原文鏈接:https://fuckcloudnative.io/posts/monitoring-calico-with-prometheus-operator/
Calico 中最核心的組件就是 Felix,它負責設置路由表和 ACL 規則等,以便為該主機上的 endpoints 資源正常運行提供所需的網絡連接。同時它還負責提供有關網絡健康狀況的數據(例如,報告配置其主機時發生的錯誤和問題),這些數據會被寫入 etcd,以使其對網絡中的其他組件和操作人員可見。
由此可見,對於我們的監控來說,監控 Calico 的核心便是監控 Felix,Felix 就相當於 Calico 的大腦。本文將學習如何使用 Prometheus-Operator 來監控 Calico。
本文不會涉及到
Calico和Prometheus-Operator的部署細節,如果不知道如何部署,請查閱官方文檔和相關博客。
1. 配置 Calico 以啟用指標
默認情況下 Felix 的指標是被禁用的,必須通過命令行管理工具 calicoctl 手動更改 Felix 配置才能開啟,需要提前配置好命令行管理工具。
本文使用的 Calico 版本是 v3.15.0,其他版本類似。先下載管理工具:
$ wget https://github.com/projectcalico/calicoctl/releases/download/v3.15.0/calicoctl -O /usr/local/bin/calicoctl
$ chmod +x /usr/local/bin/calicoctl
接下來需要設置 calicoctl 配置文件(默認是 /etc/calico/calicoctl.cfg)。如果你的 Calico 後端存儲使用的是 Kubernetes API,那麼配置文件內容如下:
apiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
datastoreType: "kubernetes"
kubeconfig: "/root/.kube/config"
如果 Calico 後端存儲使用的是 etcd,那麼配置文件內容如下:
apiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
datastoreType: "etcdv3"
etcdEndpoints: https://192.168.57.51:2379,https://192.168.57.52:2379,https://192.168.57.53:2379
etcdKeyFile: /opt/kubernetes/ssl/server-key.pem
etcdCertFile: /opt/kubernetes/ssl/server.pem
etcdCACertFile: /opt/kubernetes/ssl/ca.pem
你需要將其中的證書路徑換成你的 etcd 證書路徑。
配置好了 calicoctl 之後就可以查看或修改 Calico 的配置了,先來看一下默認的 Felix 配置:
$ calicoctl get felixConfiguration default -o yaml
apiVersion: projectcalico.org/v3
kind: FelixConfiguration
metadata:
creationTimestamp: "2020-06-25T14:37:28Z"
name: default
resourceVersion: "269031"
uid: 52146c95-ff97-40a9-9ba7-7c3b4dd3ba57
spec:
bpfLogLevel: ""
ipipEnabled: true
logSeverityScreen: Info
reportingInterval: 0s
可以看到默認的配置中沒有啟用指標,需要手動修改配置,命令如下:
$ calicoctl patch felixConfiguration default --patch '{"spec":{"prometheusMetricsEnabled": true}}'
Felix 暴露指標的端口是 9091,可通過檢查監聽端口來驗證是否開啟指標:
$ ss -tulnp|grep 9091
tcp LISTEN 0 4096 [::]:9091 [::]:* users:(("calico-node",pid=13761,fd=9))
$ curl -s http://localhost:9091/metrics
# HELP felix_active_local_endpoints Number of active endpoints on this host.
# TYPE felix_active_local_endpoints gauge
felix_active_local_endpoints 1
# HELP felix_active_local_policies Number of active policies on this host.
# TYPE felix_active_local_policies gauge
felix_active_local_policies 0
# HELP felix_active_local_selectors Number of active selectors on this host.
# TYPE felix_active_local_selectors gauge
felix_active_local_selectors 0
...
