動手造輪子:實現簡單的 EventQueue
Intro
最近項目里有遇到一些併發的問題,想實現一個隊列來將併發的請求一個一個串行處理,可以理解為使用消息隊列處理併發問題,之前實現過一個簡單的 EventBus,於是想在 EventBus 的基礎上改造一下,加一個隊列,改造成類似消息隊列的處理模式。消息的處理(Consumer)直接使用 .netcore 里的 IHostedService 來實現了一個簡單的後台任務處理。
初步設計
- Event 抽象的事件
- EventHandler 處理 Event 的方法
- EventStore 保存訂閱 Event 的 EventHandler
- EventQueue 保存 Event 的隊列
- EventPublisher 發布 Event
- EventConsumer 處理 Event 隊列里的 Event
- EventSubscriptionManager 管理訂閱 Event 的 EventHandler
實現代碼
EventBase 定義了基本事件信息,事件發生時間以及事件的id:
public abstract class EventBase
{
[JsonProperty]
public DateTimeOffset EventAt { get; private set; }
[JsonProperty]
public string EventId { get; private set; }
protected EventBase()
{
this.EventId = GuidIdGenerator.Instance.NewId();
this.EventAt = DateTimeOffset.UtcNow;
}
[JsonConstructor]
public EventBase(string eventId, DateTimeOffset eventAt)
{
this.EventId = eventId;
this.EventAt = eventAt;
}
}EventHandler 定義:
public interface IEventHandler
{
Task Handle(IEventBase @event);
}
public interface IEventHandler<in TEvent> : IEventHandler where TEvent : IEventBase
{
Task Handle(TEvent @event);
}
public class EventHandlerBase<TEvent> : IEventHandler<TEvent> where TEvent : EventBase
{
public virtual Task Handle(TEvent @event)
{
return Task.CompletedTask;
}
public Task Handle(IEventBase @event)
{
return Handle(@event as TEvent);
}
}EventStore:
public class EventStore
{
private readonly Dictionary<Type, Type> _eventHandlers = new Dictionary<Type, Type>();
public void Add<TEvent, TEventHandler>() where TEventHandler : IEventHandler<TEvent> where TEvent : EventBase
{
_eventHandlers.Add(typeof(TEvent), typeof(TEventHandler));
}
public object GetEventHandler(Type eventType, IServiceProvider serviceProvider)
{
if (eventType == null || !_eventHandlers.TryGetValue(eventType, out var handlerType) || handlerType == null)
{
return null;
}
return serviceProvider.GetService(handlerType);
}
public object GetEventHandler(EventBase eventBase, IServiceProvider serviceProvider) =>
GetEventHandler(eventBase.GetType(), serviceProvider);
public object GetEventHandler<TEvent>(IServiceProvider serviceProvider) where TEvent : EventBase =>
GetEventHandler(typeof(TEvent), serviceProvider);
}EventQueue 定義:
public class EventQueue
{
private readonly ConcurrentDictionary<string, ConcurrentQueue<EventBase>> _eventQueues =
new ConcurrentDictionary<string, ConcurrentQueue<EventBase>>();
public ICollection<string> Queues => _eventQueues.Keys;
public void Enqueue<TEvent>(string queueName, TEvent @event) where TEvent : EventBase
{
var queue = _eventQueues.GetOrAdd(queueName, q => new ConcurrentQueue<EventBase>());
queue.Enqueue(@event);
}
public bool TryDequeue(string queueName, out EventBase @event)
{
var queue = _eventQueues.GetOrAdd(queueName, q => new ConcurrentQueue<EventBase>());
return queue.TryDequeue(out @event);
}
public bool TryRemoveQueue(string queueName)
{
return _eventQueues.TryRemove(queueName, out _);
}
public bool ContainsQueue(string queueName) => _eventQueues.ContainsKey(queueName);
public ConcurrentQueue<EventBase> this[string queueName] => _eventQueues[queueName];
}EventPublisher:
public interface IEventPublisher
{
Task Publish<TEvent>(string queueName, TEvent @event)
where TEvent : EventBase;
}
public class EventPublisher : IEventPublisher
{
private readonly EventQueue _eventQueue;
public EventPublisher(EventQueue eventQueue)
{
_eventQueue = eventQueue;
}
public Task Publish<TEvent>(string queueName, TEvent @event)
where TEvent : EventBase
{
_eventQueue.Enqueue(queueName, @event);
return Task.CompletedTask;
}
}EventSubscriptionManager:
public interface IEventSubscriptionManager
{
void Subscribe<TEvent, TEventHandler>()
where TEvent : EventBase
where TEventHandler : IEventHandler<TEvent>;
