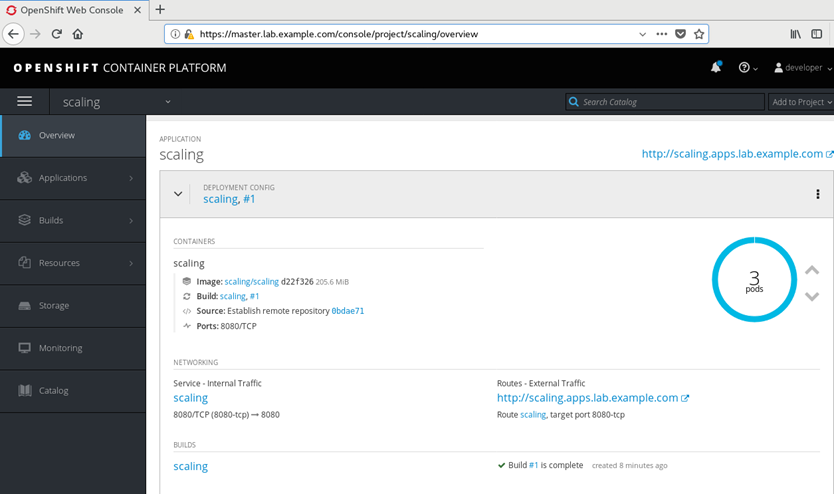
一 REPLICATION CONTROLLERS
1.1 RC概述
RC確保pod指定數量的副本一直運行。如果pod被殺死或被管理員顯式刪除,複製控制器將自動部署相應的pod。類似地,如果運行的pod數量超過所需的數量,它會根據需要刪除pod,以匹配指定的副本計數。
RC的定義主要包括:
- 所需的副本數量
- 用於創建複製pod的pod定義
- 用於標識後續管理操作的selector
selector是一組label,RC管理的所有pod都必須匹配這些標籤。RC實例化的pod定義中必須包含相同的標籤集。RC使用這個selector來確定已經運行了多少pod實例,以便根據需要進行調整。
提示:不執行自動縮放,因為它不跟蹤負載或流量。
儘管Kubernetes通常直接管理RC,但OpenShift推薦的方法是管理根據需要創建或更改RC的DC。
1.2 從DC創建RC
在OpenShift中創建應用程序的最常見方法是使用oc new-app命令或web控制台。以這種方式創建的應用程序使用DeploymentConfig資源在運行時創建RC來創建應用程序pod。DeploymentConfig資源定義定義了要創建的pod的副本的數量,以及要創建的pod的模板。
注意:不要將DeploymentConfig或ReplicationController資源中的template屬性誤認為OpenShift模板資源類型,OpenShift模板資源用於基於一些常用的語言運行時和框架構建應用程序。
1.3 pod副本數控制
DeploymentConfig或ReplicationController資源中的副本數量可以使用oc scale命令動態更改。
$ oc get dc
NAME REVISION DESIRED CURRENT TRIGGERED BY
myapp 1 3 3 config,image(scaling:latest)
$ oc scale –replicas=5 dc myapp
DeploymentConfig資源將更改信息傳遞至ReplicationController,該控制器通過創建新的pod(副本)或刪除現有的pod來響應更改。
雖然可以直接操作ReplicationController資源,但推薦的做法是操作DeploymentConfig資源。在觸發部署時,直接對ReplicationController資源所做的更改可能會丟失,例如,使用容器image的新版本重新創建pod。
1.4 自動伸縮pod
OpenShift可以通過HorizontalPodAutoscaler資源類型根據應用程序pod上的當前負載自動調整部署配置。
HorizontalPodAutoscaler (HPA)資源使用OpenShift metrics子系統收集的性能指標,即如果沒有度量子系統(模塊),更確切地說是Heapster組件,自動縮放是不可能的。
創建HorizontalPodAutoscaler資源的推薦方法是使用oc autoscale命令,例如:
$ oc autoscale dc/myapp –min 1 –max 10 –cpu-percent=80
該命令創建一個HorizontalPodAutoscaler資源,該資源更改myapp部署配置上的副本數量,以將其pod的CPU使用量控制在請求的總CPU使用量的80%以下。
oc autoscale命令使用DC的名稱作為參數(在前面的示例中是myapp)創建一個HorizontalPodAutoscaler資源。
HorizontalPodAutoscaler資源的最大值和最小值用於容納突發負載,並避免重載OpenShift集群。如果應用程序上的負載變化太快,建議保留一些備用的pod來處理突然出現的用戶請求。相反,過多的pod會耗盡所有集群容量,並影響共享相同OpenShift集群的其他應用程序。
要獲取當前項目中關於HorizontalPodAutoscaler資源的信息,可使用oc get和oc describe命令。例如
$ oc get hpa/frontend
$ oc describe hpa/frontend
注意:HorizontalPodAutoscaler資源只適用於為引用性能指標定義資源請求的pod。
oc new-app命令創建的大多數pod沒有定義任何資源請求。因此,使用OpenShift autoscaler可能需要為應用程序創建定製的YAML或JSON資源文件,或者向項目添加資源範圍資源。
二 擴展程序實驗
2.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
2.2 創建應用
1 [student@workstation ~]$ oc login -u developer -p redhat https://master.lab.example.com
2 [student@workstation ~]$ oc new-project scaling
3 [student@workstation ~]$ oc new-app -o yaml -i php:7.0 \
4 http://registry.lab.example.com/scaling > ~/scaling.yml #將部署的yaml導出至本地
5 [student@workstation ~]$ vi ~/scaling.yml
6 ……
7 spec:
8 replicas: 3
9 selector:
10 app: scaling
11 deploymentconfig: scaling #修改副本數
12 ……
13 [student@workstation ~]$ oc create -f ~/scaling.yml #以修改副本數后的yaml部署應用
2.3 監視部署
1 [student@workstation ~]$ watch -n 3 oc get builds
