文:李翊僑(荷蘭馬斯垂克大學永續科學、政策與社會碩士生)
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
摘錄自2019年12月13日中央社報導
台灣不是巴黎氣候協定的締約國,仍積極參加聯合國氣候會議。代表台灣參與的環保署長張子敬表示,今年與各國官員的互動比往年多,不過,台灣減碳作為仍有不足的地方。
聯合國氣候變化綱要公約(UNFCCC)第25次締約方會議(COP 25)2日至13日在西班牙首都馬德里舉行,外交部旗下的國際合作發展基金會、交通部中央氣象局、經濟部工業局、工業技術研究院、行政院農業委員會、媽媽監督核電廠聯盟等機關和團體利用會議期間在周邊會議發聲。
張子敬在馬德里接受中央社記者訪問時表示,雖然無法進入大會會場,不過在場外與各國官員的互動比往年都多。除了邦交國,他也與歐盟、英國、瑞典、德國等國代表會晤,各國對台灣對抗氣候變遷的作法相當重視,台灣也樂於幫助需要幫助的國家。
此外,張子敬還接受在地的「ABC日報」等媒體專訪,說明台灣的能源和減碳政策,以及為何因為中國的壓力,無法參與這次的氣候會議。
張子敬表示,在減碳的作為上,台灣仍有許多不足之處。首先,台灣十分依賴進口化石能源,每度電的碳排量過高,住商、農業和交通部門的減碳都有待加強。
其次,除了建立碳交易制度,落實總量管制,張子敬也支持徵收碳稅,「使用者付費本來就應該」。他說,環保署在水污染防治有許多經驗,未來碳稅的收入將專款專用,用來減少碳排。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※別再煩惱如何寫文案,掌握八大原則!
全球電動車市場持續成長,直接刺激鋰電池與電動馬達等相關零組件的需求量。台灣、中國兩岸廠商積極針對電動車進行投資布局,但局勢因策略與市場的不同而有所差異。
中國投資額高,但潛藏不穩定性
中國是目前全球電動車市場成長速度最快的國家之一,但今年首季因補貼政策所造成的不確定性,使電動車銷量比去年同期暴跌九成。
不少中國地方政府將電動車與新能源車列為新興產業投資鼓勵對象,也吸引了大筆投資。據統計,2015年至今,中國大陸各地規劃或已展開建設的新能源汽車建設專案超過30個,總投資額超過人民幣1,000億元,呈現遍地開花的局勢。
但《經濟日報》引述中國媒體指出,上述專案多以「新能源汽車產業圈」的形式存在,看似投資新能源車,實際上是為了恢復原有的汽車產能。部分電動車生產企業甚至已進入停產狀態,未來若無法改善,可能會被強制退市。
雖然中國電動車相關投資積極,但卻有泡沫化的隱憂。
台電池廠投入國際電動車市場
相較之下,台灣長泓能源科技、宏境科技對電動車產業的佈局較為穩健,且也更為注重其他海外市場。
長泓能源科技與台灣車廠、客運業者合作,推動電動大巴專案,目標搶下台灣政府10年內投入1萬輛電動大巴的政策。同時,長泓已與特斯拉的移動式20kWh儲能系統、台塑汽車啟動電池等展開測試合作,積極步入電池組裝領域。
長泓能源科技董事長陳明德表示,公司強化氧化鋰鐵電池的產品性能與應用整合,安全性高,且有機會搶攻中國大陸電動車市場。
另一方面,宏境科技已取得美國電動沙灘巡邏車電池組的1,000輛訂單,同時與某汽車通路商合作,打入中國大陸NEXT EV油電混和車馬達控制器供應鏈,數量可望超過一萬輛。宏境科技也已取得中瑞電動車每年550輛的動力鋰電池組訂單,每年可貢獻約1億元新台幣營收。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑

由中國汽車工程研究院、英納威-俄羅斯聖彼德堡國立技術大學中俄功能材料新能源技術研究院支援,上海領研商務諮詢有限公司主辦「2016 第二屆 亞太新能源汽車國際峰會」於6月2-3日在北京萬豪酒店隆重召開,來自相關政府部門、整車企業、行業機構、新能源汽車關鍵零部件供應商,智慧網聯汽車關鍵零部件企業,先進輕量化材料及解決方案企業,諮詢公司,工程開發公司,檢測認證機構,高校科研院所及投資公司等150余名行業代表蒞臨現場,分享交流新能源汽車產業政策及未來發展趨勢、新能源汽車動力總成及輕量化技術、整車集成及動力電池技術、先進智慧網聯及無線充電技術等。
 |
| 2016ANEVS會議現場 |
第一天上午來自權威行業機構,知名諮詢公司及整車廠的發言嘉賓和大家分享了新能源汽車產業政策及未來發展趨勢:
中國內燃機工業協會副秘書長魏安力以應對第四階段乘用車油耗法規的節能技術路線分析,在分析國家能源安全及大氣污染控制的背景下,闡述了現階段混合動力技術是當前國內汽車節能減排的最佳技術路徑選擇。
貝恩公司的全球合夥人戴加輝先生,就全球新能源汽車市場發展趨勢和挑戰發表了精彩的演講,重點介紹了國內外汽車電氣化發展中存在的挑戰,純電動和插電式混合動力及動力電池發展現狀及趨勢等。
來自北汽集團的新能源汽車管理部部長詹文章博士以北汽集團新能源汽車發展戰略和實踐發表主題演講,分享了北汽集團未來新能源汽車發展技術和戰略規劃以及電氣化和智慧網聯及輕量化技術融合發展趨勢。
吉利汽車研究院總工程師熊飛博士,就新能源汽車輕量化技術開發與落地發表演講,重點介紹了應用于吉利新能源汽車的先進輕量化技術及未來發展規劃。
特斯拉汽車中國區公共政策與充電基礎設施總監的高翔先生,就高性能智慧互聯電動汽車-清潔交通的革新發表演講,著重闡述了特斯拉汽車在電氣化和智慧互聯技術融合方面的發展經驗。
來自奇瑞汽車的副總裁兼動力總成技術中心執行總監韓爾樑先生,就最有競爭力的奇瑞動力系統研發發表主題演講,和大家分享了奇瑞未來新能源汽車動力系統發展規劃,特別重點宣導發展燃料電池汽車的研發和技術儲備。
德國國際合作機構的Markus Wagner先生,就電動交通和可再生能源在德國的能源經濟型效應及發展現狀發表演講,介紹了德國在可再生能源和電動交通協同發展的經驗。
來自羅蘭貝格的高級項目經理鄭贇先生就全球智慧網聯汽車市場發展趨勢和挑戰發表演講,系統介紹了國內外智慧網聯汽車的發展現狀和存在的挑戰,還特別介紹了羅蘭貝格關於汽車電氣化和輕量化技術融合發展的最新研究成果。
第二天,針對汽車電氣化和智慧化,網聯化及智慧化技術融合,會議的部分演講嘉賓介紹了最新的技術解決方案:
來自吉凱恩傳動系統的中國區工程技術支援總監克裡澌汀·高熙先生,就應用於新能源汽車的先進變速器技術發表演講,重點介紹和展示了應用于寶馬、三菱、富豪及保時捷等新能源汽車的變速器和傳動系統解決方案。
來自能啟能電子的技術總監徐向陽先生,就新能源汽車火情預警及控制策略發表演講,重點介紹和展示了他們目前所做的對新能源汽車電池熱失控的早期預警、智慧判斷、提前干預和主動滅火等研究。
來自諾貝麗斯的中國區董事總經理劉清先生,就全鋁車身在新能源汽車中輕量化應用的最新發展發表演講,重點介紹了全鋁車身對於新能源汽車的重要性及全鋁車身汽車的閉合循環系統。
來自東軟睿馳的副總經理曹斌先生,就新能源汽車動力電池安全方面的思考及研發發表演講,重點介紹了PACK電池包、BMS電池管理系統及ICS等在新能源汽車的應用及安全的解決方案。
來自地平線機器人科技的業務拓展總監李星宇先生,就深度學習為自動駕駛帶來的全新突破發表演講,重點介紹了自動駕駛的演算法、晶片、系統集成三方面。
更多關於發言嘉賓詳細演講資料,請關注微信公眾號:領研GIIAutomotive

本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※別再煩惱如何寫文案,掌握八大原則!
