Dockerfile介紹及常用指令,包括FROM,RUN,還提及了 COPY,ADD,EXPOSE,WORKDIR等,其實 Dockerfile 功能很強大,它提供了十多個指令。
Dockerfile介紹
Dockerfile 是一個用來構建鏡像的文本文件,文本內容包含了一條條構建鏡像所需的指令和說明。
在Docker中創建鏡像最常用的方式,就是使用Dockerfile。Dockerfile是一個Docker鏡像的描述文件,我們可以理解成火箭發射的A、B、C、D…的步驟。Dockerfile其內部包含了一條條的指令,每一條指令構建一層,因此每一條指令的內容,就是描述該層應當如何構建。
FROM 指令-指定基礎鏡像
所謂定製鏡像,那一定是以一個鏡像為基礎,在其上進行定製。而 FROM 就是指定基礎鏡像,因此一個 Dockerfile 中 FROM 是必備的指令,並且必須是第一條指令。如下:
FROM centos
MAINTAINER 維護者信息
該鏡像是由誰維護的
MAINTAINER lightzhang lightzhang@xxx.com
ENV 設置環境變量
格式有兩種:
ENV <key> <value>
ENV <key1>=<value1> <key2>=<value2>...
這個指令很簡單,就是設置環境變量而已,無論是後面的其它指令,如 RUN,還是運行時的應用,都可以直接使用這裏定義的環境變量。
ENV VERSION=1.0 DEBUG=on \
NAME="Happy Feet"
這個例子中演示了如何換行,以及對含有空格的值用雙引號括起來的辦法,這和 Shell 下的行為是一致的。
下列指令可以支持環境變量展開:
ADD、COPY、ENV、EXPOSE、FROM、LABEL、USER、WORKDIR、VOLUME、STOPSIGNAL、ONBUILD、RUN。
可以從這個指令列表裡感覺到,環境變量可以使用的地方很多,很強大。通過環境變量,我們可以讓一份 Dockerfile 製作更多的鏡像,只需使用不同的環境變量即可。
ARG 構建參數
格式:ARG <參數名>[=<默認值>]
構建參數和 ENV 的效果一樣,都是設置環境變量。所不同的是,ARG 所設置的構建環境的環境變量,在將來容器運行時是不會存在這些環境變量的。但是不要因此就使用 ARG 保存密碼之類的信息,因為 docker history 還是可以看到所有值的。
Dockerfile 中的 ARG 指令是定義參數名稱,以及定義其默認值。該默認值可以在構建命令 docker build 中用 –build-arg <參數名>=<值> 來覆蓋。
在 1.13 之前的版本,要求 –build-arg 中的參數名,必須在 Dockerfile 中用 ARG 定義過了,換句話說,就是 –build-arg 指定的參數,必須在 Dockerfile 中使用了。如果對應參數沒有被使用,則會報錯退出構建。
從 1.13 開始,這種嚴格的限制被放開,不再報錯退出,而是显示警告信息,並繼續構建。這對於使用 CI 系統,用同樣的構建流程構建不同的 Dockerfile 的時候比較有幫助,避免構建命令必須根據每個 Dockerfile 的內容修改。
RUN 執行命令
RUN 指令是用來執行命令行命令的。由於命令行的強大能力,RUN 指令在定製鏡像時是最常用的指令之一。其格式有兩種:
shell 格式:RUN <命令>,就像直接在命令行中輸入的命令一樣。如下:
RUN echo '<h1>Hello, Docker!</h1>' > /usr/share/nginx/html/index.html
exec 格式:RUN [“可執行文件”, “參數1”, “參數2”],這更像是函數調用中的格式。
Dockerfile 中每一個指令都會建立一層,RUN 也不例外。每一個 RUN 的行為,都會新建立一層,在其上執行這些命令,執行結束后,commit 這一層的修改,構成新的鏡像。
Dockerfile 不推薦寫法:
1 FROM debian:stretch 2 3 RUN apt-get update 4 RUN apt-get install -y gcc libc6-dev make wget 5 RUN wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz" 6 RUN mkdir -p /usr/src/redis 7 RUN tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1 8 RUN make -C /usr/src/redis 9 RUN make -C /usr/src/redis install 10 RUN rm redis.tar.gz
