現在隨着各種數據庫框架的盛行,在提高效率的同時也讓我們忽略了很多底層的連接過程,這篇文章是對 SQL 連接過程梳理,並涉及到了現在常用的 SQL 標準。
其實標準就是在不同的時間,制定的一些寫法或規範。
從 SQL 標準說起
在編寫 SQL 語句前,需要先了解在不同版本的規範,因為隨着版本的變化,在具體編寫 SQL 時會有所不同。對於 SQL 來說,SQL92 和 SQL99 是最常見的兩個 SQL 標準,92 和 99 對應其提出的年份。除此之外,還存在 SQL86、SQL89、SQL2003、SQL2008、SQL2011,SQL2016等等。
但對我們來說,SQL92 和 SQL99 是最常用的兩個標準,主要學習這兩個就可以了。
為了演示方便,現在數據庫中加入如下三張表:
每個學生屬於一個班級,通過班級的人數來對應班級的類型。
-- ----------------------------
DROP TABLE IF EXISTS `Student`;
CREATE TABLE `Student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL DEFAULT '',
`birth` varchar(20) NOT NULL DEFAULT '',
`sex` varchar(10) NOT NULL DEFAULT '',
`class_id` int(11) NOT NULL COMMENT '班級ID',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of Student
-- ----------------------------
INSERT INTO `Student` VALUES ('1', '胡一', '1994.1.1', '男', '1');
INSERT INTO `Student` VALUES ('3', '王阿', '1992.1.1', '女', '1');
INSERT INTO `Student` VALUES ('5', '王琦', '1993.1.2', '男', '1');
INSERT INTO `Student` VALUES ('7', '劉偉', '1998.2.2', '女', '1');
INSERT INTO `Student` VALUES ('11', '張使', '1994.1.1', '男', '3');
INSERT INTO `Student` VALUES ('13', '王阿', '1992.1.1', '女', '3');
INSERT INTO `Student` VALUES ('15', '夏琪', '1993.1.2', '男', '3');
INSERT INTO `Student` VALUES ('17', '劉表', '1998.2.2', '女', '3');
INSERT INTO `Student` VALUES ('19', '諸葛', '1994.1.1', '男', '3');
INSERT INTO `Student` VALUES ('21', '王前', '1992.1.1', '女', '3');
INSERT INTO `Student` VALUES ('23', '王意識', '1993.1.2', '男', '3');
INSERT INTO `Student` VALUES ('25', '劉等待', '1998.2.2', '女', '3');
INSERT INTO `Student` VALUES ('27', '胡是一', '1994.1.1', '男', '5');
INSERT INTO `Student` VALUES ('29', '王阿請', '1992.1.1', '女', '5');
INSERT INTO `Student` VALUES ('31', '王消息', '1993.1.2', '男', '5');
INSERT INTO `Student` VALUES ('33', '劉全', '1998.2.2', '女', '5');
INSERT INTO `Student` VALUES ('35', '胡愛', '1994.1.1', '男', '5');
INSERT INTO `Student` VALUES ('37', '王表', '1992.1.1', '女', '5');
INSERT INTO `Student` VALUES ('39', '王華', '1993.1.2', '男', '5');
INSERT INTO `Student` VALUES ('41', '劉偉以', '1998.2.2', '女', '5');
INSERT INTO `Student` VALUES ('43', '胡一彪', '1994.1.1', '男', '5');
INSERT INTO `Student` VALUES ('45', '王阿符', '1992.1.1', '女', '5');