2 Every 3.0s: oc get builds Mon Jul 22 11:12:02 2019
3
4 NAME TYPE FROM STATUS STARTED DURATION
5 scaling-1 Source Git@0bdae71 Complete About a minute ago 1m0s
6 [student@workstation ~]$ oc get pods
7 NAME READY STATUS RESTARTS AGE
8 scaling-1-build 0/1 Completed 0 2m
9 scaling-1-ft249 1/1 Running 0 1m
10 scaling-1-gjvkp 1/1 Running 0 1m
11 scaling-1-mtrxr 1/1 Running 0 1m
2.4 暴露服務
1 [student@workstation ~]$ oc expose service scaling \
2 --hostname=scaling.apps.lab.example.com
2.5 web查看相關信息
瀏覽器訪問https://master.lab.example.com,使用developer用戶和redhat密碼登陸。選擇scaling項目。
2.6 測試負載均衡
1 [student@workstation ~]$ for i in {1..5};do curl -s \http://scaling.apps.lab.example.com | grep IP;done #多次請求
2 <br/> Server IP: 10.128.0.17
3 <br/> Server IP: 10.129.0.35
4 <br/> Server IP: 10.129.0.36
5 <br/> Server IP: 10.128.0.17
6 <br/> Server IP: 10.129.0.35
提示:瀏覽器可能無法嚴格檢查均衡性,因為OpenShift route存在會話關聯性(也稱為粘性會話)。即來自同一個web瀏覽器的所有請求都將轉到同一個pod。
2.7 擴容應用
1 [student@workstation ~]$ oc describe dc scaling | grep Replicas
2 Replicas: 3
3 Replicas: 3 current / 3 desired
4 [student@workstation ~]$ oc scale --replicas=5 dc scaling
1 [student@workstation ~]$ oc get pods -o wide
2.8 測試負載均衡
1 [student@workstation ~]$ for i in {1..5};do curl -s \http://scaling.apps.lab.example.com | grep IP;done #多次請求
2 <br/> Server IP: 10.128.0.17
3 <br/> Server IP: 10.128.0.18
4 <br/> Server IP: 10.129.0.35
5 <br/> Server IP: 10.129.0.36
6 <br/> Server IP: 10.129.0.37
三 pod調度控制
3.1 pod調度算法
pod調度程序確定新pod在OpenShift集群中的節點上的位置。該調度算法被設計為可高度配置和適應不同集群。OCP 3.9附帶的默認配置通過使用node label、affinity rules,anti-affinity rules中的定義來支持zone和regions的調用。
在OCP以前的版本中,安裝程序master節點標記為污點標記,表示不允許在master上部署pod。在新版的OCP 3.9中,在安裝和升級過程中,master會自動標記為可調度的。使得可以通過deploy調度pod至maste節點。而不僅僅是作為master的組件運行。
默認節點selector是在安裝和升級期間默認設置的。它被設置為node-role.kubernetes.io/compute=true,除非使用osm_default_node_selector的Ansible變量覆蓋它。
在安裝和升級期間,不管osm_default_node_selector配置如何,都會對庫存文件中定義的主機執行以下自動標記。
compute節點配置non-master、non-dedicated的角色(默認情況下,具有region=infra標籤的節點),節點使用node-role.kubernetes.io/compute=true標記。
master節點被標記為node-role.kubernetes.io/master=true,從而分配master節點角色。
3.2 調度算法步驟
調度程序根據節點資源(如主機端口)的可用性篩選正在運行的節點列表,然後進一步根據節點selector和來自pod的資源請求篩選。最終的縮小是可運行pod的候選node列表。
pod可以定義與集群節點中的標籤匹配的節點選擇器,標籤不匹配的節點視為不合格。
pod還可以為計算資源(如CPU、內存和存儲)定義資源請求,沒有足夠的空閑計算機資源的節點視為不合格。
候選節點列表使用多個優先級標準進行評估,這些標準加起來就是權重,權重值較高的節點更適合運行pod。
其中有affinity(親和規則)和anti-affinity(反親和規則),pod親和力較高的節點得分較高,而anti-affinity較高的節點權重低。
affinity的一個常見用法是:出於性能原因,將相關的pod安排得彼此親和。例如,需要保持彼此同步的pod使用相同的網絡棧。
anti-affinity的一個常見用法是:為了獲得高可用性,將相關的pod安排的盡量分散。例如,避免將所有pod從同一個應用程序調度到同一個節點。
根據權重對候選列表進行排序,並選擇權重最高的節點來承載pod。如果多個節點得分相同,則隨機選擇一個節點。