}
public class EventSubscriptionManager : IEventSubscriptionManager
{
private readonly EventStore _eventStore;
public EventSubscriptionManager(EventStore eventStore)
{
_eventStore = eventStore;
}
public void Subscribe<TEvent, TEventHandler>()
where TEvent : EventBase
where TEventHandler : IEventHandler<TEvent>
{
_eventStore.Add<TEvent, TEventHandler>();
}
}
EventConsumer:
public class EventConsumer : BackgroundService
{
private readonly EventQueue _eventQueue;
private readonly EventStore _eventStore;
private readonly int maxSemaphoreCount = 256;
private readonly IServiceProvider _serviceProvider;
private readonly ILogger _logger;
public EventConsumer(EventQueue eventQueue, EventStore eventStore, IConfiguration configuration, ILogger<EventConsumer> logger, IServiceProvider serviceProvider)
{
_eventQueue = eventQueue;
_eventStore = eventStore;
_logger = logger;
_serviceProvider = serviceProvider;
}
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
using (var semaphore = new SemaphoreSlim(Environment.ProcessorCount, maxSemaphoreCount))
{
while (!stoppingToken.IsCancellationRequested)
{
var queues = _eventQueue.Queues;
if (queues.Count > 0)
{
await Task.WhenAll(
queues
.Select(async queueName =>
{
if (!_eventQueue.ContainsQueue(queueName))
{
return;
}
try
{
await semaphore.WaitAsync(stoppingToken);
//
if (_eventQueue.TryDequeue(queueName, out var @event))
{
var eventHandler = _eventStore.GetEventHandler(@event, _serviceProvider);
if (eventHandler is IEventHandler handler)
{
_logger.LogInformation(
"handler {handlerType} begin to handle event {eventType}, eventId: {eventId}, eventInfo: {eventInfo}",
eventHandler.GetType().FullName, @event.GetType().FullName,
@event.EventId, JsonConvert.SerializeObject(@event));
try
{
await handler.Handle(@event);
}
catch (Exception e)
{
_logger.LogError(e, "event {eventId} handled exception", @event.EventId);
}
finally
{
_logger.LogInformation("event {eventId} handled", @event.EventId);
}
}
else
{
_logger.LogWarning(
"no event handler registered for event {eventType}, eventId: {eventId}, eventInfo: {eventInfo}",
@event.GetType().FullName, @event.EventId,
JsonConvert.SerializeObject(@event));
}
}
}
catch (Exception ex)
{
_logger.LogError(ex, "error running EventConsumer");
}
finally
{
semaphore.Release();
}
})
);
}
await Task.Delay(50, stoppingToken);
}
}
}
}為了方便使用定義了一個 Event 擴展方法:
public static IServiceCollection AddEvent(this IServiceCollection services)
{
services.TryAddSingleton<EventStore>();
services.TryAddSingleton<EventQueue>();
services.TryAddSingleton<IEventPublisher, EventPublisher>();
services.TryAddSingleton<IEventSubscriptionManager, EventSubscriptionManager>();
services.AddSingleton<IHostedService, EventConsumer>();
return services;
}使用示例
定義 PageViewEvent 記錄請求信息:
public class PageViewEvent : EventBase
{
public string Path { get; set; }
}這裏作為示例只記錄了請求的Path信息,實際使用可以增加更多需要記錄的信息
定義 PageViewEventHandler,處理 PageViewEvent
public class PageViewEventHandler : EventHandlerBase<PageViewEvent>
{
private readonly ILogger _logger;
public PageViewEventHandler(ILogger<PageViewEventHandler> logger)
{
_logger = logger;
}
public override Task Handle(PageViewEvent @event)
{
_logger.LogInformation($"handle pageViewEvent: {JsonConvert.SerializeObject(@event)}");
return Task.CompletedTask;
}
}這個 handler 里什麼都沒做只是輸出一個日誌
這個示例項目定義了一個記錄請求路徑的事件以及一個發布請求記錄事件的中間件
// 發布 Event 的中間件
app.Use(async (context, next) =>
{
var eventPublisher = context.RequestServices.GetRequiredService<IEventPublisher>();
await eventPublisher.Publish("pageView", new PageViewEvent() { Path = context.Request.Path.Value });
await next();
});Startup 配置:
public void ConfigureServices(IServiceCollection services)
{
// ...