上面的這種寫法,創建了 8 層鏡像。這是完全沒有意義的,而且很多運行時不需要的東西,都被裝進了鏡像里,比如編譯環境、更新的軟件包等等。最後一行即使刪除了軟件包,那也只是當前層的刪除;雖然我們看不見這個包了,但軟件包卻早已存在於鏡像中並一直跟隨着鏡像,沒有真正的刪除。
結果就是產生非常臃腫、非常多層的鏡像,不僅僅增加了構建部署的時間,也很容易出錯。 這是很多初學 Docker 的人常犯的一個錯誤。
另外:Union FS 是有最大層數限制的,比如 AUFS,曾經是最大不得超過 42 層,現在是不得超過 127 層。
Dockerfile 正確寫法:
1 FROM debian:stretch 2 3 RUN buildDeps='gcc libc6-dev make wget' \ 4 && apt-get update \ 5 && apt-get install -y $buildDeps \ 6 && wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz" \ 7 && mkdir -p /usr/src/redis \ 8 && tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1 \ 9 && make -C /usr/src/redis \ 10 && make -C /usr/src/redis install \ 11 && rm -rf /var/lib/apt/lists/* \ 12 && rm redis.tar.gz \ 13 && rm -r /usr/src/redis \ 14 && apt-get purge -y --auto-remove $buildDeps
這裏沒有使用很多個 RUN 對應不同的命令,而是僅僅使用一個 RUN 指令,並使用 && 將各個所需命令串聯起來。將之前的 8 層,簡化為了 1 層,且後面刪除了不需要的包和目錄。在撰寫 Dockerfile 的時候,要經常提醒自己,這並不是在寫 Shell 腳本,而是在定義每一層該如何構建。因此鏡像構建時,一定要確保每一層只添加真正需要添加的東西,任何無關的東西都應該清理掉。
很多人初學 Docker 製作出了很臃腫的鏡像的原因之一,就是忘記了每一層構建的最後一定要清理掉無關文件。
COPY 複製文件
格式:
1 COPY [--chown=<user>:<group>] <源路徑>... <目標路徑> 2 COPY [--chown=<user>:<group>] ["<源路徑1>",... "<目標路徑>"]
COPY 指令將從構建上下文目錄中 <源路徑> 的文件/目錄複製到新的一層的鏡像內的 <目標路徑> 位置。如:
COPY package.json /usr/src/app/
<源路徑> 可以是多個,甚至可以是通配符,其通配符規則要滿足 Go 的 filepath.Match 規則,如:
1 COPY hom* /mydir/ 2 COPY hom?.txt /mydir/
<目標路徑> 可以是容器內的絕對路徑,也可以是相對於工作目錄的相對路徑(工作目錄可以用 WORKDIR 指令來指定)。目標路徑不需要事先創建,如果目錄不存在會在複製文件前先行創建缺失目錄。
此外,還需要注意一點,使用 COPY 指令,源文件的各種元數據都會保留。比如讀、寫、執行權限、文件變更時間等。這個特性對於鏡像定製很有用。特別是構建相關文件都在使用 Git 進行管理的時候。
在使用該指令的時候還可以加上 –chown=<user>:<group> 選項來改變文件的所屬用戶及所屬組。
1 COPY --chown=55:mygroup files* /mydir/ 2 COPY --chown=bin files* /mydir/ 3 COPY --chown=1 files* /mydir/ 4 COPY --chown=10:11 files* /mydir/
ADD 更高級的複製文件
ADD 指令和 COPY 的格式和性質基本一致。但是在 COPY 基礎上增加了一些功能。
如果 <源路徑> 為一個 tar 壓縮文件的話,壓縮格式為 gzip, bzip2 以及 xz 的情況下,ADD 指令將會自動解壓縮這個壓縮文件到 <目標路徑> 去。
在某些情況下,如果我們真的是希望複製個壓縮文件進去,而不解壓縮,這時就不可以使用 ADD 命令了。
在 Docker 官方的 Dockerfile 最佳實踐文檔 中要求,盡可能的使用 COPY,因為 COPY 的語義很明確,就是複製文件而已,而 ADD 則包含了更複雜的功能,其行為也不一定很清晰。最適合使用 ADD 的場合,就是所提及的需要自動解壓縮的場合。
特別說明:在 COPY 和 ADD 指令中選擇的時候,可以遵循這樣的原則,所有的文件複製均使用 COPY 指令,僅在需要自動解壓縮的場合使用 ADD。