調度程序配置文件位於/etc/original/master/scheduler.json,其定義了一組predicates,用作過濾器或優先級函數。通過這種方式,可以將調度程序配置為支持不同的集群。
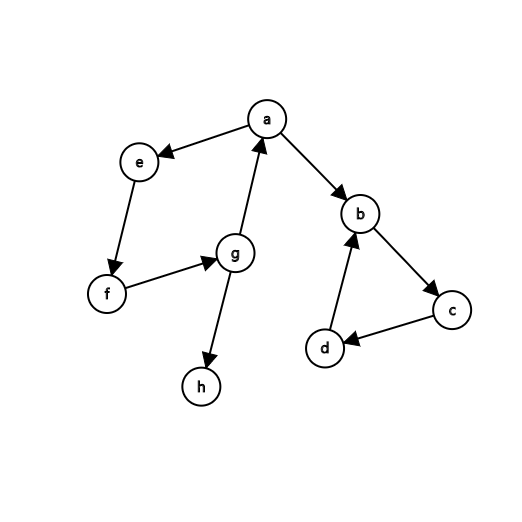
3.3 調度拓撲
對於大型數據中心,例如雲提供商,一個常見的拓撲結構是將主機組織成regions和zones:
region:是一個地理區域內的一組主機,這保證了它們之間的內網高速連接;
zone:也稱為可用區,是一組主機,它們可能一起失敗,因為它們共享公共的關鍵基礎設施組件,比如網絡、存儲或電源。
OpenShift pod調度器可支持根據region和zone標籤在集群內調度,如:
- 從相同的RC創建的或從相同的DC創建的pod副本調度至具有相同region標籤值的節點中運行。
- 副本Pod調位至具有不同zone標籤的節點中運行。
實例圖如下:
要實現上圖中的樣例拓撲,可以使用集群管理員通過以下命令oc label:
1 $ oc label node1 region=ZheJiang zone=Cloud1A --overwrite
2 $ oc label node node2 region=ZheJiang zone=Cloud1A --overwrite
3 $ oc label node node3 region=ZheJiang zone=Cloud2A --overwrite
4 $ oc label node node4 region=ZheJiang zone=Cloud2A --overwrite
5 $ oc label node node5 region=HuNan zone=Cloud1B --overwrite
6 $ oc label node node6 region=HuNan zone=Cloud1B --overwrite
7 $ oc label node node7 region=HuNan zone=Cloud2B --overwrite
8 $ oc label node node8 region=HuNan zone=Cloud2B --overwrite
提示:每個節點必須由其完全限定名(FQDN)標識,為了簡潔,如上命令使用了簡短的名稱。
對區域標籤的更改需要–overwrite選項,因為OCP 3.9高級安裝方法默認情況下使用region=infra標籤配置節點。
示例:要檢查分配給節點的標籤,可以使用oc get node命令和–show-labels選項。
$ oc get node node1.lab.example.com –show-labels
注意,一個節點可能有一些OpenShift分配的默認標籤,包含kubernetes.io後綴鍵值的標籤,此類標籤不應由集群管理員人為更改,因為它們由調度程序在內部使用。
集群管理員還可以使用-L選項來確定單個標籤的值。
示例:
1 $ oc get node node1.lab.example.com -L region
2 $ oc get node node1.lab.example.com -L region -L zone #支持oc get跟多個-L選項
3.4 UNSCHEDULABLE節點
有時候,集群管理員需要關閉節點進行維護,如節點可能需要硬件升級或內核安全更新。要在對OpenShift集群用戶影響最小的情況下關閉節點,管理員應該遵循兩個步驟。
將節點標記為不可調度,從而防止調度程序向節點分配新的pod。
1 $ oc adm manage-node --schedulable=false node2.lab.example.com
Drain節點,這將銷毀在pod中運行的所有pod,並假設這些pod將通過DC在其他可用節點中會重新創建。
1 $ oc adm drain node2.lab.example.com
維護操作完成后,使用oc adm management -node命令將節點標記為可調度的。
1 $ oc adm manage-node --schedulable=true node2.lab.example.com
3.5 控制pod位置
有些應用程序可能需要在一組指定的node上運行。例如,某些節點為某些類型的工作負載提供硬件加速,或者集群管理員不希望將生產應用程序與開發應用程序混合使用。此類需求,都可以使用節點標籤和節點選擇器來實現。
node selector是pod定義的一部分,但建議更改dc,而不是pod級別的定義。要添加節點選擇器,可使用oc edit命令或oc patch命令更改pod定義。
示例:配置myapp的dc,使其pods只在擁有env=qa標籤的節點上運行。
1 $ oc patch dc myapp --patch '{"spec":{"template":{"nodeSelector":{"env":"qa"}}}}'
此更改將觸發一個新的部署,並根據新的節點選擇器調度新的pod。
如果集群管理員不希望讓開發人員控制他們pod的節點選擇器,那麼應該在項目資源中配置一個默認的節點選擇器。
3.5 管理默認項目
生產環境一個常見實踐是指定一組節點來運行OCP的系統基礎Pod,比如route和內部倉庫。這些pod在默認項目中定義。
通常可通過以下兩個步驟實現:
- 使用region=infra標籤標記專用節點;
- 為缺省名稱空間配置缺省節點選擇器。
要配置項目的默認節點選擇器,可使用openshift.io/node-selector鍵值向名稱空間資源添加註釋。可以使用oc edit或oc annotate命令。
1 $ oc annotate --overwrite namespace default \
2 openshift.io/node-selector='region=infra'
