流式編程作為Java 8的亮點之一,是繼Java 5之後對集合的再一次升級,可以說Java 8幾大特性中,Streams API 是作為Java 函數式的主角來設計的,誇張的說,有了Streams API之後,萬物皆可一行代碼。
什麼是Stream
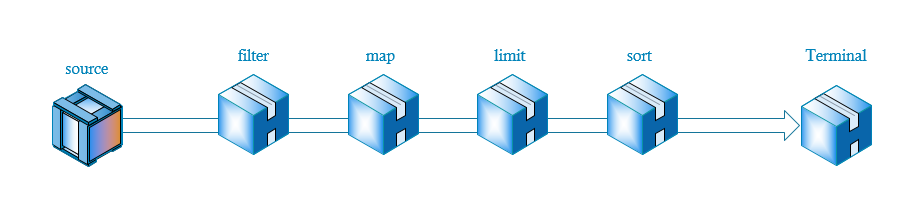
Stream被翻譯為流,它的工作過程像將一瓶水導入有很多過濾閥的管道一樣,水每經過一個過濾閥,便被操作一次,比如過濾,轉換等,最後管道的另外一頭有一個容器負責接收剩下的水。
示意圖如下:
首先通過source產生流,然後依次通過一些中間操作,比如過濾,轉換,限制等,最後結束對流的操作。
Stream也可以理解為一個更加高級的迭代器,主要的作用便是遍歷其中每一個元素。
為什麼需要Stream
Stream作為Java 8的一大亮點,它專門針對集合的各種操作提供各種非常便利,簡單,高效的API,Stream API主要是通過Lambda表達式完成,極大的提高了程序的效率和可讀性,同時Stram API中自帶的并行流使得併發處理集合的門檻再次降低,使用Stream API編程無需多寫一行多線程的大門就可以非常方便的寫出高性能的併發程序。使用Stream API能夠使你的代碼更加優雅。
流的另一特點是可無限性,使用Stream,你的數據源可以是無限大的。
在沒有Stream之前,我們想提取出所有年齡大於18的學生,我們需要這樣做:
List<Student> result=new ArrayList<>();
for(Student student:students){
if(student.getAge()>18){
result.add(student);
}
}
return result;
使用Stream,我們可以參照上面的流程示意圖來做,首先產生Stream,然後filter過濾,最後歸併到容器中。
轉換為代碼如下:
return students.stream().filter(s->s.getAge()>18).collect(Collectors.toList());
- 首先
stream()獲得流
- 然後
filter(s->s.getAge()>18)過濾
- 最後
collect(Collectors.toList())歸併到容器中
是不是很像在寫sql?
如何使用Stream
我們可以發現,當我們使用一個流的時候,主要包括三個步驟:
獲取流
獲取流的方式有多種,對於常見的容器(Collection)可以直接.stream()獲取
例如:
Collection.stream()Collection.parallelStream()Arrays.stream(T array) or Stream.of()
對於IO,我們也可以通過lines()方法獲取流:
java.nio.file.Files.walk()java.io.BufferedReader.lines()
最後,我們還可以從無限大的數據源中產生流:
值得注意的是,JDK中針對基本數據類型的昂貴的裝箱和拆箱操作,提供了基本數據類型的流:
IntStreamLongStreamDoubleStream
這三種基本數據類型和普通流差不多,不過他們流裏面的數據都是指定的基本數據類型。
Intstream.of(new int[]{1,2,3});
Intstream.rang(1,3);
對流進行操作
這是本章的重點,產生流比較容易,但是不同的業務系統的需求會涉及到很多不同的要求,明白我們能對流做什麼,怎麼做,才能更好的利用Stream API的特點。
流的操作類型分為兩種:
-
Intermediate:中間操作,一個流可以後面跟隨零個或多個intermediate操作。其目的主要是打開流,做出某種程度的數據映射/過濾,然後會返回一個新的流,交給下一個操作使用。這類操作都是惰性化的(lazy),就是說,僅僅調用到這類方法,並沒有真正開始流的遍歷。
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
-
Terminal:終結操作,一個流只能有一個terminal操作,當這個操作執行后,流就被使用“光”了,無法再被操作。所以這必定是流的最後一個操作。Terminal操作的執行,才會真正開始流的遍歷,並且會生成一個結果,或者一個 side effect。
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
Intermediate和Terminal完全可以按照上圖的流程圖理解,Intermediate表示在管道中間的過濾器,水會流入過濾器,然後再流出去,而Terminal操作便是最後一個過濾器,它在管道的最後面,流入Terminal的水,最後便會流出管道。
下面依次詳細的解讀下每一個操作所能產生的效果:
中間操作
