一 Pod定義詳解
1.1 完整Pod定義文件
1 apiVersion: v1 #必選,版本號,例如v1,版本號必須可以用 kubectl api-versions 查詢到
2 kind: Pod #必選,Pod
3 metadata: #必選,元數據
4 name: string #必選,Pod名稱,需符合RFC 1035規範
5 namespace: string #必選,Pod所屬的命名空間,默認為"default"
6 labels: #自定義標籤
7 - name: string #自定義標籤名字
8 annotations: #自定義註釋列表
9 - name: string
10 spec: #必選,Pod中容器的詳細定義
11 containers: #必選,Pod中容器列表
12 - name: string #必選,容器名稱,需符合RFC 1035規範
13 image: string #必選,容器的鏡像名稱
14 imagePullPolicy: [ Always|Never|IfNotPresent ] #獲取鏡像的策略,Alawys表示每次都嘗試下載鏡像,IfnotPresent表示優先使用本地鏡像,否則下載鏡像,Nerver表示僅使用本地鏡像
15 command: [string] #容器的啟動命令列表,如不指定,使用打包時使用的啟動命令
16 args: [string] #容器的啟動命令參數列表
17 workingDir: string #容器的工作目錄
18 volumeMounts: #掛載到容器內部的存儲卷配置
19 - name: string #引用pod定義的共享存儲卷的名稱,需用volumes[]部分定義的的卷名
20 mountPath: string #存儲卷在容器內mount的絕對路徑,應少於512字符
21 readOnly: boolean #是否為只讀模式,默認為讀寫模式
22 ports: #需要暴露的端口庫號列表
23 - name: string #端口的名稱
24 containerPort: int #容器需要監聽的端口號
25 hostPort: int #容器所在主機需要監聽的端口號,默認與Container相同
26 protocol: string #端口協議,支持TCP和UDP,默認TCP
27 env: #容器運行前需設置的環境變量列表
28 - name: string #環境變量名稱
29 value: string #環境變量的值
30 resources: #資源限制和請求的設置
31 limits: #資源限制的設置
32 cpu: string #CPU的限制,單位為core數,將用於docker run --cpu-shares參數
33 memory: string #內存限制,單位可以為Mib/Gib,將用於docker run --memory參數
34 requests: #資源請求的設置
35 cpu: string #CPU請求,容器啟動的初始可用數量
36 memory: string #內存請求,容器啟動的初始可用數量
37 livenessProbe: #對Pod內各容器健康檢查的設置,當探測無響應幾次后將自動重啟該容器,檢查方法有exec、httpGet和tcpSocket,對一個容器只需設置其中一種方法即可
38 exec: #對Pod容器內檢查方式設置為exec方式
39 command: [string] #exec方式需要制定的命令或腳本
40 httpGet: #對Pod內個容器健康檢查方法設置為HttpGet,需要制定Path、port
41 path: string
42 port: number
43 host: string
44 scheme: string
45 HttpHeaders:
46 - name: string
47 value: string
48 tcpSocket: #對Pod內個容器健康檢查方式設置為tcpSocket方式
49 port: number
50 initialDelaySeconds: 0 #容器啟動完成后首次探測的時間,單位為秒
51 timeoutSeconds: 0 #對容器健康檢查探測等待響應的超時時間,單位秒,默認1秒
52 periodSeconds: 0 #對容器監控檢查的定期探測時間設置,單位秒,默認10秒一次
53 successThreshold: 0
54 failureThreshold: 0
55 securityContext:
56 privileged: false
57 restartPolicy: [Always | Never | OnFailure] #Pod的重啟策略,Always表示一旦不管以何種方式終止運行,kubelet都將重啟,OnFailure表示只有Pod以非0退出碼退出才重啟,Nerver表示不再重啟該Pod
58 nodeSelector: obeject #設置NodeSelector表示將該Pod調度到包含這個label的node上,以key:value的格式指定
59 imagePullSecrets: #Pull鏡像時使用的secret名稱,以key:secretkey格式指定
60 - name: string
61 hostNetwork: false #是否使用主機網絡模式,默認為false,如果設置為true,表示使用宿主機網絡
62 volumes: #在該pod上定義共享存儲卷列表
63 - name: string #共享存儲卷名稱 (volumes類型有很多種)
64 emptyDir: {} #類型為emtyDir的存儲卷,與Pod同生命周期的一個臨時目錄。為空值