INSERT INTO `Student` VALUES ('47', '王琦刪', '1993.1.2', '男', '5');
INSERT INTO `Student` VALUES ('49', '劉達達', '1998.2.2', '女', '5');
-- ----------------------------
-- Table structure for `Class`
-- ----------------------------
DROP TABLE IF EXISTS `Class`;
CREATE TABLE `Class` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL DEFAULT '',
`number` int(11) NOT NULL DEFAULT '',
`class_type_id` int(11) NOT NULL COMMENT '班級類型ID',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of Class
-- ----------------------------
INSERT INTO `Class` VALUES ('1', '1年1班', 4, '1');
INSERT INTO `Class` VALUES ('3', '1年2班', 8, '3');
INSERT INTO `Class` VALUES ('5', '1年3班', 12, '5');
CREATE TABLE `ClassType`(
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) NOT NULL DEFAULT '',
`minimum_number` int(11) NOT NULL DEFAULT '' COMMENT '最少的班級人數',
`maximum_number` int(11) NOT NULL DEFAULT '' COMMENT '最多的班級人數',
PRIMARY KEY(`id`)
);
INSERT INTO `ClassType` VALUES ('1', '小班', '1', '4');
INSERT INTO `ClassType` VALUES ('3', '中班', '5', '8');
INSERT INTO `ClassType` VALUES ('5', '大班', '9', '12');
SQL92
笛卡爾積(交叉連接)
笛卡爾積是一個數學上的概念,表示如果存在 X,Y 兩個集合,則 X,Y 的笛卡爾積記為 X * Y. 表示由 X,Y 組成有序對的所有情況。
對應在 SQL 中,就是將兩張表中的每一行進行組合。而且在連接時,可以沒有任何限制,可將沒有關聯關係的任意表進行連接。
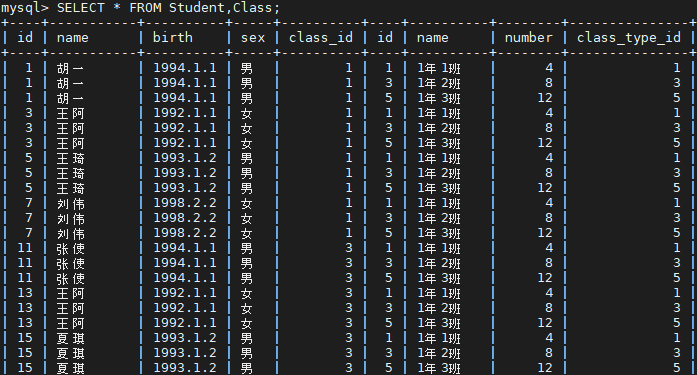
這裏拿學生表和班級表舉例,在學生表中我們插入了20名學生的數據,課程表中插入三個班級。則學生和班級的笛卡爾結果就是將兩表的每行數據一一組合,最後就是有 24 * 3 = 72 行的結果,如下圖所示。
並且需要知道的是,下面學習的外連接,自連接,等值連接等都是在笛卡爾積的基礎上篩選得到的。
對應的 SQL92 寫法為:
select * from Student, Class;
等值連接(內連接)
等值連接就是將兩張表中都存在的列進行連接,具體來說就是 where 後面通過 = 進行篩選。
比如查詢 Student 和其所屬 Class 信息的關係:
SELECT * FROM Student as s, Class as c where s.class_id = c.id;
非等值連接
非等值連接就是將等值連接中的等號換成其他的過濾條件。
比如這裏查詢每個班級的信息以及所屬的班級類別。
SELECT * FROM Class as c, ClassType t where c.number between t.minimum_number and maximum_number;
外連接
對於 SQL92 的外連接來說,在連接時會將兩張表分為主表和從表,主表显示所有的數據,從表显示匹配到的數據,沒有匹配到的則显示 None. 用 + 表示從表的位置。
左外連接:左表是主表,右表時從表。
SELECT * FROM Student as s , Class as c where s.class_id = c.id(+);
右外連接:左表是從表,右表時主表。
SELECT * FROM Class as c, Student as s where c.id = s.class_id(+);
注意 SQL92 中並沒有全外連接。
自連接
自連接一般用於連接本身這張表,由於常見的 DBMS 都會對自連接做一些優化,所以一般在子查詢和自連接的情況下都使用自連接。
比如想要查詢比1年1班人數多的班級:
子查詢:
SELECT * FROM Class WHERE number > (SELECT number FROM Class WHERE name="1年1班");