對於中間操作,所有的API的返回值基本都是Stream<T>,因此以後看見一個陌生的API也能通過返回值判斷它的所屬類型。
map/flatMap
map顧名思義,就是映射,map操作能夠將流中的每一個元素映射為另外的元素。
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
可以看到map接受的是一個Function,也就是接收參數,並返回一個值。
比如:
//提取 List<Student> 所有student 的名字
List<String> studentNames = students.stream().map(Student::getName)
.collect(Collectors.toList());
上面的代碼等同於以前的:
List<String> studentNames=new ArrayList<>();
for(Student student:students){
studentNames.add(student.getName());
}
再比如:將List中所有字母轉換為大寫:
List<String> words=Arrays.asList("a","b","c");
List<String> upperWords=words.stream().map(String::toUpperCase)
.collect(Collectors.toList());
flatMap顧名思義就是扁平化映射,它具體的操作是將多個stream連接成一個stream,這個操作是針對類似多維數組的,比如容器裡面包含容器等。
List<List<Integer>> ints=new ArrayList<>(Arrays.asList(Arrays.asList(1,2),
Arrays.asList(3,4,5)));
List<Integer> flatInts=ints.stream().flatMap(Collection::stream).
collect(Collectors.toList());
可以看到,相當於降維。
filter
filter顧名思義,就是過濾,通過測試的元素會被留下來並生成一個新的Stream
Stream<T> filter(Predicate<? super T> predicate);
同理,我們可以filter接收的參數是Predicate,也就是推斷型函數式接口,接收參數,並返回boolean值。
比如:
//獲取所有大於18歲的學生
List<Student> studentNames = students.stream().filter(s->s.getAge()>18)
.collect(Collectors.toList());
distinct
distinct是去重操作,它沒有參數
Stream<T> distinct();
sorted
sorted排序操作,默認是從小到大排列,sorted方法包含一個重載,使用sorted方法,如果沒有傳遞參數,那麼流中的元素就需要實現Comparable<T>方法,也可以在使用sorted方法的時候傳入一個Comparator<T>
Stream<T> sorted(Comparator<? super T> comparator);
Stream<T> sorted();
值得一說的是這個Comparator在Java 8之後被打上了@FunctionalInterface,其他方法都提供了default實現,因此我們可以在sort中使用Lambda表達式
例如:
//以年齡排序
students.stream().sorted((s,o)->Integer.compare(s.getAge(),o.getAge()))
.forEach(System.out::println);;
然而還有更方便的,Comparator默認也提供了實現好的方法引用,使得我們更加方便的使用:
例如上面的代碼可以改成如下:
//以年齡排序
students.stream().sorted(Comparator.comparingInt(Student::getAge))
.forEach(System.out::println);;
或者:
//以姓名排序
students.stream().sorted(Comparator.comparing(Student::getName)).
forEach(System.out::println);
是不是更加簡潔。
peek
peek有遍歷的意思,和forEach一樣,但是它是一个中間操作。
peek接受一個消費型的函數式接口。
Stream<T> peek(Consumer<? super T> action);
例如:
//去重以後打印出來,然後再歸併為List
List<Student> sortedStudents= students.stream().distinct().peek(System.out::println).
