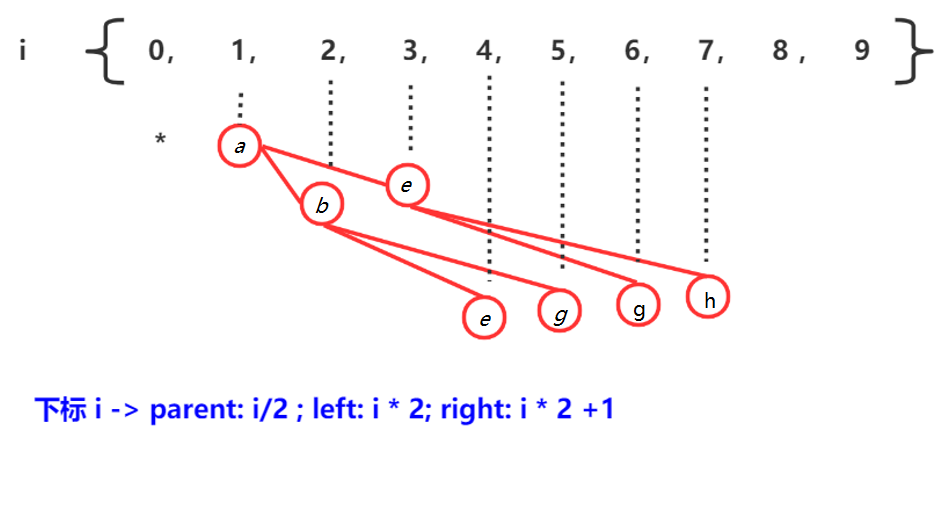
枚舉是 JDK 1.5 新增的數據類型,使用枚舉我們可以很好的描述一些特定的業務場景,比如一年中的春、夏、秋、冬,還有每周的周一到周天,還有各種顏色,以及可以用它來描述一些狀態信息,比如錯誤碼等。
枚舉類型不止存在在 Java 語言中,在其它語言中也都能找到它的身影,例如 C# 和 Python 等,但我發現在實際的項目中使用枚舉的人很少,所以本文就來聊一聊枚舉的相關內容,好讓朋友們對枚舉有一個大概的印象,這樣在編程時起碼還能想到有“枚舉”這樣一個類型。
本文的結構目錄如下:
枚舉的 7 種使用方法
很多人不使用枚舉的一個重要的原因是對枚舉不夠熟悉,那麼我們就先從枚舉的 7 種使用方法說起。
用法一:常量
在 JDK 1.5 之前,我們定義常量都是 public static final... ,但有了枚舉,我們就可以把這些常量定義成一個枚舉類了,實現代碼如下:
public enum ColorEnum {
RED, GREEN, BLANK, YELLOW
}
用法二:switch
將枚舉用在 switch 判斷中,使得代碼可讀性更高了,實現代碼如下:
enum ColorEnum {
GREEN, YELLOW, RED
}
public class ColorTest {
ColorEnum color = ColorEnum.RED;
public void change() {
switch (color) {
case RED:
color = ColorEnum.GREEN;
break;
case YELLOW:
color = ColorEnum.RED;
break;
case GREEN:
color = ColorEnum.YELLOW;
break;
}
}
}
用法三:枚舉中增加方法
我們可以在枚舉中增加一些方法,讓枚舉具備更多的特性,實現代碼如下:
public class EnumTest {
public static void main(String[] args) {
ErrorCodeEnum errorCode = ErrorCodeEnum.SUCCESS;
System.out.println("狀態碼:" + errorCode.code() +
" 狀態信息:" + errorCode.msg());
}
}
enum ErrorCodeEnum {
SUCCESS(1000, "success"),
PARAM_ERROR(1001, "parameter error"),
SYS_ERROR(1003, "system error"),
NAMESPACE_NOT_FOUND(2001, "namespace not found"),
NODE_NOT_EXIST(3002, "node not exist"),
NODE_ALREADY_EXIST(3003, "node already exist"),
UNKNOWN_ERROR(9999, "unknown error");
private int code;
private String msg;
ErrorCodeEnum(int code, String msg) {
this.code = code;
this.msg = msg;
}
public int code() {
return code;
}
public String msg() {
return msg;
}
public static ErrorCodeEnum getErrorCode(int code) {
for (ErrorCodeEnum it : ErrorCodeEnum.values()) {
if (it.code() == code) {
return it;
}
}
return UNKNOWN_ERROR;
}
}
以上程序的執行結果為:
狀態碼:1000 狀態信息:success
用法四:覆蓋枚舉方法
我們可以覆蓋一些枚舉中的方法用於實現自己的業務,比如我們可以覆蓋 toString() 方法,實現代碼如下:
public class EnumTest {
public static void main(String[] args) {
ColorEnum colorEnum = ColorEnum.RED;
System.out.println(colorEnum.toString());
}
}
enum ColorEnum {
RED("紅色", 1), GREEN("綠色", 2), BLANK("白色", 3), YELLOW("黃色", 4);
// 成員變量
private String name;
private int index;
// 構造方法
private ColorEnum(String name, int index) {
this.name = name;
this.index = index;
}
//覆蓋方法
@Override
public String toString() {
return this.index + ":" + this.name;
}
}
以上程序的執行結果為:
1:紅色
用法五:實現接口
枚舉類可以用來實現接口,但不能用於繼承類,因為枚舉默認繼承了 java.lang.Enum 類,在 Java 語言中允許實現多接口,但不能繼承多個父類,實現代碼如下:
public class EnumTest {
public static void main(String[] args) {
ColorEnum colorEnum = ColorEnum.RED;
colorEnum.print();