65 hostPath: string #類型為hostPath的存儲卷,表示掛載Pod所在宿主機的目錄
66 path: string #Pod所在宿主機的目錄,將被用於同期中mount的目錄
67 secret: #類型為secret的存儲卷,掛載集群與定義的secre對象到容器內部
68 scretname: string
69 items:
70 - key: string
71 path: string
72 configMap: #類型為configMap的存儲卷,掛載預定義的configMap對象到容器內部
73 name: string
74 items:
75 - key: string
76 path: string
二 Pod的基本用法
2.1 創建Pod
Pod可以由1個或多個容器組合而成,通常對於緊耦合的兩個應用,應該組合成一個整體對外提供服務,則應該將這兩個打包為一個pod。
屬於一個Pod的多個容器應用之間相互訪問只需要通過localhost即可通信,這一組容器被綁定在一個環境中。
1 [root@k8smaster01 study]# vi frontend-localredis-pod.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: redis-php
6 label:
7 name: redis-php
8 spec:
9 containers:
10 - name: frontend
11 image: kubeguide/guestbook-php-frontend:localredis
12 ports:
13 - containersPort: 80
14 - name: redis-php
15 image: kubeguide/redis-master
16 ports:
17 - containersPort: 6379
18
19 [root@k8smaster01 study]# kubectl create -f frontend-localredis-pod.yaml
20
2.2 查看Pod
1 [root@k8smaster01 study]# kubectl get pods #READY為2/2,表示此Pod中運行了yaml定義的兩個容器
2 NAME READY STATUS RESTARTS AGE
3 redis-php 2/2 Running 0 7m45s
4 [root@k8smaster01 study]# kubectl describe pod redis-php #查看詳細信息
5
三 靜態Pod
3.1 靜態Pod概述
靜態pod是由kubelet進行管理的僅存在於特定Node的Pod上,他們不能通過API Server進行管理,無法與ReplicationController、Deployment或者DaemonSet進行關聯,並且kubelet無法對他們進行健康檢查。靜態Pod總是由kubelet進行創建,並且總是在kubelet所在的Node上運行。
創建靜態Pod有兩種方式:配置文件或者HTTP方式。
3.2 配置文件方式創建
1 [root@k8snode01 ~]# mkdir -p /etc/kubelet.d
2 [root@k8snode01 ~]# vi /etc/kubelet.d/static-web.yaml
3 apiVersion: v1
4 kind: Pod
5 metadata:
6 name: static-web
7 label:
8 name: static-web
9 spec:
10 containers:
11 - name: static-web
12 image: nginx
13 ports:
14 - name: web
15 containersPort: 80
16
17 [root@k8snode01 ~]# vi /etc/systemd/system/kubelet.service
18 ……
19 --config=/etc/kubelet.d/ \· #加入此參數
20 ……
21 [root@k8snode01 ~]# systemctl daemon-reload
22 [root@k8snode01 ~]# systemctl restart kubelet.service #重啟kubelet
23 [root@k8snode01 ~]# docker ps #查看創建的pod
提示:由於靜態pod不能通過API Server進行管理,因此在Master節點執行刪除操作後會變為Pending狀態,且無法刪除。刪除該pod只能在其運行的node上,將定義POD的yaml刪除。
3.3 HTTP方式
通過設置kubelet的啟動參數–mainfest-url,會定期從該URL下載Pod的定義文件,並以.yaml或.json文件的格式進行解析,從而創建Pod。
四 Pod容器共享Volume
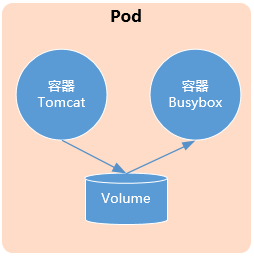
4.1 共享Volume
在同一個Pod中的多個容器能夠共享Pod級別的存儲就Volume。Volume可以被定義為各種類型,多個容器各自進行掛載操作,將一個Volume掛載為容器內部需要的目錄。
示例1:
Pod級別設置Volume “app-logs”,同時Pod包含兩個容器,Tomcat向該Volume寫日誌,busybox讀取日誌文件。
1 [root@k8smaster01 study]# vi pod-volume-applogs.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: volume-pod