OCP 3.9 quick installer和advanced installer的Ansible playbook都支持Ansible變量,這些變量控制安裝過程中分配給節點的標籤,也控制分配給每個基礎設施pod的節點選擇器。
安裝OCP子系統(如metrics子系統)的劇本還支持這些子系統節點選擇器的變量。
四 控制Pod調度
4.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
4.2 本練習準備
1 [student@workstation ~]$ lab schedule-control setup
2 [student@workstation ~]$ oc login -u admin -p redhat https://master.lab.example.com
4.3 查看region
1 [student@workstation ~]$ oc get nodes -L region
2 NAME STATUS ROLES AGE VERSION REGION
3 master.lab.example.com Ready master 2d v1.9.1+a0ce1bc657
4 node1.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 infra
5 node2.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 infra
4.4 創建project
1 [student@workstation ~]$ oc new-project schedule-control
4.5 創建應用
1 [student@workstation ~]$ oc new-app --name=hello \
2 --docker-image=registry.lab.example.com/openshift/hello-openshift
4.6 擴展應用
1 [student@workstation ~]$ oc scale dc hello --replicas=5
2 deploymentconfig "hello" scaled
3 [student@workstation ~]$ oc get pod -o wide
4 NAME READY STATUS RESTARTS AGE IP NODE
5 hello-1-c5z2n 1/1 Running 0 7s 10.128.0.21 node1.lab.example.com
6 hello-1-hhvp7 1/1 Running 0 34s 10.129.0.38 node2.lab.example.com
7 hello-1-jqrkb 1/1 Running 0 7s 10.128.0.20 node1.lab.example.com
8 hello-1-tgmbr 1/1 Running 0 7s 10.129.0.39 node2.lab.example.com
9 hello-1-z2bn7 1/1 Running 0 7s 10.128.0.22 node1.lab.example.com
4.7 修改節點label
1 [student@workstation ~]$ oc label node node2.lab.example.com region=apps --overwrite=true
2 [student@workstation ~]$ oc get nodes -L region #確認修改
3 NAME STATUS ROLES AGE VERSION REGION
4 master.lab.example.com Ready master 2d v1.9.1+a0ce1bc657
5 node1.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 infra
6 node2.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 apps
4.8 導出dc
1 [student@workstation ~]$ oc get dc hello -o yaml > dc.yaml
4.9 修改node2調度策略
添加dc.yaml中的調度策略,使pod調度至apps標籤的node。
1 [student@workstation ~]$ vi dc.yaml
2 ……
3 template:
4 ……
5 spec:
6 nodeSelector: #添加節點選擇器
7 region: apps
8 ……
4.10 應用更新
1 [student@workstation ~]$ oc apply -f dc.yaml
4.11 確認驗證
1 [student@workstation ~]$ oc get pod -o wide
2 NAME READY STATUS RESTARTS AGE IP NODE
3 hello-2-4c2gv 1/1 Running 0 40s 10.129.0.42 node2.lab.example.com
4 hello-2-6966b 1/1 Running 0 38s 10.129.0.43 node2.lab.example.com
5 hello-2-dcqbr 1/1 Running 0 36s 10.129.0.44 node2.lab.example.com
6 hello-2-dlf8k 1/1 Running 0 36s 10.129.0.45 node2.lab.example.com
7 hello-2-rnk4w 1/1 Running 0 40s 10.129.0.41 node2.lab.example.com
#驗證是否觸發了新的部署,並等待所有新的應用pod都準備好並運行。所有5個pod都應該調度至node2。
4.12 修改node1調度策略
1 [student@workstation ~]$ oc label node node1.lab.example.com region=apps --overwrite=true