在使用該指令的時候還可以加上 –chown=<user>:<group> 選項來改變文件的所屬用戶及所屬組。
1 ADD --chown=55:mygroup files* /mydir/ 2 ADD --chown=bin files* /mydir/ 3 ADD --chown=1 files* /mydir/ 4 ADD --chown=10:11 files* /mydir/
WORKDIR 指定工作目錄
格式為 WORKDIR <工作目錄路徑>
使用 WORKDIR 指令可以來指定工作目錄(或者稱為當前目錄),以後各層的當前目錄就被改為指定的目錄,如該目錄不存在,WORKDIR 會幫你建立目錄。
之前提到一些初學者常犯的錯誤是把 Dockerfile 等同於 Shell 腳本來書寫,這種錯誤的理解還可能會導致出現下面這樣的錯誤:
1 RUN cd /app 2 RUN echo "hello" > world.txt
如果將這個 Dockerfile 進行構建鏡像運行后,會發現找不到 /app/world.txt 文件,或者其內容不是 hello。原因其實很簡單,在 Shell 中,連續兩行是同一個進程執行環境,因此前一個命令修改的內存狀態,會直接影響后一個命令;而在 Dockerfile 中,這兩行 RUN 命令的執行環境根本不同,是兩個完全不同的容器。這就是對 Dockerfile 構建分層存儲的概念不了解所導致的錯誤。
之前說過每一個 RUN 都是啟動一個容器、執行命令、然後提交存儲層文件變更。第一層 RUN cd /app 的執行僅僅是當前進程的工作目錄變更,一個內存上的變化而已,其結果不會造成任何文件變更。而到第二層的時候,啟動的是一個全新的容器,跟第一層的容器更完全沒關係,自然不可能繼承前一層構建過程中的內存變化。
因此如果需要改變以後各層的工作目錄的位置,那麼應該使用 WORKDIR 指令。
USER 指定當前用戶
格式:USER <用戶名>[:<用戶組>]
USER 指令和 WORKDIR 相似,都是改變環境狀態並影響以後的層。WORKDIR 是改變工作目錄,USER 則是改變之後層的執行 RUN, CMD 以及 ENTRYPOINT 這類命令的身份。
當然,和 WORKDIR 一樣,USER 只是幫助你切換到指定用戶而已,這個用戶必須是事先建立好的,否則無法切換。
1 RUN groupadd -r redis && useradd -r -g redis redis 2 USER redis 3 RUN [ "redis-server" ]
如果以 root 執行的腳本,在執行期間希望改變身份,比如希望以某個已經建立好的用戶來運行某個服務進程,不要使用 su 或者 sudo,這些都需要比較麻煩的配置,而且在 TTY 缺失的環境下經常出錯。建議使用 gosu。
1 # 建立 redis 用戶,並使用 gosu 換另一個用戶執行命令 2 RUN groupadd -r redis && useradd -r -g redis redis 3 # 下載 gosu 4 RUN wget -O /usr/local/bin/gosu "https://github.com/tianon/gosu/releases/download/1.7/gosu-amd64" \ 5 && chmod +x /usr/local/bin/gosu \ 6 && gosu nobody true 7 # 設置 CMD,並以另外的用戶執行 8 CMD [ "exec", "gosu", "redis", "redis-server" ]
VOLUME 定義匿名卷
格式為:
1 VOLUME ["<路徑1>", "<路徑2>"...] 2 VOLUME <路徑>
之前我們說過,容器運行時應該盡量保持容器存儲層不發生寫操作,對於數據庫類需要保存動態數據的應用,其數據庫文件應該保存於卷(volume)中。為了防止運行時用戶忘記將動態文件所保存目錄掛載為卷,在 Dockerfile 中,我們可以事先指定某些目錄掛載為匿名卷,這樣在運行時如果用戶不指定掛載,其應用也可以正常運行,不會向容器存儲層寫入大量數據。
VOLUME /data
這裏的 /data 目錄就會在運行時自動掛載為匿名卷,任何向 /data 中寫入的信息都不會記錄進容器存儲層,從而保證了容器存儲層的無狀態化。當然,運行時可以覆蓋這個掛載設置。比如:
docker run -d -v mydata:/data xxxx
在這行命令中,就使用了 mydata 這個命名卷掛載到了 /data 這個位置,替代了 Dockerfile 中定義的匿名卷的掛載配置。
EXPOSE 聲明端口
格式為 EXPOSE <端口1> [<端口2>...]
