MOJITO
最近一直啥都沒寫,追個熱點都趕不上熱乎的,鄙視自己一下。
周董的新歌 「MOJITO」 發售(6 月 12 日的零點)至今大致過去了一周,翻開 B 站 MV 一看,播放量妥妥破千萬,彈幕破十萬,這人氣還真是杠杠的。
說實話, 「MOJITO」 這個名字對我來講有點超綱了,第一次見到完全不知道啥意思。
不過問題不大,沒有什麼是百度解決不了的,如果有,那就再加一個知乎。
MOJITO 的中文名是莫吉托,百度百科上是這麼介紹莫吉托的:
莫吉托(Mojito)是最有名的朗姆調酒之一。起源於古巴。傳統上,莫吉托是一種由五種材料製成的雞尾酒:淡朗姆酒、糖(傳統上是用甘蔗汁)、萊姆(青檸)汁、蘇打水和薄荷。最原始的古巴配方是使用留蘭香或古巴島上常見的檸檬薄荷。萊姆(青檸)與薄荷的清爽口味是為了與朗姆酒的烈性相互補,同時也使得這種透明無色的調酒成為夏日的熱門飲料之一。這種調酒有着相對低的酒精含量(大約10%)。
酒精度數在 10% 左右的話,姑且可以認為一種飲料吧。
當然,如果要開車的話就不能把 MOJITO 當成飲料了,酒精含量再低那也是酒精。
整個 MV 我翻來覆去的看了好幾遍, 「MOJITO」 這個東西除了在歌詞和名字中有出現,在 MV 當中一次都沒出現,毫無存在感。
爬取 B 站彈幕
彈幕數據的爬取比較簡單,我就不一步一步的抓請求給各位演示了,注意下面這幾個請求連接:
彈幕請求地址:
https://api.bilibili.com/x/v1/dm/list.so?oid=XXX
https://comment.bilibili.com/XXX.xml
第一個地址由於 B 站的網頁做了更換,現在在 Chrome 工具的 network 裏面已經找不到了,不過還可以用,這個是我之前找到的。
第二個地址來源於百度,我也不知道各路大神是從哪找出來這個地址的,供參考吧。
上面這兩個彈幕地址實際上都需要一個叫 oid 的東西,這個 oid 獲取方式如下:
首先可以找到一個目錄頁接口:
https://api.bilibili.com/x/player/pagelist?bvid=XXX&jsonp=jsonp
這個接口也是來源於 Chrome 的 network ,其中 bvid 這個參數來源於視頻地址,比如周董的這個 「MOJITO」 的 MV ,地址是 https://www.bilibili.com/video/BV1PK4y1b7dt ,那麼這個 bvid 的值就是最後那一部分 BV1PK4y1b7dt 。
接下來在 https://api.bilibili.com/x/player/pagelist?bvid=BV1PK4y1b7dt&jsonp=jsonp 這個接口中,我們可以看到返回的 json 參數,如下:
{
"code":0,
"message":"0",
"ttl":1,
"data":[
{
"cid":201056987,
"page":1,
"from":"vupload",
"part":"JAY-MOJITO_完整MV(更新版)",
"duration":189,
"vid":"",
"weblink":"",
"dimension":{
"width":1920,
"height":1080,
"rotate":0
}
}
]
}
注意:由於這個 MV 只有一個完整的視頻,所以這裏只有一個 cid ,如果一個視頻是分不同小節發布的,這裏就會有多個 cid ,不同的 cid 代表不同的視頻。
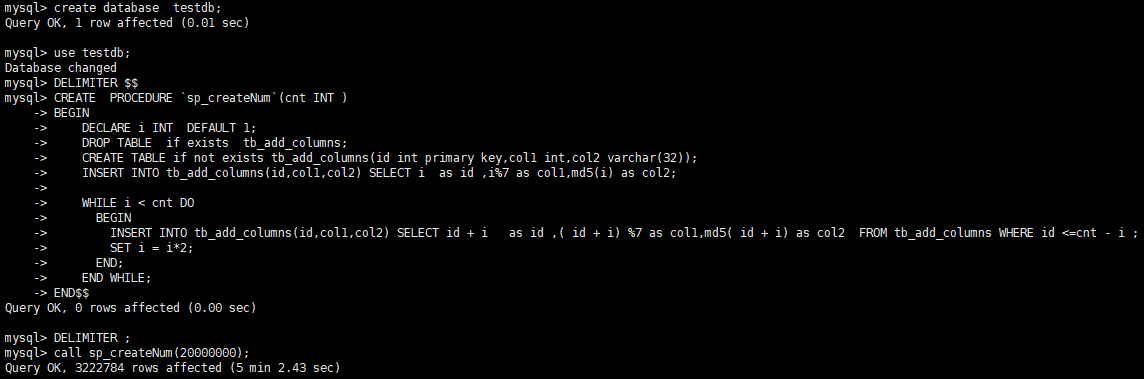
當然,這裏的 cid 就是我們剛才想找的那個 oid ,把這個 cid 拼到剛才的鏈接上,可以得到 https://api.bilibili.com/x/v1/dm/list.so?oid=201056987 這樣一個地址,然後輸入到瀏覽器中,可以看到彈幕的返回數據,是一個 xml 格式的文本。
源代碼如下:
import requests
import re
# 獲取 cid
res = requests.get("https://api.bilibili.com/x/player/pagelist?bvid=BV1PK4y1b7dt&jsonp=jsonp")
cid = res.json()['data'][0]['cid']
# 將彈幕 xml 通過正則取出,生成 list
danmu_url = f"https://api.bilibili.com/x/v1/dm/list.so?oid={cid}"
result = requests.get(danmu_url).content.decode('utf-8')
pattern = re.compile('<d.*?>(.*?)</d>')
danmu_list = pattern.findall(result)