System.out.println("顏色:" + colorEnum.getInfo());
}
}
interface Behaviour {
void print();
String getInfo();
}
enum ColorEnum implements Behaviour {
RED("紅色", 1), GREEN("綠色", 2), BLANK("白色", 3), YELLOW("黃色", 4);
private String name;
private int index;
private ColorEnum(String name, int index) {
this.name = name;
this.index = index;
}
@Override
public void print() {
System.out.println(this.index + ":" + this.name);
}
@Override
public String getInfo() {
return this.name;
}
}
以上程序的執行結果為:
1:紅色
顏色:紅色
用法六:在接口中組織枚舉類
我們可以在一個接口中創建多個枚舉類,用它可以很好的實現“多態”,也就是說我們可以將擁有相同特性,但又有細微實現差別的枚舉類聚集在一個接口中,實現代碼如下:
public class EnumTest {
public static void main(String[] args) {
// 賦值第一個枚舉類
ColorInterface colorEnum = ColorInterface.ColorEnum.RED;
System.out.println(colorEnum);
// 賦值第二個枚舉類
colorEnum = ColorInterface.NewColorEnum.NEW_RED;
System.out.println(colorEnum);
}
}
interface ColorInterface {
enum ColorEnum implements ColorInterface {
GREEN, YELLOW, RED
}
enum NewColorEnum implements ColorInterface {
NEW_GREEN, NEW_YELLOW, NEW_RED
}
}
以上程序的執行結果為:
RED
NEW_RED
用法七:使用枚舉集合
在 Java 語言中和枚舉類相關的,還有兩個枚舉集合類 java.util.EnumSet 和 java.util.EnumMap,使用它們可以實現更多的功能。
使用 EnumSet 可以保證元素不重複,並且能獲取指定範圍內的元素,示例代碼如下:
import java.util.ArrayList;
import java.util.EnumSet;
import java.util.List;
public class EnumTest {
public static void main(String[] args) {
List<ColorEnum> list = new ArrayList<ColorEnum>();
list.add(ColorEnum.RED);
list.add(ColorEnum.RED); // 重複元素
list.add(ColorEnum.YELLOW);
list.add(ColorEnum.GREEN);
// 去掉重複數據
EnumSet<ColorEnum> enumSet = EnumSet.copyOf(list);
System.out.println("去重:" + enumSet);
// 獲取指定範圍的枚舉(獲取所有的失敗狀態)
EnumSet<ErrorCodeEnum> errorCodeEnums = EnumSet.range(ErrorCodeEnum.ERROR, ErrorCodeEnum.UNKNOWN_ERROR);
System.out.println("所有失敗狀態:" + errorCodeEnums);
}
}
enum ColorEnum {
RED("紅色", 1), GREEN("綠色", 2), BLANK("白色", 3), YELLOW("黃色", 4);
private String name;
private int index;
private ColorEnum(String name, int index) {
this.name = name;
this.index = index;
}
}
enum ErrorCodeEnum {
SUCCESS(1000, "success"),
ERROR(2001, "parameter error"),
SYS_ERROR(2002, "system error"),
NAMESPACE_NOT_FOUND(2003, "namespace not found"),
NODE_NOT_EXIST(3002, "node not exist"),
NODE_ALREADY_EXIST(3003, "node already exist"),
UNKNOWN_ERROR(9999, "unknown error");
private int code;
private String msg;
ErrorCodeEnum(int code, String msg) {
this.code = code;
this.msg = msg;
}
public int code() {
return code;
}
public String msg() {
return msg;
}
}
以上程序的執行結果為:
去重:[RED, GREEN, YELLOW]