EXPOSE 指令是聲明運行時容器提供服務端口,這隻是一個聲明,在運行時並不會因為這個聲明應用就會開啟這個端口的服務。在 Dockerfile 中寫入這樣的聲明有兩個好處,一個是幫助鏡像使用者理解這個鏡像服務的守護端口,以方便配置映射;另一個用處則是在運行時使用隨機端口映射時,也就是 docker run -P 時,會自動隨機映射 EXPOSE 的端口。
要將 EXPOSE 和在運行時使用 -p <宿主端口>:<容器端口> 區分開來。-p,是映射宿主端口和容器端口,換句話說,就是將容器的對應端口服務公開給外界訪問,而 EXPOSE 僅僅是聲明容器打算使用什麼端口而已,並不會自動在宿主進行端口映射。
ENTRYPOINT 入口點
ENTRYPOINT 的格式和 RUN 指令格式一樣,分為 exec 格式和 shell 格式。
ENTRYPOINT 的目的和 CMD 一樣,都是在指定容器啟動程序及參數。ENTRYPOINT 在運行時也可以替代,不過比 CMD 要略顯繁瑣,需要通過 docker run 的參數 –entrypoint 來指定。
當指定了 ENTRYPOINT 后,CMD 的含義就發生了改變,不再是直接的運行其命令,而是將 CMD 的內容作為參數【】傳給 ENTRYPOINT 指令,換句話說實際執行時,將變為:
<ENTRYPOINT> "<CMD>"
那麼有了 CMD 后,為什麼還要有 ENTRYPOINT 呢?這種 <ENTRYPOINT> “<CMD>“ 有什麼好處么?讓我們來看幾個場景。
場景一:讓鏡像變成像命令一樣使用
假設我們需要一個得知自己當前公網 IP 的鏡像,那麼可以先用 CMD 來實現:
1 FROM centos:7.7.1908 2 CMD [ "curl", "-s", "ifconfig.io" ]
假如我們使用 docker build -t myip . 來構建鏡像的話,如果我們需要查詢當前公網 IP,只需要執行:
1 $ docker run myip 2 183.226.75.148
嗯,這麼看起來好像可以直接把鏡像當做命令使用了,不過命令總有參數,如果我們希望加參數呢?比如從上面的 CMD 中可以看到實質的命令是 curl,那麼如果我們希望显示 HTTP 頭信息,就需要加上 -i 參數。那麼我們可以直接加 -i 參數給 docker run myip 么?