# 將彈幕 list 保存至 txt 文件
with open("dan_mu.txt", mode="w", encoding="utf-8") as f:
for item in danmu_list:
f.write(item)
f.write("\n")
這裏我將獲取到的彈幕保存在了 dan_mu.txt 文件中,方便後續分析。
繪製詞雲圖
第一步先將剛才保存在 dan_mu.txt 文件中的彈幕讀取出來,放到了一個 list 當中:
# 讀取彈幕 txt 文件
with open("dan_mu.txt", encoding="utf-8") as f:
txt = f.read()
danmu_list = txt.split("\n")
然後使用分詞工具對彈幕進行分詞,我這裏使用的分詞工具是最好的 Python 中文分詞組件 jieba ,沒有安裝過 jieba 的同學可以使用以下命令進行安裝:
pip install jieba
使用 jieba 對剛才獲得的彈幕 list 進行分詞:
# jieba 分詞
danmu_cut = [jieba.lcut(item) for item in danmu_list]
這樣,我們獲得了分詞后的 danmu_cut ,這個同樣是一個 list 。
接着我們對分詞后的 danmu_cut 進行下一項操作,去除停用詞:
# 獲取停用詞
with open("baidu_stopwords.txt",encoding="utf-8") as f:
stop = f.read()
stop_words = stop.split()
# 去掉停用詞后的最終詞
s_data_cut = pd.Series(danmu_cut)
all_words_after = s_data_cut.apply(lambda x:[i for i in x if i not in stop])
這裏我引入了一個 baidu_stopwords.txt 文件,這個文件是百度停用詞庫,這裏我找到了幾個常用的中文停用詞庫,來源: https://github.com/goto456/stopwords 。
| 詞表文件 | 詞表名 |
|---|---|
| baidu_stopwords.txt | 百度停用詞表 |
| hit_stopwords.txt | 哈工大停用詞表 |
| scu_stopwords.txt | 四川大學機器智能實驗室停用詞庫 |
| cn_stopwords.txt | 中文停用詞表 |
這裏我使用的是百度停用詞表,大家可以根據自己的需要使用,也可以對這幾個停用詞表先做整合后再使用,主要的目的就是去除一些無需關注的詞,上面這幾個停用詞庫我都會提交到代碼倉庫,有需要的自取。
接着我們統計去除停用詞后的詞頻:
# 詞頻統計
all_words = []
for i in all_words_after:
all_words.extend(i)
word_count = pd.Series(all_words).value_counts()
最後一步就是生成我們的最終結果,詞雲圖:
wordcloud.WordCloud(
font_path='msyh.ttc',
background_color="#fff",
max_words=1000,
max_font_size=200,
random_state=42,
width=900,
height=1600
).fit_words(word_count).to_file("wordcloud.png")
最終結果就是下面這個:
從上面這個詞雲圖中可以看到,粉絲對「MOJITO」這首歌是真愛啊,出現頻率最高的就是 啊啊啊 和 愛 還有 粉 。
當然哈,這個 粉 也有可能是說 MV 當中那台騷氣十足的粉色的老爺車。
還有一個出現頻率比較高的是 爺青回 ,我估計這個意思應該是 爺的青春回來啦 ,確實,周董伴隨着我這個年齡段的人一路走來,做為一位 79 年的人現在已經是 41 歲的「高齡」了,回首往昔,讓人唏噓不已。
當年一首 「雙節棍」 火遍了中華大地,大街上的音像店整天都在循環這幾首歌,在學校上學的我這一代人,基本上是人人都能哼兩句,「快使用雙截棍,哼哼哈嘿」成了我們這一代人共有的回憶。
智能情感傾向分析
我們還可以對彈幕進行一次情感傾向分析,這裏我使用的是 「百度 AI 開放平台」 的情感傾向分析接口。
百度 AI 開放平台文檔地址:https://ai.baidu.com/ai-doc/NLP/zk6z52hds
首先是根據文檔接入 「百度 AI 開放平台」 ,獲取 access_token ,代碼如下:
# 獲取 Baidu API access_token
access_token_url = f'https://aip.baidubce.com/oauth/2.0/token?grant_type={grant_type}&client_id={client_id}&client_secret={client_secret}&'