collect(Collectors.toList());
limit
limit裁剪操作,和String::subString(0,x)有點先溝通,limit接受一個long類型參數,通過limit之後的元素只會剩下min(n,size)個元素,n表示參數,size表示流中元素個數
Stream<T> limit(long maxSize);
例如:
//只留下前6個元素並打印
students.stream().limit(6).forEach(System.out::println);
skip
skip表示跳過多少個元素,和limit比較像,不過limit是保留前面的元素,skip是保留後面的元素
Stream<T> skip(long n);
例如:
//跳過前3個元素並打印
students.stream().skip(3).forEach(System.out::println);
終結操作
一個流處理中,有且只能有一個終結操作,通過終結操作之後,流才真正被處理,終結操作一般都返回其他的類型而不再是一個流,一般來說,終結操作都是將其轉換為一個容器。
forEach
forEach是終結操作的遍歷,操作和peek一樣,但是forEach之後就不會再返迴流
void forEach(Consumer<? super T> action);
例如:
//遍歷打印
students.stream().forEach(System.out::println);
上面的代碼和一下代碼效果相同:
for(Student student:students){
System.out.println(sudents);
}
toArray
toArray和List##toArray()用法差不多,包含一個重載。
默認的toArray()返回一個Object[],
也可以傳入一個IntFunction<A[]> generator指定數據類型
一般建議第二種方式。
Object[] toArray();
<A> A[] toArray(IntFunction<A[]> generator);
例如:
Student[] studentArray = students.stream().skip(3).toArray(Student[]::new);
max/min
max/min即使找出最大或者最小的元素。max/min必須傳入一個Comparator。
Optional<T> min(Comparator<? super T> comparator);
Optional<T> max(Comparator<? super T> comparator);
count
count返迴流中的元素數量
long count();
例如:
long count = students.stream().skip(3).count();
reduce
reduce為歸納操作,主要是將流中各個元素結合起來,它需要提供一個起始值,然後按一定規則進行運算,比如相加等,它接收一個二元操作 BinaryOperator函數式接口。從某種意義上來說,sum,min,max,average都是特殊的reduce
reduce包含三個重載:
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
例如:
List<Integer> integers = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
long count = integers.stream().reduce(0,(x,y)->x+y);
以上代碼等同於:
long count = integers.stream().reduce(Integer::sum).get();
reduce兩個參數和一個參數的區別在於有沒有提供一個起始值,
如果提供了起始值,則可以返回一個確定的值,如果沒有提供起始值,則返回Opeational防止流中沒有足夠的元素。
anyMatch allMatch noneMatch
測試是否有任意元素\所有元素\沒有元素匹配表達式
他們都接收一個推斷類型的函數式接口:Predicate
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate)
例如:
boolean test = integers.stream().anyMatch(x->x>3);
findFirst、 findAny
獲取元素,這兩個API都不接受任何參數,findFirt返迴流中第一個元素,findAny返迴流中任意一個元素。
Optional<T> findFirst();
Optional<T> findAny();
也有有人會問findAny()這麼奇怪的操作誰會用?這個API主要是為了在并行條件下想要獲取任意元素,以最大性能獲取任意元素
例如:
int foo = integers.stream().findAny().get();
collect
collect收集操作,這個API放在後面將是因為它太重要了,基本上所有的流操作最後都會使用它。
我們先看collect的定義:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);
可以看到,collect包含兩個重載:
一個參數和三個參數,
三個參數我們很少使用,因為JDK提供了足夠我們使用的Collector供我們直接使用,我們可以簡單了解下這三個參數什麼意思:
Supplier:用於產生最後存放元素的容器的生產者accumulator:將元素添加到容器中的方法combiner:將分段元素全部添加到容器中的方法
前兩個元素我們都很好理解,第三個元素是幹嘛的呢?因為流提供了并行操作,因此有可能一個流被多個線程分別添加,然後再將各個子列表依次添加到最終的容器中。
↓ – – – – – – – – –
↓ — — —
↓ ———
如上圖,分而治之。
例如:
List<String> result = stream.collect(ArrayList::new, List::add, List::addAll);
接下來看只有一個參數的collect
一般來說,只有一個參數的collect,我們都直接傳入Collectors中的方法引用即可:
List<Integer> = integers.stream().collect(Collectors.toList());
Collectors中包含很多常用的轉換器。toList(),toSet()等。
Collectors中還包括一個groupBy(),他和Sql中的groupBy一樣都是分組,返回一個Map
例如:
//按學生年齡分組
Map<Integer,List<Student>> map= students.stream().