自連接:
SELECT c2.* FROM Class c1, Class c2 WHERE c1.number < c2.number and c1.name = "1年1班";
SQL99
交叉連接
SELECT * FROM Student CROSS JOIN Class;
還可以對多張表進行交叉連接,比如連接 Student,Class,ClassType 三張表,結果為 24 * 3 * 3 = 216 條。
相當於嵌套了三層 for 循環。
自然連接
其實就是 SQL92 中的等值連接,只不過連接的對象是具有相同列名,並且值也相同的內容。
SELECT * FROM Student NATURAL JOIN CLASS;
SELECT * FROM Student as s, Class as c where s.id = c.id;
如果想用 NATURAL JOIN 時,建議為兩表設置相同的列名,比如 Student 表中的班級列為 class_id, 則在 Class 表中,id 也應改為 class_id. 這樣連接更合理一些。
如果大家嘗試,自然連接的話,會發現查出來的結果集為空,不要奇怪,下面說一下原因:
這是因為,NATURAL JOIN 會自動連接兩張表中相同的列名,而對於 Student 和 Class 兩張表來說,id 和 name 在這兩張表都是相同的,所以既滿足 id 又滿足 name 的行是不存在的。
相當於 SQL 變成了這樣
SELECT * FROM Student as s, Class as c where s.id = c.id and s.name = c.name;
ON 連接
ON 連接其實對了 SQL92 中的等值連接和非等值連接:
等值連接:
SELECT * FROM Student as s JOIN Class as c ON s.class_id = c.id;
or
SELECT * FROM Student as s INNER JOIN Class as c ON s.class_id = c.id;
非等值連接:
SELECT * FROM Class as c JOIN ClassType t ON c.number between t.minimum_number and maximum_number;
USING 連接
和 NATURAL JOIN 很像,可以手動指定具有相同列名的列進行連接:
SELECT * FROM Student JOIN Class USING(id);
這時就解決了之前列存在重名,無法連接的情況。
外連接
左外連接: 左表是主表,右表時從表。
SELECT * FROM Student as s LEFT JOIN Class as c on s.class_id = c.id;
OR
SELECT * FROM Student as s LEFT OUTER JOIN Class as c on s.class_id = c.id;
右外連接:左表是從表,右表時主表。
SELECT * FROM Student as s RIGHT JOIN Class as c on s.class_id = c.id;
OR
SELECT * FROM Student as s RIGHT OUTER JOIN Class as c on s.class_id = c.id;
全外連接: 左外連接 + 右外的連接的合集
SELECT * FROM Student as s FULL JOIN Class as c ON s.class_id = c.id;
MySQL 中沒有全外連接的概念。
自連接:
SELECT c2.* FROM Class c1 JOIN Class c2 ON c1.number < c2.number and c1.name = "1年1班";
SQL92 和 SQL99 的對比
-
SQL92 中的等值連接(內連接),非等值連接,自連接對應了 SQL99 的 ON 連接,用於篩選滿足連接條件的數據行。
-
SQL92 的笛卡爾積連接,對應了 SQL99 的交叉連接。
-
SQL92 中的外連接並不包含全外連接,而 SQL99 支持,並且將 SQL92 中 WHERE 換為 SQL99 的 ON. 這樣的好處可以更清晰的表達連接表的過程,更直觀。
SELECT ... FROM table1 JOIN table2 ON filter_condition JOIN table3 ON filter_condition -
SQL99 多了自然連接和 USING 連接的過程,兩者的區別是是否需要顯式的指定列名。
總結
我們知道,在 SQL 中,按照年份劃分了不同的標準,其中最為常用的是 SQL-92 和 SQL-99 兩個標準。
接着,對比了 92 和 99 兩者的不同,發現 99 的標準在連接時,更加符合邏輯並且更加直觀。
最後,上一張各種連接的示意圖, 方便梳理複習:
參考
各種連接的不同
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準