1 $ docker run myip -i 2 docker: Error response from daemon: OCI runtime create failed: container_linux.go:348: starting container process caused "exec: \"-i\": executable file not found in $PATH": unknown. 3 ERRO[0000] error waiting for container: context canceled
我們可以看到可執行文件找不到的報錯,executable file not found。之前我們說過,跟在鏡像名後面的是 command【Usage: docker run [OPTIONS] IMAGE [COMMAND] [ARG…]】,運行時會替換 CMD 的默認值。因此這裏的 -i 替換了原來的 CMD,而不是添加在原來的 curl -s ifconfig.io 後面。而 -i 根本不是命令,所以自然找不到。
那麼如果我們希望加入 -i 這參數,我們就必須重新完整的輸入這個命令:
$ docker run myip curl -s ifconfig.io -i
這顯然不是很好的解決方案,而使用 ENTRYPOINT 就可以解決這個問題。現在我們重新用 ENTRYPOINT 來實現這個鏡像:
1 FROM centos:7.7.1908 2 ENTRYPOINT [ "curl", "-s", "ifconfig.io" ]
使用 docker build -t myip2 . 構建完成后,這次我們再來嘗試直接使用 docker run myip2 -i:
1 $ docker run myip2 2 183.226.75.148 3 4 $ docker run myip2 -i 5 HTTP/1.1 200 OK 6 Date: Sun, 19 Apr 2020 02:20:48 GMT 7 Content-Type: text/plain; charset=utf-8 8 Content-Length: 15 9 Connection: keep-alive 10 Set-Cookie: __cfduid=d76a2e007bbe7ec2d230b0a6636d115151587262848; expires=Tue, 19-May-20 02:20:48 GMT; path=/; domain=.ifconfig.io; HttpOnly; SameSite=Lax 11 CF-Cache-Status: DYNAMIC 12 Server: cloudflare 13 CF-RAY: 586326015c3199a1-LAX 14 alt-svc: h3-27=":443"; ma=86400, h3-25=":443"; ma=86400, h3-24=":443"; ma=86400, h3-23=":443"; ma=86400 15 cf-request-id: 0231d614d9000099a1e10d7200000001 16 17 183.226.75.148
可以看到,這次成功了。這是因為當存在 ENTRYPOINT 后,CMD 的內容將會作為參數傳給 ENTRYPOINT,而這裏 -i 就是新的 CMD,因此會作為參數傳給 curl,從而達到了我們預期的效果。
場景二:應用運行前的準備工作
啟動容器就是啟動主進程,但有些時候,啟動主進程前,需要一些準備工作。
比如 mysql 類的數據庫,可能需要一些數據庫配置、初始化的工作,這些工作要在最終的 mysql 服務器運行之前解決。
此外,可能希望避免使用 root 用戶去啟動服務,從而提高安全性,而在啟動服務前還需要以 root 身份執行一些必要的準備工作,最後切換到服務用戶身份啟動服務。或者除了服務外,其它命令依舊可以使用 root 身份執行,方便調試等。
這些準備工作是和容器 CMD 無關的,無論 CMD 是什麼,都需要事先進行一個預處理的工作。這種情況下,可以寫一個腳本,然後放入 ENTRYPOINT 中去執行,而這個腳本會將接到的參數(也就是 <CMD>)作為命令,在腳本最後執行。比如官方鏡像 redis 中就是這麼做的:
1 FROM alpine:3.4 2 ... 3 RUN addgroup -S redis && adduser -S -G redis redis 4 ... 5 ENTRYPOINT ["docker-entrypoint.sh"] 6 7 EXPOSE 6379 8 CMD [ "redis-server" ]
可以看到其中為了 redis 服務創建了 redis 用戶,並在最後指定了 ENTRYPOINT 為 docker-entrypoint.sh 腳本。
1 #!/bin/sh 2 ... 3 # allow the container to be started with `--user` 4 if [ "$1" = 'redis-server' -a "$(id -u)" = '0' ]; then 5 chown -R redis . 6 exec su-exec redis "$0" "$@" 7 fi 8 9 exec "$@"
該腳本的內容就是根據 CMD 的內容來判斷,如果是 redis-server 的話,則切換到 redis 用戶身份啟動服務器,否則依舊使用 root 身份執行。比如:
1 $ docker run -it redis id 2 uid=0(root) gid=0(root) groups=0(root)
CMD 容器啟動命令