所有失敗狀態:[ERROR, SYS_ERROR, NAMESPACE_NOT_FOUND, NODE_NOT_EXIST, NODE_ALREADY_EXIST, UNKNOWN_ERROR]
EnumMap 與 HashMap 類似,不過它是一個專門為枚舉設計的 Map 集合,相比 HashMap 來說它的性能更高,因為它內部放棄使用鏈表和紅黑樹的結構,採用數組作為數據存儲的結構。
EnumMap 基本使用示例如下:
import java.util.EnumMap;
public class EnumTest {
public static void main(String[] args) {
EnumMap<ColorEnum, String> enumMap = new EnumMap<>(ColorEnum.class);
enumMap.put(ColorEnum.RED, "紅色");
enumMap.put(ColorEnum.GREEN, "綠色");
enumMap.put(ColorEnum.BLANK, "白色");
enumMap.put(ColorEnum.YELLOW, "黃色");
System.out.println(ColorEnum.RED + ":" + enumMap.get(ColorEnum.RED));
}
}
enum ColorEnum {
RED, GREEN, BLANK, YELLOW;
}
以上程序的執行結果為:
RED:紅色
使用注意事項
阿里《Java開發手冊》對枚舉的相關規定如下,我們在使用時需要稍微注意一下。
【強制】所有的枚舉類型字段必須要有註釋,說明每個數據項的用途。
【參考】枚舉類名帶上 Enum 後綴,枚舉成員名稱需要全大寫,單詞間用下劃線隔開。說明:枚舉其實就是特殊的常量類,且構造方法被默認強制是私有。正例:枚舉名字為 ProcessStatusEnum 的成員名稱:SUCCESS / UNKNOWN_REASON。
假如不使用枚舉
在枚舉沒有誕生之前,也就是 JDK 1.5 版本之前,我們通常會使用 int 常量來表示枚舉,實現代碼如下:
public static final int COLOR_RED = 1;
public static final int COLOR_BLUE = 2;
public static final int COLOR_GREEN = 3;
但是使用 int 類型可能存在兩個問題:
第一, int 類型本身並不具備安全性,假如某個程序員在定義 int 時少些了一個 final 關鍵字,那麼就會存在被其他人修改的風險,而反觀枚舉類,它“天然”就是一個常量類,不存在被修改的風險(原因詳見下半部分);
第二,使用 int 類型的語義不夠明確,比如我們在控制台打印時如果只輸出 1…2…3 這樣的数字,我們肯定不知道它代表的是什麼含義。
那有人就說了,那就使用常量字符唄,這總不會還不知道語義吧?實現示例代碼如下:
public static final String COLOR_RED = "RED";
public static final String COLOR_BLUE = "BLUE";
public static final String COLOR_GREEN = "GREEN";
但是這樣同樣存在一個問題,有些初級程序員會不按套路出牌,他們可能會直接使用字符串的值進行比較,而不是直接使用枚舉的字段,實現示例代碼如下:
public class EnumTest {
public static final String COLOR_RED = "RED";
public static final String COLOR_BLUE = "BLUE";
public static final String COLOR_GREEN = "GREEN";
public static void main(String[] args) {
String color = "BLUE";
if ("BLUE".equals(color)) {
System.out.println("藍色");
}
}
}
這樣當我們修改了枚舉中的值,那程序就涼涼了。
枚舉使用場景
枚舉的常見使用場景是單例,它的完整實現代碼如下:
public class Singleton {
// 枚舉類型是線程安全的,並且只會裝載一次
private enum SingletonEnum {
INSTANCE;
// 聲明單例對象
private final Singleton instance;
// 實例化
SingletonEnum() {
instance = new Singleton();
}
private Singleton getInstance() {
return instance;
}
}
// 獲取實例(單例對象)
public static Singleton getInstance() {
return SingletonEnum.INSTANCE.getInstance();
}
private Singleton() {
}
// 類方法
public void sayHi() {
System.out.println("Hi,Java.");
}
}
class SingletonTest {
public static void main(String[] args) {
Singleton singleton = Singleton.getInstance();
singleton.sayHi();
}
}
因為枚舉只會在類加載時裝載一次,所以它是線程安全的,這也是《Effective Java》作者極力推薦使用枚舉來實現單例的主要原因。
知識擴展
枚舉為什麼是線程安全的?