6 spec:
7 containers:
8 - name: tomcat
9 image: tomcat
10 ports:
11 - containerPort: 8080
12 volumeMounts:
13 - name: app-logs
14 mountPath: /usr/local/tomcat/logs
15 - name: logreader
16 image: busybox
17 command: ["sh","-c","tail -f /logs/catalina*.log"]
18 volumeMounts:
19 - name: app-logs
20 mountPath: /logs
21 volumes:
22 - name: app-logs
23 emptyDir: {}
解釋:
Volume名:app-logs;
emptyDir:為Pod分配到Node的時候創建。無需指定宿主機的目錄文件,為Kubernetes自動分配的目錄。
1 [root@k8smaster01 study]# kubectl create -f pod-volume-applogs.yaml #創建
2 [root@k8smaster01 study]# kubectl get pods #查看
3 [root@k8smaster01 study]# kubectl logs volume-pod -c busybox #讀取log
1 [root@k8smaster01 study]# kubectl exec -it volume-pod -c tomcat -- ls /usr/local/tomcat/logs
2 catalina.2019-06-29.log localhost_access_log.2019-06-29.txt
3 host-manager.2019-06-29.log manager.2019-06-29.log
4 localhost.2019-06-29.log
5 [root@k8smaster01 study]# kubectl exec -it volume-pod -c tomcat -- tail /usr/local/tomcat/logs/catalina.2019-06-29.log
提示:通過tomcat容器可查看日誌,對比busybox通過共享Volume查看的日誌是否一致。
五 Pod配置管理
5.1 Pod配置概述
應用部署的一個最佳實踐是將應用所需的配置信息與程序進行分離,使程序更加靈活。將相應的應用打包為鏡像,可以通過環境變量或者外掛volume的方式在創建容器的時候進行配置注入,從而實現更好的復用。
Kubernetes提供一種統一的應用配置管理方案:ConfigMap。
5.2 ConfigMap概述
ConfigMap供容器使用的主要場景:
- 生成容器內部的環境變量;
- 設置容器的啟動命令的參數(需設置為環境變量);
- 以volume的形式掛載為容器內部的文件或者目錄。
ConfigMap以一個或多個key:value的形式定義。value可以是string也可以是一個文件內容,可以通過yaml配置文件或者通過kubectl create configmap 的方式創建configMap。
5.3 創建ConfigMap資源對象——yaml方式
1 [root@k8smaster01 study]# vi cm-appvars.yaml
2 apiVersion: v1
3 kind: ConfigMap
4 metadata:
5 name: cm-appvars
6 data:
7 apploglevel: info
8 appdatadir: /var/data
9
10 [root@k8smaster01 study]# kubectl create -f cm-appvars.yaml
11 configmap/cm-appvars created
12 [root@k8smaster01 study]# kubectl get configmaps
13 NAME DATA AGE
14 cm-appvars 2 8s
15 [root@k8smaster01 study]# kubectl describe configmaps cm-appvars
1 [root@k8smaster01 study]# kubectl get configmaps cm-appvars -o yaml
5.4 創建ConfigMap資源對象——命令行方式
語法1
1 # kubectl create configmap NAME --from-file=[key=]source --from-file=[key=]source
解釋:通過–from-file參數從文件中創建,可以指定key名稱,也可以制定多個key。
語法2
1 # kubectl create configmap NAME --from-file=config-files-dir
解釋:通過–from-file參數從目錄中創建,該目錄下的每個配置文件名都被設置為key,文件的內容被設置為value。
語法3
1 # kubectl create configmap NAME --from-literal=key1=value1 --from-literal=key2=value2
解釋:通過–from-literal參數從文本中創建,直接將指定的key#=value#創建為ConfigMap的內容。
5.5 Pod使用ConfigMap
容器應用使用ConfigMap有兩種方式:
- 通過環境變量獲取ConfigMap中的內容;