2 [student@workstation ~]$ oc get node -L region
3 NAME STATUS ROLES AGE VERSION REGION
4 master.lab.example.com Ready master 2d v1.9.1+a0ce1bc657
5 node1.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 apps
6 node2.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 apps
4.13 終止node2
1 [student@workstation ~]$ oc adm manage-node --schedulable=false node2.lab.example.com
2 NAME STATUS ROLES AGE VERSION
3 node2.lab.example.com Ready,SchedulingDisabled compute 2d v1.9.1+a0ce1bc657
4.14 刪除pod
刪除node2的pod,並使用node1創建的pod替換。
1 [student@workstation ~]$ oc adm drain node2.lab.example.com --delete-local-data
4.15 查看pod
1 [student@workstation ~]$ oc get pods -o wide
2 NAME READY STATUS RESTARTS AGE IP NODE
3 hello-2-bjsj4 1/1 Running 0 51s 10.128.0.25 node1.lab.example.com
4 hello-2-kmmmn 1/1 Running 0 50s 10.128.0.23 node1.lab.example.com
5 hello-2-n6wvj 1/1 Running 0 51s 10.128.0.24 node1.lab.example.com
6 hello-2-plr65 1/1 Running 0 50s 10.128.0.26 node1.lab.example.com
7 hello-2-xsz68 1/1 Running 0 51s 10.128.0.27 node1.lab.example.com
五 管理IS、image、Templates
5.1 image介紹
在OpenShift中,image是一個可部署的runtime模板,它包含運行單個容器的所有需求,還包括imag功能的元數據。image可以通過多種方式管理,如tag、import、pull和update。
image可以跨多個主機部署在多個容器中。開發人員可以使用Docker構建image,也可以使用OpenShift構建工具。
OpenShift實現了靈活的image管理機制。一個image名稱實際上可以引用同一image的許多不同版本。唯一的image由它的sha256哈希引用,Docker不使用版本號。相反,它使用tag來管理image,例如v1、v2或默認的latest tag。
5.2 IS
IS包括由tags標識的任意數量的容器images。它是相關image的統一虛擬視圖,類似於Docker image倉庫。開發人員有許多與image和IS交互的方法。例如,當添加或修改新image時,build和deployment可以接收通知,並通過運行新build或新deployment做出相應的動作。
5.3 標記image
OCP提供了oc tag命令,它類似於docker tag命令,但是,它是對IS而不是image進行操作。
可以向image添加tag,以便更容易地確定它們包含什麼。tag是指定image版本的標識符。
示例:將Apache web服務器2.4版本的映像,可將該image執行以下標記。
apache: 2.4
如果倉庫包含Apache web服務器的最新版本,他們可以使用latest標籤來表示這是倉庫中可用的最新image。
apache:latest
oc tag命令用於標籤image:
[user@demo ~]$ oc tag source destination
source:現有tag或圖像流中的圖像。
destination:標籤在一個或多個IS中的最新image。
示例:將ruby image的現有latest標記修改為當前版本v2.0標識,
[user@demo ~]$ oc tag ruby:latest ruby:2.0
5.4 刪除tag
若要從image中刪除標記,可使用-d參數。
[user@demo ~]$ oc tag -d ruby:latest
可以使用不同類型的標籤,默認行為使用permanent tag,即源文件發生更改,該tag也會及時指向image,與目標tag無關。
tracking tag指示在導入image期間導入目標tag的元數據。要確保目標tag在源tag更改時得到更新,需使用–alias=true標識。
[user@demo ~]$ oc tag –alias=true source destination
要重新導入tag,可使用–scheduled=true標識。
[user@demo ~]$ oc tag –scheduled=true source destination
要配置Docker始終從內部倉庫中獲取image,可使用–reference-policy=local標誌。默認情況下,image指向本地倉庫。從而實現在之後調用image的時候可以快速pull。
[user@demo ~]$ oc tag –reference-policy=local source destination
5.5 建議的tag形式
