)、規則搜索等一系列實用功能。
Hazel 具體能做什麼?
先為大家簡單羅列一些 Hazel 能做到的事情:
- 根據文件創建的時間,自動將文件進行顏色標記(比如將最近的文件標記為藍色)
- 自動的用特定軟件打開某個特定文件(比如下載 BT 種子后,自動用迅雷打開下載)
- 自動刪除已下載過的 BT 種子文件
- 根據文件的類型,自動轉移到相應的文件夾中(比如圖片移動到照片文件夾,電影移動到視頻文件夾等)
- 自動刪除某些特定文件(比如標題中含有固定內容且創建日期在很早以前的)
- 自動將壓縮文件解壓
- 自動幫你清理文件的緩存
- 自動幫你整理照片,可以按照「年 – 月」來分類存儲到相應文件夾
- 自動把文件夾中的內容上傳到 FTP 等網絡服務中
- 自動將照片導入 Photos,自動將音樂導入 iTunes
- ……
以上只是列舉的一些場景能夠實現的功能,再加上 Hazel 支持 AppleScript、JavaScript、Automator workflow 等代碼指令,令其擴展性更上一層樓,可以做到的事情也可以說只剩下想象力這道門檻了。
介紹了不少,下面我們就從 Hazel 的安裝和實際設置來為大家做一個簡單的入門指南。
Hazel 的安裝
前往下載最新版本,按照提示安裝,完成后 Hazel 會出現在系統設置中(在應用程序中可找不到哦)。
Hazel 是一款收費軟件,初次安裝后可以免費試用 14 天,此時可以選擇加載一些簡單的默認規則以幫助你快速上手(當然看完這篇文章也就可以不用加載了)。
操作后 Hazel 會給我們彈出警告信息:在激活這些規則之前,一定要先檢查它們。具體的方法下面會提及。
Hazel 的界面和基礎應用
注:文末提供了文中所有 Hazel 規則的打包下載地址,如果你對文中介紹的規則感興趣,可以直接下載使用。
Hazel 的主界面包含三部分,分別是設置文件夾規則的 Folders 頁面,設置垃圾箱規則的 Trash 頁面和其他信息頁(Info),今天主要給大家講解文件夾規則設置頁面。
在 Folders 中包含三部份:設置監控的文件夾(圖中 1),設置該文件夾下的具體規則(圖中 2),設置該文件夾的重複文件處理(圖中 3),圖 1 部分右側的 icon 分別表示「暫停規則執行」和「同步」,建議嘗試新規則的時候先暫停執行再進行調試。
以整理「下載」文件夾為例,我個人的需求有如下幾條:
- 最近的下載文件用顏色標籤提醒
- 超過 3 天的文件不再是新文件,去掉顏色標籤
- 對存放超過 3 周的文件需進行處理,將滿足此條件的文件用紅色標記提醒
- 自動刪除已使用的 .torrent 文件
- 將手機截屏的圖片單獨存放
上面幾條是梳理自己的整理需求后,選擇的可以被 Hazel 自動執行的。此時回到 Hazel,我們點擊左下角的加號新增「下載」文件夾,隨後在右側 Rules 區域點擊加號新增規則。
標記最新下載文件
下圖是規則設置界面,圖 1 部分設置規則名稱和註釋;圖 2 部分設置監控條件,此時設置的是文件添加時間在最後匹配時間之前(新文件添加后暫未被匹配,所以一定是早於匹配時間);圖 3 部分設置執行的動作,此時是將匹配出來的文件標記藍色標籤,並且同時可以被其他規則匹配。
標記舊文件
超過 3 天的文件,不再是我需要關注的內容,將其中的藍色標籤去掉:
標記待處理文件
對「下載」文件夾,我需要對超過 3 周未處理的文件進行處理,要麼歸檔要麼刪除,需要進行人工判斷的時候我使用紅色標記來提醒自己:
刪除 .torrent 文件
在使用 BT 下載之後,留在文件夾的種子文件也就沒有什麼用了,為了防止誤刪設置了 5 天的期限,注意圖中綠色符號,那是點擊了 Preview 后的效果,建議設置規則的時候多使用 Preview 功能來檢查條件設置是否正確,特別是那些複雜的符合條件。
自動移動手機截屏文件
工作關係,經常需要在手機上截屏上傳到電腦使用(使用 AirDrop 上傳到「下載」中),這類圖片的處理一般是超過一周后移動到桌面文件夾中再進行集中處理:
上面介紹了「下載」文件夾的整理思路和執行;對於「桌面」文件夾的整理,我的思路一般是不輕易自動刪除(防誤刪),而是統一到分類文件夾中集中處理。將文檔存放於「文檔」中,將圖片存放於「圖片」中等等,都是非常簡單和基礎的設置,就不做過多介紹;
下面說一下我對源文件的處理,這裏涉及到條件的嵌套使用:
圖中使用了嵌套條件,具體的操作是鼠標長按右側加號(也可按住 Option 後點擊),即可增加嵌套條件組。
附上桌面整理后截圖:
Hazel 中級應用
除了以上的基礎使用,Hazel 還可作用於更加廣泛的場景,下面以自動解壓和自動清理緩存為例。
自動解壓
下載壓縮包后不用手動解壓,Hazel 會自動創建文件夾(按照壓縮包的名稱命名),並將壓縮包和解壓后的文件存放於此:
有三點需要為大家說明:
- 設置標籤是為了防止壓縮文件有損壞而導致 Hazel 陷入循環執行中;
- 不能設置自動刪除,因為 Hazel 會自動選中解壓后的文件,此時的刪除也只是把解壓后的文件刪掉;
- 使用默認的「Unarchive」操作也可解壓,不過在解壓 .zip 文件後會自動將壓縮包刪掉,所以我這裏使用了第三方的免費解壓軟件 代替(注意:在第一次執行時需要權限設置);不介意刪除壓縮包的同學使用默認的解壓操作即可。
此規則參考了 的博客,特此感謝。
自動清理緩存
以 QQ 為例,QQ 會把群消息中的圖片自動保存到本地,時間一長這個文件夾就很容易達到幾個 G 的大小,這時候 Hazel 又可以派上用處了。
首先找到你的 QQ 文件夾,可嘗試如下路徑(本人 Mac 系統 10.11)
/Users/用戶名/Library/Containers/com.tencent.qq/Data/Library/Application Support/QQ
將路徑中的「用戶名」換成自己的,然後在 Finder 中按住「⌘ + Shift + G」,把路徑粘貼到輸入框中點擊「前往」即可。
如果路徑沒問題,就可以在 Hazel 中添加此文件夾了,點擊添加按鈕彈出選擇文件夾界面后,使用上述快捷鍵和路徑同樣可以快速選定,添加後設置如下兩條規則,第一條規則的作用是讓所有子文件夾都可以適配規則並執行操作;第二條規則是把超過 500M 的子文件夾進行刪除操作,且不會直接刪除父文件夾。
至此,QQ 緩存文件的自動清理就設置完成了,其他軟件緩存也可以進行類似的規則設計,不過一定要注意確保這裏面沒有你需要的文件,否則一旦刪除要找回也是頗為麻煩的。
更多用法
如前文所說,Hazel 能做到的不止這些場景,還有用戶用它來整理照片,利用 AppleScript 執行更加複雜的工作流程等等,這裏僅當作拋磚引玉,歡迎大家分享自己的用法,並且以後也會有更多關於 Hazel 使用技巧的文章。
其他功能
管理垃圾箱
在 Hazel 的 Trash 頁面,可以進行一些垃圾箱的設置,比如將其中超過一周的文件刪除,保持垃圾箱大小控制在 2GB 左右,選擇刪除時是否使用安全刪除功能,以及卸載應用時檢測其附屬文件夾等等;這方面的功能筆者並不常用,在此不做過多介紹。
刪除應用時檢測相關文件,並可選擇一併刪除。作用類似於 。
同步規則
同步功能在 4.0 終於推出,現在也可以方便的使用在多台電腦上了。點擊左側面板中的齒輪圖標,選擇 Rule Sync Options 即可打開同步界面(也可在文件夾上右鍵選擇 Rule Sync Options)。
同步需要配合第三方同步網盤使用,當前文件夾若是第一次使用同步,需要設置同步文件存放路徑,點擊 Set up new sync file 即可。如果要使用同步的文件,在界面中點擊 Use existing sync file 即可。
Hazel 的下載
Hazel 是一款收費軟件(),五月初的時候發布了 4.0 版本,單獨購買是 $32,Family Pack $49,從 3.0 版本升級需要 $10。初次下載可以免費試用 14 天,建議大家先試用再購買。
最後給大家提供我自己的 Hazel 設置,你可以導入后調整為適合自己的規則再使用:。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!