這一點要從枚舉最終生成的字節碼說起,首先我們先來定義一個簡單的枚舉類:
public enum ColorEnumTest {
RED, GREEN, BLANK, YELLOW;
}
然後我們再將上面的那段代碼編譯為字節碼,具體內容如下:
public final class ColorEnumTest extends java.lang.Enum<ColorEnumTest> {
public static final ColorEnumTest RED;
public static final ColorEnumTest GREEN;
public static final ColorEnumTest BLANK;
public static final ColorEnumTest YELLOW;
public static ColorEnumTest[] values();
public static ColorEnumTest valueOf(java.lang.String);
static {};
}
從上述結果可以看出枚舉類最終會被編譯為被 final 修飾的普通類,它的所有屬性也都會被 static 和 final 關鍵字修飾,所以枚舉類在項目啟動時就會被 JVM 加載並初始化,而這個執行過程是線程安全的,所以枚舉類也是線程安全的類。
小貼士:代碼反編譯的過程是先用 javac 命令將 java 代碼編譯字節碼(.class),再使用 javap 命令查看編譯的字節碼。
枚舉比較小技巧
我們在枚舉比較時使用 == 就夠了,因為枚舉類是在程序加載時就創建了(它並不是 new 出來的),並且枚舉類不允許在外部直接使用 new 關鍵字來創建枚舉實例,所以我們在使用枚舉類時本質上只有一個對象,因此在枚舉比較時使用 == 就夠了。
並且我們在查看枚舉的 equlas() 源碼會發現,它的內部其實還是直接調用了 == 方法,源碼如下:
public final boolean equals(Object other) {
return this==other;
}
總結
本文我們介紹了枚舉類的 7 種使用方法:常量、switch、枚舉中添加方法、覆蓋枚舉方法、實現接口、在接口中組織枚舉類和使用枚舉集合等,然後講了如果不使用枚舉類使用 int 類型和 String 類型存在的一些弊端:語義不夠清晰、容易被修改、存在被誤用的風險,所以我們在適合的環境下應該盡量使用枚舉類。並且我們還講了枚舉類的使用場景——單例,以及枚舉類為什麼是安全的,最後我們講了枚舉比較的小技巧,希望本文對你有幫助。
查看 & 鳴謝
https://www.iteye.com/blog/softbeta-1185573
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!

 小米投資的電動代步車廠商 Ninebot 今天宣布與小米、順為資本、紅杉資本聯合出資收購電動代步車始祖 Segway,交易目前已全數完成。身為 Ninebot 的股東,這項收購除了意味著小米持續拓展海外市場外,對小米來說最大的收益,便是可取得 Segway 手中大量的專利。 總部位於美國的 Segway 成立於 2001 年,產品主要為雙輪的電動代步車,而 Ninebot 則是中國電動代步車品牌。Segway 在全球每年約只有 1 萬台左右的銷量,對增加 Ninebot 銷售量並沒有太大的直接幫助,據知情人士透露,先前 Segway 曾與包括法拉利、香奈兒等國際知名品牌合作,Ninebot 買下 Segway 主要是衝著其在海外的知名度,更重要的是可取得 Segway 手中握有的專利。 有趣的是,Segway 創辦人 Dean Kamen 曾在 2014 年控告 Ninebot 及其他中國廠商侵犯智慧財產權,美國國際貿易委員會於 11 月受理調查,而今調查結果尚未出爐,Segway 卻先被 Ninebot 收購,成為旗下全資子公司。 此外,Ninebot 執行長高祿峰同時也對外宣布已完成 8,000 萬美元的 A 輪融資,由小米、紅杉資本、順為資本共同出資,並表示未來將開發應用電動代步車、移動互聯網及人車互動技術的產品。 本文全文授權轉載自《科技新報》─〈〉
小米投資的電動代步車廠商 Ninebot 今天宣布與小米、順為資本、紅杉資本聯合出資收購電動代步車始祖 Segway,交易目前已全數完成。身為 Ninebot 的股東,這項收購除了意味著小米持續拓展海外市場外,對小米來說最大的收益,便是可取得 Segway 手中大量的專利。 總部位於美國的 Segway 成立於 2001 年,產品主要為雙輪的電動代步車,而 Ninebot 則是中國電動代步車品牌。Segway 在全球每年約只有 1 萬台左右的銷量,對增加 Ninebot 銷售量並沒有太大的直接幫助,據知情人士透露,先前 Segway 曾與包括法拉利、香奈兒等國際知名品牌合作,Ninebot 買下 Segway 主要是衝著其在海外的知名度,更重要的是可取得 Segway 手中握有的專利。 有趣的是,Segway 創辦人 Dean Kamen 曾在 2014 年控告 Ninebot 及其他中國廠商侵犯智慧財產權,美國國際貿易委員會於 11 月受理調查,而今調查結果尚未出爐,Segway 卻先被 Ninebot 收購,成為旗下全資子公司。 此外,Ninebot 執行長高祿峰同時也對外宣布已完成 8,000 萬美元的 A 輪融資,由小米、紅杉資本、順為資本共同出資,並表示未來將開發應用電動代步車、移動互聯網及人車互動技術的產品。 本文全文授權轉載自《科技新報》─〈〉