在管理tag時,開發人員應該考慮映像的生命周期,參考下錶開發人員用來管理映像的可能的標記命名約定。
| 描述 |
示例 |
| Revision |
myimage:v2.0.1 |
| Architecture |
myimage:v2.0-x86_64 |
| Base Image |
myimage:v1.2-rhel7 |
| Latest Image |
myimage:latest |
| Latest Stable |
Image myimage:stable |
5.6 Templates介紹
模板描述一組對象,其中包含處理後生成對象列表的參數。可以處理模板來創建開發人員有權在項目中創建的任何內容,例如service、build、configuration和dc。
模板還可以定義一組標籤,應用於它定義的每個對象。開發人員可以使用命令行界面或web控制台從模板創建對象列表。
5.7 Templates管理
開發人員可以用JSON或YAML格式編寫模板,並使用命令行界面或web控制台導入它們。模板被保存到項目中,以供對該特定項目具有適當訪問權限的任何用戶重複使用。
示例:導入模板。
[user@demo ~]$ oc create -f filename
還可以在導入模板時分配標籤,這意味着模板定義的所有對象都將被標記。
[user@demo ~]$ oc create -f filename -l name=mylabel
5.8 使用模板
OCP提供了許多默認的instant app和QuickStart模板,允許開發人員為不同的語言快速創建新的應用程序。為Rails (Ruby)、Django (Python)、Node.js、CakePHP (PHP)和Dancer (Perl)提供了模板。
要列出集群中的可用模板,請運行oc get templates命令。參數-n指定要使用的項目。
[user@demo ~]$ oc get templates -n openshift
開發人員還可以使用web控制台瀏覽模板,當您選擇模板時,可以調整可用的參數來自定義模板定義的資源。
六 管理IS
6.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
6.2 本練習準備
1 [student@workstation ~]$ lab schedule-is setup
6.3 創建項目
1 [student@workstation ~]$ oc login -u developer -p redhat \
2 https://master.lab.example.com
3 [student@workstation ~]$ oc new-project schedule-is
6.4 創建應用
1 [student@workstation ~]$ oc new-app --name=phpmyadmin \
2 --docker-image=registry.lab.example.com/phpmyadmin/phpmyadmin:4.7
6.5 創建服務賬戶
1 [student@workstation ~]$ oc login -u admin -p redhat
2 [student@workstation ~]$ oc project schedule-is
3 [student@workstation ~]$ oc create serviceaccount phpmyadmin-account
6.6 授權特權運行
1 [student@workstation ~]$ oc adm policy add-scc-to-user anyuid \
2 -z phpmyadmin-account
6.7 更新pod
1 [student@workstation ~]$ oc login -u developer
2 [student@workstation ~]$ oc patch dc/phpmyadmin --patch \
3 '{"spec":{"template":{"spec":{"serviceAccountName": "phpmyadmin-account"}}}}'
更新負責管理phpmyadmin部署的dc資源,以便使用新創建的服務帳戶。可以使用oc patch或oc edit命令。此命令可以從/home/student/DO280/labs/secure-review文件夾中的patch-dc.sh腳本中複製。
1 [student@workstation ~]$ oc get pods #確認驗證
2 NAME READY STATUS RESTARTS AGE
3 phpmyadmin-2-vh29z 1/1 Running 0 3m
提示:name后的2表示這個pod是第二次部署,即進行過迭代。
6.8 更新內部倉庫image
1 [student@workstation ~]$ cd /home/student/DO280/labs/schedule-is/
2 [student@workstation schedule-is]$ ls
3 phpmyadmin-latest.tar trust_internal_registry.sh
4 [student@workstation schedule-is]$ docker load -i phpmyadmin-latest.tar
5 #使用docker load命令加載新的image。
6 [student@workstation schedule-is]$ docker images
7 REPOSITORY TAG IMAGE ID CREATED SIZE
8 <none> <none> 93d0d7db5ce2 13 months ago 166 MB
6.9 tag鏡像
1 [student@workstation schedule-is]$ docker tag 93d0d7db5ce2 \