res = requests.post(access_token_url)
access_token = res.json()['access_token']
# 通用情感接口
# sentiment_url = f'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token={access_token}'
# 定製化情感接口
sentiment_url = f'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify_custom?charset=UTF-8&access_token={access_token}'
百度 AI 開放平台有兩個情感分析接口,一個是通用的,還有一個是定製化的,我這裏使用的是經過訓練的定製化的接口,如果沒有定製化的接口,使用通用的接口也沒有問題。
上面使用到的 grant_type , client_id , client_secret 這幾個參數,大家註冊一下就能得到, 「百度 AI 開放平台」 上的這些接口都有調用數量的限制,不過我們自己使用已經足夠了。
然後讀取我們剛才保存的彈幕文本:
with open("dan_mu.txt", encoding="utf-8") as f:
txt = f.read()
danmu_cat = txt.split("\n")
在調用接口獲得情感傾向之前,我們還需要做一件事情,對彈幕進行一次處理,因為彈幕中會有一些 emoji 表情,而 emoji 直接請求百度的接口會返回錯誤,這裏我使用另一個工具包對 emoji 表情進行處理。
首先安裝工具包 emoji :
pip install emoji
使用是非常簡單的,我們對彈幕數據使用 emoji 進行一次處理:
import emoji
with open("dan_mu.txt", encoding="utf-8") as f:
txt = f.read()
danmu_list = txt.split("\n")
for item in danmu_list:
print(emoji.demojize(item))
我們的彈幕數據中是有這樣的 emoji 表情的:
# 處理后:
:red_heart::red_heart::red_heart::red_heart::red_heart::red_heart::red_heart:
然後,我們就可以調用百度的情感傾向分析接口,對我們的彈幕數據進行分析了:
# 情感計數器
optimistic = 0
neutral = 0
pessimistic = 0
for danmu in danmu_list:
# 因調用 QPS 限制,每次調用間隔 0.5s
time.sleep(0.5)
req_data = {
'text': emoji.demojize(danmu)
}
# 調用情感傾向分析接口
if len(danmu) > 0:
r = requests.post(sentiment_url, json = req_data)
print(r.json())
for item in r.json()['items']:
if item['sentiment'] == 2:
# 正向情感
optimistic += 1
if item['sentiment'] == 1:
# 中性情感
neutral += 1
if item['sentiment'] == 0:
# 負向情感
pessimistic += 1
print('正向情感:', optimistic)
print('中性情感:', neutral)
print('負向情感:', pessimistic)
attr = ['正向情感','中性情感','負向情感']
value = [optimistic, neutral, pessimistic]
c = (
Pie()
.add("", [list(attr) for attr in zip(attr, value)])
.set_global_opts(title_opts=opts.TitleOpts(title="「MOJITO」彈幕情感分析"))
.render("pie_base.html")
)
最後的結果圖長這樣:
從最後的結果上來看,正向情感佔比大約在 2/3 左右,而負向情感只有不到 1/4 ,看來大多數人看到周董的新歌還是滿懷激動的心情。
不過這個數據不一定準確,最多可以做一個參考。
源代碼
需要源代碼的同學可以在公眾號後台回復「MOJITO」獲取。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧

.jpg)