services.AddEvent();
services.AddSingleton<PageViewEventHandler>();// 註冊 Handler
}
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
public void Configure(IApplicationBuilder app, IHostingEnvironment env, IEventSubscriptionManager eventSubscriptionManager)
{
eventSubscriptionManager.Subscribe<PageViewEvent, PageViewEventHandler>();
app.Use(async (context, next) =>
{
var eventPublisher = context.RequestServices.GetRequiredService<IEventPublisher>();
await eventPublisher.Publish("pageView", new PageViewEvent() { Path = context.Request.Path.Value });
await next();
});
// ...
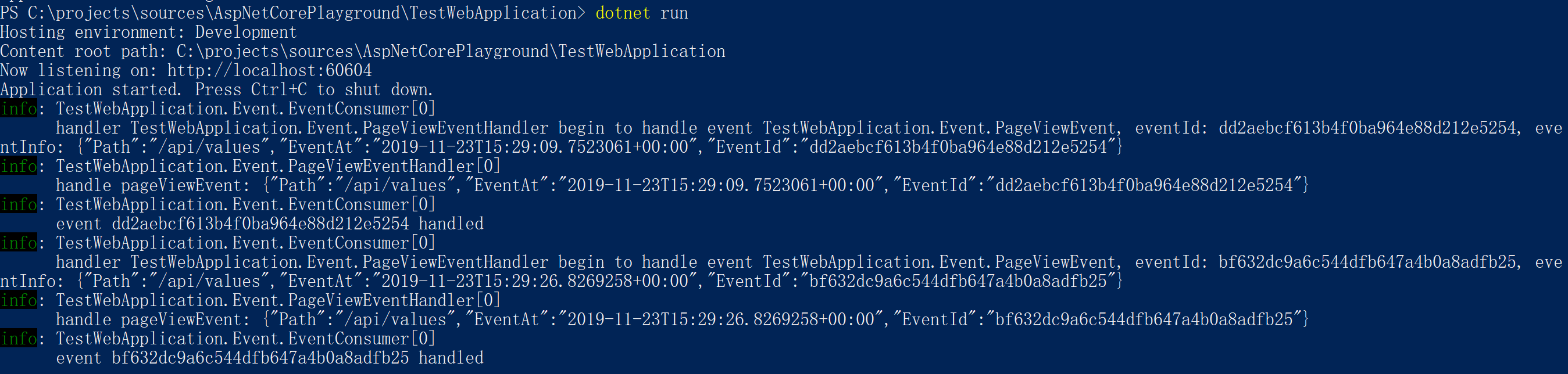
}使用效果:
More
注:只是一個初步設計,基本可以實現功能,還是有些不足,實際應用的話還有一些要考慮的事情
Consumer消息邏輯,現在的實現有些問題,我們的應用場景目前比較簡單還可以滿足,如果事件比較多就會而且每個事件可能處理需要的時間長短不一樣,會導致在一個批次中執行的Event中已經完成的事件要等待其他還沒完成的事件完成之後才能繼續取下一個事件,理想的消費模式應該是各個隊列相互獨立,在同一個隊列中保持順序消費即可- 上面示例的
EventStore的實現只是簡單的實現了一個事件一個Handler的處理情況,實際業務場景中很可能會有一個事件需要多個Handler的情況 - 這個實現是基於內存的,如果要在分佈式場景下使用就不適用了,需要自己實現一下基於redis或者數據庫的以滿足分佈式的需求
- and more…
上面所有的代碼可以在 Github 上獲取,示例項目 Github 地址:
Reference
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整