2 docker-registry-default.apps.lab.example.com/schedule-is/phpmyadmin:4.7
3 #打完標記進行推送。
6.10 登錄docker倉庫
結論:docker倉庫會提示因為是自簽名證書,因此判定為不安全的方式。
6.11 修改信任
本環境使用/home/student/DO280/labs/secure-review文件夾中的trust_internal_registry.sh腳本,配置docker倉庫信任OpenShift內部倉庫。
1 [student@workstation schedule-is]$ ./trust_internal_registry.sh
6.12 推送image
1 [student@workstation schedule-is]$ docker push \
2 docker-registry-default.apps.lab.example.com/schedule-is/phpmyadmin:4.7
6.13 確認更新
驗證當源image更新后,是否能自動觸發OpenShift進行pod更新。
1 [student@workstation schedule-is]$ oc get pods
2 NAME READY STATUS RESTARTS AGE
3 phpmyadmin-3-hnfjk 1/1 Running 0 23s
七 管理應用部署實驗
7.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
7.2 本練習準備
1 [student@workstation ~]$ lab manage-review setup
7.3 確認region
1 [student@workstation ~]$ oc login -uadmin -predhat https://master.lab.example.com
2 [student@workstation ~]$ oc get nodes -L region
3 NAME STATUS ROLES AGE VERSION REGION
4 master.lab.example.com Ready master 2d v1.9.1+a0ce1bc657
5 node1.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 infra
6 node2.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 infra
7.4 修改region
1 [student@workstation ~]$ oc label node node1.lab.example.com region=services --overwrite=true
2 [student@workstation ~]$ oc label node node2.lab.example.com region=applications --overwrite=true
3 [student@workstation ~]$ oc get nodes -L region
4 NAME STATUS ROLES AGE VERSION REGION
5 master.lab.example.com Ready master 2d v1.9.1+a0ce1bc657
6 node1.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 services
7 node2.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 applications
7.5 創建項目
1 [student@workstation ~]$ oc new-project manage-review
7.6 創建應用
1 [student@workstation ~]$ oc new-app -i php:7.0 \
2 http://registry.lab.example.com/version
7.7 擴展應用
1 [student@workstation ~]$ oc scale dc version --replicas=3
2 [student@workstation ~]$ oc get pods -o wide #確認驗證
3 NAME READY STATUS RESTARTS AGE IP NODE
4 version-1-9626w 1/1 Running 0 40s 10.129.0.55 node2.lab.example.com
5 version-1-build 0/1 Completed 0 1m 10.129.0.52 node2.lab.example.com
6 version-1-f6vj2 1/1 Running 0 40s 10.129.0.56 node2.lab.example.com
7 version-1-mrhk4 1/1 Running 0 45s 10.129.0.54 node2.lab.example.com
結論:應用程序pod並沒有均分在兩個集群node節點之間,因為每個節點屬於不同的region,並且默認的OpenShift調度器配置打開了區域粘性。
7.8 調度pod
1 [student@workstation ~]$ oc export dc version -o yaml > version-dc.yml #導出yaml
2 spac
3 ……
4 template:
5 metadata:
6 ……
7 spec:
8 nodeSelector: #添加節點選擇器
9 region: applications
10 ……
7.9 迭代部署
1 [student@workstation ~]$ oc replace -f version-dc.yml #迭代
7.10 確認驗證