- 通過Volume掛載的方式將ConfigMap中的內容掛載為容器內容的文件或目錄。
1 [root@k8smaster01 study]# vi cm-test-pod.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: cm-test-pod
6 spec:
7 containers:
8 - name: cm-test
9 image: busybox
10 command: ["/bin/sh","-c","env|grep APP"] #容器里執行查看環境變量的命令
11 env:
12 - name: APPLOGLEVEL #定義容器環境變量名稱
13 valueFrom:
14 configMapKeyRef: #環境變量的值來自ConfigMap
15 name: cm-appvars #指定來自cm-appvars的ConfigMap
16 key: apploglevel #key為apploglevel
17 - name: APPDATADIR
18 valueFrom:
19 configMapKeyRef:
20 name: cm-appvars
21 key: appdatadir
22
23 [root@k8smaster01 study]# kubectl create -f cm-test-pod.yaml
24 [root@k8smaster01 study]# kubectl get pods
25 NAME READY STATUS RESTARTS AGE
26 cm-test-pod 0/1 Completed 2 24s
【掛載形式-待補充】
5.6 ConfigMap限制
- Configmap必須在pod創建之間創建;
- ConfigMap受到namespace的限制,只有同一個命名空間下才能引用;
- ConfigMap暫時無法配置配額;
- 靜態的pod無法使用ConfigMap;
- 在使用volumeMount掛載的時候,configMap基於items創建的文件會整體的將掛載數據卷的容器的目錄下的文件全部覆蓋。
六 Pod獲取自身信息
6.1 Downward API
pod擁有唯一的名字、IP地址,並且處於某個Namespace中。pod的容器內獲取pod的信息科通過Downward API實現。具體有以下兩種方式:
- 環境變量:用於單個變量,可以將pod信息和container信息注入容器內部;
- volume掛載:將數組類信息生成為文件,掛載至容器內部。
舉例1:通過Downward API將Pod的IP、名稱和所在的Namespace注入容器的環境變量。
1 [root@k8smaster01 study]# vi dapi-test-pod.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: dapi-test-pod
6 spec:
7 containers:
8 - name: test-container
9 image: busybox
10 command: [ "/bin/sh", "-c", "env" ]
11 env:
12 - name: MY_POD_NAME
13 valueFrom:
14 fieldRef:
15 fieldPath: metadata.name
16 - name: MY_POD_NAMESPACE
17 valueFrom:
18 fieldRef:
19 fieldPath: metadata.namespace
20 - name: MY_POD_IP
21 valueFrom:
22 fieldRef:
23 fieldPath: status.podIP
24 restartPolicy: Never
提示:Downward API提供如下變量:
metadata.name:Pod的名稱,當Pod通過RC生成時,其名稱是RC隨機產生的唯一名稱;
status.podIP:Pod的IP地址,POd的IP屬於狀態數據,而非元數據;
metadata.namespace:Pod所在的namespace。
1 [root@k8smaster01 study]# kubectl create -f dapi-test-pod.yaml
2 [root@k8smaster01 study]# kubectl logs dapi-test-pod | grep MY_POD
3 MY_POD_NAMESPACE=default
4 MY_POD_IP=172.30.240.4
5 MY_POD_NAME=dapi-test-pod
6
舉例2:通過Downward API將Container的自願請求和限制信息注入容器的環境變量。
1 [root@k8smaster01 study]# vi dapi-test-pod-container-vars.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: dapi-test-pod-container-vars
6 spec:
7 containers:
8 - name: test-container
9 image: busybox
10 imagePullPolicy: Never
11 command: [ "/bin/sh", "-c" ]
12 args:
13 - while true; do
14 echo -en '\n';
15 printenv MY_CPU_REQUEST MY_CPU_LIMIT;
16 printenv MY_MEM_REQUEST MY_MEM_LIMIT;