CMD 指令的格式和 RUN 相似,也是兩種格式和一種特殊格式:
1 shell 格式:CMD <命令> 2 exec 格式:CMD ["可執行文件", "參數1", "參數2"...] 3 參數列表格式:CMD ["參數1", "參數2"...]。在指定了 ENTRYPOINT 指令后,用 CMD 指定具體的參數。
之前介紹容器的時候曾經說過,Docker 不是虛擬機,容器就是進程。既然是進程,那麼在啟動容器的時候,需要指定所運行的程序及參數。CMD 指令就是用於指定默認的容器主進程的啟動命令的。
在指令格式上,一般推薦使用 exec 格式,這類格式在解析時會被解析為 JSON 數組,因此一定要使用雙引號 “,而不要使用單引號。
如果使用 shell 格式的話,實際的命令會被包裝為 sh -c 的參數的形式進行執行。比如:
CMD echo $HOME
在實際執行中,會將其變更為:
CMD [ "sh", "-c", "echo $HOME" ]
這就是為什麼我們可以使用環境變量的原因,因為這些環境變量會被 shell 進行解析處理。
提到 CMD 就不得不提容器中應用在前台執行和後台執行的問題。這是初學者常出現的一個混淆。
Docker 不是虛擬機,容器中的應用都應該以前台執行,而不是像虛擬機、物理機裏面那樣,用 systemd 去啟動後台服務,容器內沒有後台服務的概念。
對於容器而言,其啟動程序就是容器應用進程,容器就是為了主進程而存在的,主進程退出,容器就失去了存在的意義,從而退出,其它輔助進程不是它需要關心的東西。
一些初學者將 CMD 寫為:
CMD service nginx start
使用 service nginx start 命令,則是希望 upstart 來以後台守護進程形式啟動 nginx 服務。而剛才說了 CMD service nginx start 會被理解為 CMD [ “sh”, “-c”, “service nginx start”],因此主進程實際上是 sh。那麼當 service nginx start 命令結束后,sh 也就結束了,sh 作為主進程退出了,自然就會令容器退出。
正確的做法是直接執行 nginx 可執行文件,並且要求以前台形式運行。比如:
CMD ["nginx", "-g", "daemon off;"]
構建鏡像案例-Nginx
構建文件
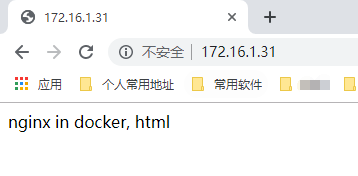
1 [root@docker01 make03]# pwd 2 /root/docker_test/make03 3 [root@docker01 make03]# ll 4 total 12 5 -rw-r--r-- 1 root root 720 Apr 19 16:46 Dockerfile 6 -rw-r--r-- 1 root root 95 Apr 19 16:19 entrypoint.sh 7 -rw-r--r-- 1 root root 22 Apr 19 16:18 index.html 8 [root@docker01 make03]# cat Dockerfile # Dockerfile文件 9 # 基礎鏡像 10 FROM centos:7.7.1908 11 12 # 維護者 13 MAINTAINER lightzhang lightzhang@xxx.com 14 15 # 命令:做了些什麼操作 16 RUN echo 'nameserver 223.5.5.5' > /etc/resolv.conf && echo 'nameserver 223.6.6.6' >> /etc/resolv.conf 17 RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo && curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo 18 RUN yum install -y nginx-1.16.1 && yum clean all 19 RUN echo "daemon off;" >> /etc/nginx/nginx.conf 20 21 # 添加文件 22 COPY index.html /usr/share/nginx/html/index.html 23 COPY entrypoint.sh /usr/local/bin/entrypoint.sh 24 25 # 對外暴露端口聲明 26 EXPOSE 80 27 28 # 執行 29 ENTRYPOINT ["sh", "entrypoint.sh"] 30 31 # 執行命令 32 CMD ["nginx"] 33 34 [root@docker01 make03]# cat index.html # 訪問文件 35 nginx in docker, html 36 [root@docker01 make03]# cat entrypoint.sh # entrypoint 文件 37 #!/bin/bash 38 if [ "$1" = 'nginx' ]; then 39 exec nginx -c /etc/nginx/nginx.conf 40 fi 41 exec "$@"
構建鏡像