1 [student@workstation ~]$ oc get pod -o wide
2 NAME READY STATUS RESTARTS AGE IP NODE
3 version-1-build 0/1 Completed 0 15m 10.129.0.52 node2.lab.example.com
4 version-2-2bmqq 1/1 Running 0 58s 10.129.0.60 node2.lab.example.com
5 version-2-nz58r 1/1 Running 0 1m 10.129.0.59 node2.lab.example.com
6 version-2-rlj2h 1/1 Running 0 1m 10.129.0.58 node2.lab.example.com
驗證是否啟動了新的部署,並且在node2節點上運行了一組新的版本莢。等待所有三個新的應用程序莢都準備好並運行
7.11 修改region
1 [student@workstation ~]$ oc label node node1.lab.example.com region=applications --overwrite=true
2 [student@workstation ~]$ oc get nodes -L region #確認驗證
3 NAME STATUS ROLES AGE VERSION REGION
4 master.lab.example.com Ready master 2d v1.9.1+a0ce1bc657
5 node1.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 applications
6 node2.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 applications
7.12 終止node2
1 [student@workstation ~]$ oc adm manage-node --schedulable=false node2.lab.example.com
2 NAME STATUS ROLES AGE VERSION
3 node2.lab.example.com Ready,SchedulingDisabled compute 2d v1.9.1+a0ce1bc657
7.13 刪除pod
刪除node2的pod,並使用node1創建的pod替換。
1 [student@workstation ~]$ oc adm drain node2.lab.example.com --delete-local-data
7.14 查看pod
1 [student@workstation ~]$ oc get pods -o wide
2 NAME READY STATUS RESTARTS AGE IP NODE
3 version-2-d9fhp 1/1 Running 0 3m 10.128.0.34 node1.lab.example.com
4 version-2-jp5gr 1/1 Running 0 3m 10.128.0.35 node1.lab.example.com
5 version-2-z5lv5 1/1 Running 0 3m 10.128.0.33 node1.lab.example.com
7.15 暴露服務
1 [student@workstation ~]$ oc expose service version --hostname=version.apps.lab.example.com
2 [student@workstation ~]$ curl http://version.apps.lab.example.com #確認測試
3 <html>
4 <head>
5 <title>PHP Test</title>
6 </head>
7 <body>
8 <p>Version v1</p>
9 </body>
10 </html>
7.16 確認驗證
1 [student@workstation ~]$ lab manage-review grade #環境腳本判斷
7.17 還原環境
1 [student@workstation ~]$ oc adm manage-node --schedulable=true node2.lab.example.com
2 [student@workstation ~]$ oc label node node1.lab.example.com region=infra --overwrite=true
3 [student@workstation ~]$ oc label node node2.lab.example.com region=infra --overwrite=true
4 [student@workstation ~]$ oc get node -L region
5 NAME STATUS ROLES AGE VERSION REGION
6 master.lab.example.com Ready master 2d v1.9.1+a0ce1bc657
7 node1.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 infra
8 node2.lab.example.com Ready compute 2d v1.9.1+a0ce1bc657 infra
9 [student@workstation ~]$ oc delete project manage-review
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?

 沙耶武里水壩即將完工。照片來源:
沙耶武里水壩即將完工。照片來源:  沙耶武里水壩開發前的地景樣貌。照片來源: (CC BY 2.0)
沙耶武里水壩開發前的地景樣貌。照片來源: (CC BY 2.0)