2. Prometheus 採集 Felix 指標
啟用了 Felix 的指標后,就可以通過 Prometheus-Operator 來採集指標數據了。Prometheus-Operator 在部署時會創建 Prometheus、PodMonitor、ServiceMonitor、AlertManager 和 PrometheusRule 這 5 個 CRD 資源對象,然後會一直監控並維持這 5 個資源對象的狀態。其中 Prometheus 這個資源對象就是對 Prometheus Server 的抽象。而 PodMonitor 和 ServiceMonitor 就是 exporter 的各種抽象,是用來提供專門提供指標數據接口的工具,Prometheus 就是通過 PodMonitor 和 ServiceMonitor 提供的指標數據接口去 pull 數據的。
ServiceMonitor 要求被監控的服務必須有對應的 Service,而 PodMonitor 則不需要,本文選擇使用 PodMonitor 來採集 Felix 的指標。
PodMonitor 雖然不需要應用創建相應的 Service,但必須在 Pod 中指定指標的端口和名稱,因此需要先修改 DaemonSet calico-node 的配置,指定端口和名稱。先用以下命令打開 DaemonSet calico-node 的配置:
$ kubectl -n kube-system edit ds calico-node
然後在線修改,在 spec.template.sepc.containers 中加入以下內容:
ports:
- containerPort: 9091
name: http-metrics
protocol: TCP
創建 Pod 對應的 PodMonitor:
# prometheus-podMonitorCalico.yaml
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
labels:
k8s-app: calico-node
name: felix
namespace: monitoring
spec:
podMetricsEndpoints:
- interval: 15s
path: /metrics
port: http-metrics
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: calico-node
$ kubectl apply -f prometheus-podMonitorCalico.yaml
有幾個參數需要注意:
-
PodMonitor 的 name 最終會反應到 Prometheus 的配置中,作為
job_name。 -
podMetricsEndpoints.port需要和被監控的 Pod 中的ports.name相同,此處為http-metrics。 -
namespaceSelector.matchNames需要和被監控的 Pod 所在的 namespace 相同,此處為kube-system。 -
selector.matchLabels的標籤必須和被監控的 Pod 中能唯一標明身份的標籤對應。
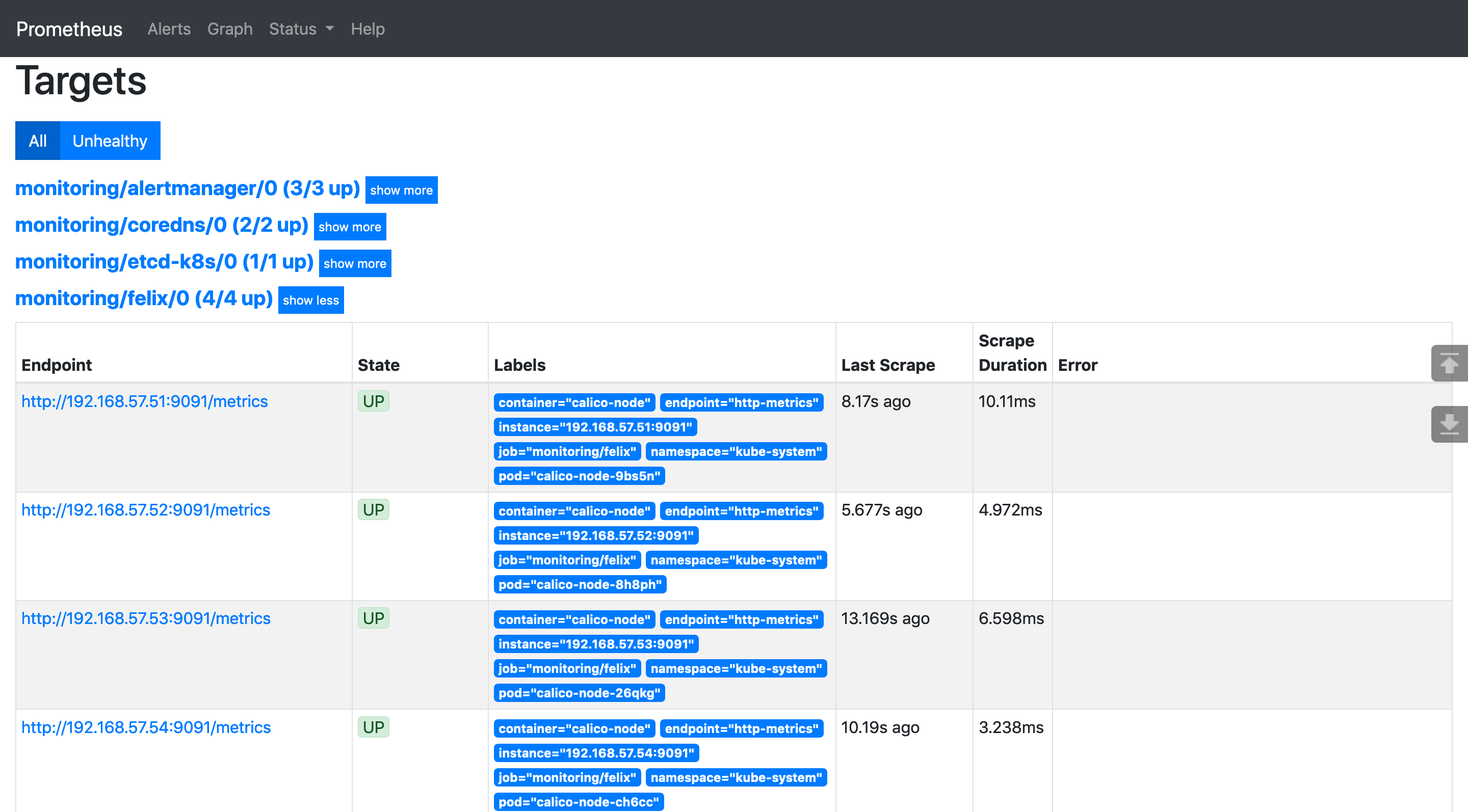
最終 Prometheus-Operator 會根據 PodMonitor 來修改 Prometheus 的配置文件,以實現對相關的 Pod 進行監控。可以打開 Prometheus 的 UI 查看監控目標:
注意 Labels 中有 pod="calico-node-xxx",表明監控的是 Pod。
3. 可視化監控指標
採集完指標之後,就可以通過 Grafana 的儀錶盤來展示監控指標了。Prometheus-Operator 中部署的 Grafana 無法實時修改儀錶盤的配置(必須提前將儀錶盤的 json 文件掛載到 Grafana Pod 中),而且也不是最新版(7.0 以上版本),所以我選擇刪除 Prometheus-Operator 自帶的 Grafana,自行部署 helm 倉庫中的 Grafana。先進入 kube-prometheus 項目的 manifests 目錄,然後將 Grafana 相關的部署清單都移到同一個目錄下,再刪除 Grafana:
$ cd kube-prometheus/manifests
$ mkdir grafana
$ mv grafana-* grafana/
$ kubectl delete -f grafana/
然後通過 helm 部署最新的 Grafana:
$ helm install grafana stable/grafana -n monitoring
訪問 Grafana 的密碼保存在 Secret 中,可以通過以下命令查看:
$ kubectl -n monitoring get secret grafana -o yaml
apiVersion: v1
data:
admin-password: MnpoV3VaMGd1b3R3TDY5d3JwOXlIak4yZ3B2cTU1RFNKcVY0RWZsUw==
admin-user: YWRtaW4=
ldap-toml: ""
kind: Secret
metadata:
...
對密碼進行解密:
$ echo -n "MnpoV3VaMGd1b3R3TDY5d3JwOXlIak4yZ3B2cTU1RFNKcVY0RWZsUw=="|base64 -d
解密出來的信息就是訪問密碼。用戶名是 admin。通過用戶名和密碼登錄 Grafana 的 UI:
添加 Prometheus-Operator 的數據源:
Calico 官方沒有單獨 dashboard json,而是將其放到了 ConfigMap 中,我們需要從中提取需要的 json,提取出 felix-dashboard.json 的內容,然後將其中的 datasource 值替換為 prometheus。你可以用 sed 替換,也可以用編輯器,大多數編輯器都有全局替換的功能。如果你實在不知道如何提取,可以使用我提取好的 json:
修改完了之後,將 json 內容導入到 Grafana:
最後得到的 Felix 儀錶盤如下圖所示:
如果你對我截圖中 Grafana 的主題配色很感興趣,可以參考這篇文章:Grafana 自定義主題。
Kubernetes 1.18.2 1.17.5 1.16.9 1.15.12離線安裝包發布地址http://store.lameleg.com ,歡迎體驗。 使用了最新的sealos v3.3.6版本。 作了主機名解析配置優化,lvscare 掛載/lib/module解決開機啟動ipvs加載問題, 修復lvscare社區netlink與3.10內核不兼容問題,sealos生成百年證書等特性。更多特性 https://github.com/fanux/sealos 。歡迎掃描下方的二維碼加入釘釘群 ,釘釘群已經集成sealos的機器人實時可以看到sealos的動態。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?