17 sleep 3600;
18 done;
19 resources:
20 requests:
21 memory: "32Mi"
22 cpu: "125m"
23 limits:
24 memory: "64Mi"
25 cpu: "250m"
26 env:
27 - name: MY_CPU_REQUEST
28 valueFrom:
29 resourceFieldRef:
30 containerName: test-container
31 resource: requests.cpu
32 - name: MY_CPU_LIMIT
33 valueFrom:
34 resourceFieldRef:
35 containerName: test-container
36 resource: limits.cpu
37 - name: MY_MEM_REQUEST
38 valueFrom:
39 resourceFieldRef:
40 containerName: test-container
41 resource: requests.memory
42 - name: MY_MEM_LIMIT
43 valueFrom:
44 resourceFieldRef:
45 containerName: test-container
46 resource: limits.memory
47 restartPolicy: Never
提示:Downward API提供如下變量:
requests.cpu:容器的CPU請求值;
limits.cpu:容器的CPU限制值;
requests.memory:容器的內存請求值;
limits.memory:容器的內存限制值。
1 [root@k8smaster01 study]# kubectl create -f dapi-test-pod-container-vars.yaml
2 [root@k8smaster01 study]# kubectl logs dapi-test-pod-container-vars
3 1
4 1
5 33554432
6 67108864
舉例3:通過Downward API將Pod的Label、Annotation列表通過Volume掛載為容器內的一個文件。
1 [root@k8smaster01 study]# vi dapi-test-pod-volume.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: dapi-test-pod-volume
6 labels:
7 zone: us-est-coast
8 cluster: test-cluster1
9 rack: rack-22
10 annotations:
11 build: two
12 builder: john-doe
13 spec:
14 containers:
15 - name: test-container
16 image: busybox
17 imagePullPolicy: Never
18 command: [ "/bin/sh", "-c" ]
19 args:
20 - while true; do
21 if [[ -e /etc/labels ]]; then
22 echo -en '\n\n'; cat /etc/labels; fi;
23 if [[ -e /etc/annotations ]]; then
24 echo -en '\n\n'; cat /etc/annotations; fi;
25 sleep 3600;
26 done;
27 volumeMounts:
28 - name: podinfo
29 mountPath: /etc
30 readOnly: false
31 volumes:
32 - name: podinfo
33 downwardAPI:
34 items:
35 - path: "labels"
36 fieldRef:
37 fieldPath: metadata.labels
38 - path: "annotations"
39 fieldRef:
40 fieldPath: metadata.annotations
注意:Volume中的ddownwardAPI的items語法,將會以path的名稱生成文件。如上所示,會在容器內生產/etc/labels和/etc/annotations兩個文件,分別包含metadata.labels和metadata.annotations的全部Label。
1 [root@k8smaster01 study]# kubectl create -f dapi-test-pod-volume.yaml
2 [root@k8smaster01 study]# kubectl logs dapi-test-pod-volume
3
提示:DownwardAPI意義:
在某些集群中,集群中的每個節點需要將自身的標識(ID)及進程綁定的IP地址等信息事先寫入配置文件中,進程啟動時讀取此類信息,然後發布到某個類似註冊服務中心。此時可通過DowanwardAPI,將一個預啟動腳本或Init Container,通過環境變量或文件方式獲取Pod自身的信息,然後寫入主程序配置文件中,最後啟動主程序。本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步”網站設計“幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※試算大陸海運運費!