collect(Collectors.groupingBy(Student::getAge));
groupingBy可以接受3個參數,分別是
- 第一個參數:分組按照什麼分類
- 第二個參數:分組最後用什麼容器保存返回(當只有兩個參數是,此參數默認為
HashMap)
- 第三個參數:按照第一個參數分類后,對應的分類的結果如何收集
有時候單參數的groupingBy不滿足我們需求的時候,我們可以使用多個參數的groupingBy
例如:
//將學生以年齡分組,每組中只存學生的名字而不是對象
Map<Integer,List<String>> map = students.stream().
collect(Collectors.groupingBy(Student::getAge,Collectors.mapping(Student::getName,Collectors.toList())));
toList默認生成的是ArrayList,toSet默認生成的是HashSet,如果想要指定其他容器,可以如下操作:
students.stream().collect(Collectors.toCollection(TreeSet::new));
Collectors還包含一個toMap,利用這個API我們可以將List轉換為Map
Map<Integer,Student> map=students.stream().
collect(Collectors.toMap(Student::getAge,s->s));
值得注意的一點是,IntStream,LongStream,DoubleStream是沒有collect()方法的,因為對於基本數據類型,要進行裝箱,拆箱操作,SDK並沒有將它放入流中,對於基本數據類型流,我們只能將其toArray()
優雅的使用Stream
了解了Stream API,下面詳細介紹一下如果優雅的使用Steam
-
了解流的惰性操作
前面說到,流的中間操作是惰性的,如果一個流操作流程中只有中間操作,沒有終結操作,那麼這個流什麼都不會做,整個流程中會一直等到遇到終結操作操作才會真正的開始執行。
例如:
students.stream().peek(System.out::println);
這樣的流操作只有中間操作,沒有終結操作,那麼不管流裡面包含多少元素,他都不會執行任何操作。
-
明白流操作的順序的重要性
在Stream API中,還包括一類Short-circuiting,它能夠改變流中元素的數量,一般這類API如果是中間操作,最好寫在靠前位置:
考慮下面兩行代碼:
students.stream().sorted(Comparator.comparingInt(Student::getAge)).
peek(System.out::println).
limit(3).
collect(Collectors.toList());
students.stream().limit(3).
sorted(Comparator.comparingInt(Student::getAge)).
peek(System.out::println).
collect(Collectors.toList());
兩段代碼所使用的API都是相同的,但是由於順序不同,帶來的結果都非常不一樣的,
第一段代碼會先排序所有的元素,再依次打印一遍,最後獲取前三個最小的放入list中,
第二段代碼會先截取前3個元素,在對這三個元素排序,然後遍歷打印,最後放入list中。
-
明白Lambda的局限性
由於Java目前只能Pass-by-value,因此對於Lambda也和有匿名類一樣的final的局限性。
具體原因可以參考
因此我們無法再lambda表達式中修改外部元素的值。
同時,在Stream中,我們無法使用break提前返回。
-
合理編排Stream的代碼格式
由於可能在使用流式編程的時候會處理很多的業務邏輯,導致API非常長,此時最後使用換行將各個操作分離開來,使得代碼更加易讀。
例如:
students.stream().limit(3).
sorted(Comparator.comparingInt(Student::getAge)).
peek(System.out::println).
collect(Collectors.toList());
而不是:
students.stream().limit(3).sorted(Comparator.comparingInt(Student::getAge)).peek(System.out::println).collect(Collectors.toList());
同時由於Lambda表達式省略了參數類型,因此對於變量,盡量使用完成的名詞,比如student而不是s,增加代碼的可讀性。
盡量寫出敢在代碼註釋上留下你的名字的代碼!
總結
總之,Stream是Java 8 提供的簡化代碼的神器,合理使用它,能讓你的代碼更加優雅。
尊重勞動成功,轉載註明出處
參考鏈接:
《Effective Java》3th
如果覺得寫得不錯,歡迎關注微信公眾號:逸游Java ,每天不定時發布一些有關Java乾貨的文章,感謝關注
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開