1 [root@docker01 make03]# docker build -t base/nginx:1.16.1 . 2 Sending build context to Docker daemon 4.608kB 3 Step 1/11 : FROM centos:7.7.1908 4 ---> 08d05d1d5859 5 Step 2/11 : MAINTAINER lightzhang lightzhang@xxx.com 6 ---> Using cache 7 ---> 1dc29e78d94f 8 Step 3/11 : RUN echo 'nameserver 223.5.5.5' > /etc/resolv.conf && echo 'nameserver 223.6.6.6' >> /etc/resolv.conf 9 ---> Using cache 10 ---> 19398ad9b023 11 Step 4/11 : RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo && curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo 12 ---> Using cache 13 ---> b2451c5856c5 14 Step 5/11 : RUN yum install -y nginx-1.16.1 && yum clean all 15 ---> Using cache 16 ---> 291f27cae4df 17 Step 6/11 : RUN echo "daemon off;" >> /etc/nginx/nginx.conf 18 ---> Using cache 19 ---> 115e07b6313e 20 Step 7/11 : COPY index.html /usr/share/nginx/html/index.html 21 ---> Using cache 22 ---> 9d714d2e2a84 23 Step 8/11 : COPY entrypoint.sh /usr/local/bin/entrypoint.sh 24 ---> Using cache 25 ---> b16983911b56 26 Step 9/11 : EXPOSE 80 27 ---> Using cache 28 ---> d8675d6c2d43 29 Step 10/11 : ENTRYPOINT ["sh", "entrypoint.sh"] 30 ---> Using cache 31 ---> 802a1a67db37 32 Step 11/11 : CMD ["nginx"] 33 ---> Using cache 34 ---> f2517b4d5510 35 Successfully built f2517b4d5510 36 Successfully tagged base/nginx:1.16.1
發布容器與端口查看
1 [root@docker01 ~]# docker run -d -p 80:80 --name mynginx_v2 base/nginx:1.16.1 # 啟動容器 2 50a45a0894d8669308de7c70d47c96db8cd8990d3e34d1d125e5289ed062f126 3 [root@docker01 ~]# 4 [root@docker01 ~]# docker ps 5 CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 6 50a45a0894d8 base/nginx:1.16.1 "sh entrypoint.sh ng…" 3 minutes ago Up 3 minutes 0.0.0.0:80->80/tcp mynginx_v2 7 [root@docker01 ~]# netstat -lntup # 端口查看 8 Active Internet connections (only servers) 9 Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name 10 tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1634/master 11 tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1/systemd 12 tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1349/sshd 13 tcp6 0 0 ::1:25 :::* LISTEN 1634/master 14 tcp6 0 0 :::111 :::* LISTEN 1/systemd 15 tcp6 0 0 :::80 :::* LISTEN 13625/docker-proxy 16 tcp6 0 0 :::8080 :::* LISTEN 2289/docker-proxy 17 tcp6 0 0 :::22 :::* LISTEN 1349/sshd 18 udp 0 0 0.0.0.0:1021 0.0.0.0:* 847/rpcbind 19 udp 0 0 0.0.0.0:111 0.0.0.0:* 1/systemd 20 udp6 0 0 :::1021 :::* 847/rpcbind 21 udp6 0 0 :::111 :::* 1/systemd
瀏覽器訪問
http://172.16.1.31/
———END———
如果覺得不錯就關注下唄 (-^O^-) !
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化

 沙耶武里水壩即將完工。照片來源:
沙耶武里水壩即將完工。照片來源:  沙耶武里水壩開發前的地景樣貌。照片來源: (CC BY 2.0)
沙耶武里水壩開發前的地景樣貌。照片來源: (CC BY 2.0)