F-立凱公告將與五龍動力、香港上市公司五龍電動車集團簽訂三方交易契約,共同深化電動車產業的上、下游布局,著眼爭取中國乃至於全球的電動車市場。
根據協議,三方將以策略聯盟、資本合作的方式取得股權轉換方案。契約載明,五龍動力將以每股新台幣35元的價格取得立凱電新發行的普通股,佔增資後股本21.8%;思慕完成後,五龍電動車集團在另外以1億港幣(約新台幣4.2億)現金取得立凱電旗下車電事業部門──立凱綠能(蓋曼)股權,以及台灣立凱綠能的部分資產。交易完成後,五龍動力與五龍電動車集團預計將投資凱電超過新台幣20億元。
此外,立凱電同時將以每股0.5元港幣的價格認購五龍電動車集團新發行之430萬普通股與2.75億元港幣的無擔保可轉換公司債,總投資額預計將達港幣4.9億元,並成為五龍電動車集團股東。此舉將幫助立凱電正式邁入中國電動車市場。
F-立凱由尹衍樑投資,為電動巴士系統與磷酸鐵鋰電池正極材料廠商。與五龍動力、五龍電動車集團的交易完成後,將在兩岸三地與國際市場進行明確產業分工,由立凱電繼續投入正極材料研發、製造與銷售,同時為五龍動力提供LFP-NCO奈米金屬氧化物共晶體化磷酸鋰鐵電池正極材料M系列產品的生產與技術顧問服務。三方也將合作於中國建立材料廠,以因應未來中國電動車龐大的材料需求。
此外,台灣立凱綠能也將與五龍電動車在電池芯、電池模組以及電動車技術等領域合作,同時不忘繼續拓展台灣電動巴士業務。F-立凱表示,本次策略聯盟,將可幫助F-立凱、五龍動力、五龍電動車集團、立凱電整合技術、製造、市場、供應鏈與資金,全面進軍中國與全球的儲能市場和電動車市場。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
美國電動車大廠特斯拉(Tesla)公佈第 2 季財報,凈虧損為 1.843 億美元,而因車輛銷售持續攀高,營收成長 24%,達到 9.55 億美元,但與去年同期的凈虧損 1.542 億美元相比有所擴大,且一年內第二度下修銷售預測。 特斯拉表示,今年交車目標為 5 萬至 5.5 萬輛之間。去年執行長穆斯克發下豪語,說今年的銷售量將達 6 萬輛,今年稍早已調降到 5.5 萬輛,如今再度下修。不過,特斯拉仍預期今年 9 月底這款車將開始「少量交車」,但進度就算只延後一周,整體產量就會減少約 800 輛。 特斯拉上季資本支出總計 4.052 億美元,主要是持續用在 Model X 新車,以及預定 2016 年開幕的內華達州電池新廠。今年上半年的總支出達 8.312 億美元,預估全年支出約為 15 億美元。經調整後特斯拉上季每股虧損 48 美分,優於分析師預估的每股虧損 60 美分,去年同期則是每股獲利 13 美分。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※別再煩惱如何寫文案,掌握八大原則!
流式編程作為Java 8的亮點之一,是繼Java 5之後對集合的再一次升級,可以說Java 8幾大特性中,Streams API 是作為Java 函數式的主角來設計的,誇張的說,有了Streams API之後,萬物皆可一行代碼。
Stream被翻譯為流,它的工作過程像將一瓶水導入有很多過濾閥的管道一樣,水每經過一個過濾閥,便被操作一次,比如過濾,轉換等,最後管道的另外一頭有一個容器負責接收剩下的水。
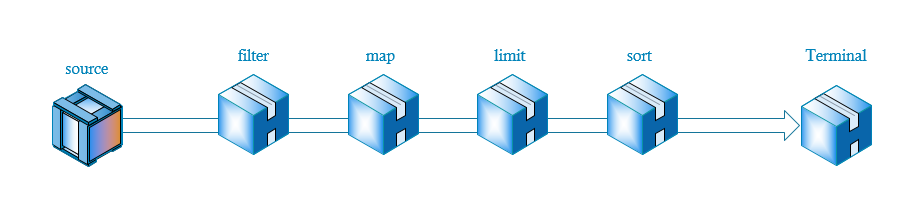
示意圖如下:
首先通過source產生流,然後依次通過一些中間操作,比如過濾,轉換,限制等,最後結束對流的操作。
Stream也可以理解為一個更加高級的迭代器,主要的作用便是遍歷其中每一個元素。
Stream作為Java 8的一大亮點,它專門針對集合的各種操作提供各種非常便利,簡單,高效的API,Stream API主要是通過Lambda表達式完成,極大的提高了程序的效率和可讀性,同時Stram API中自帶的并行流使得併發處理集合的門檻再次降低,使用Stream API編程無需多寫一行多線程的大門就可以非常方便的寫出高性能的併發程序。使用Stream API能夠使你的代碼更加優雅。
流的另一特點是可無限性,使用Stream,你的數據源可以是無限大的。
在沒有Stream之前,我們想提取出所有年齡大於18的學生,我們需要這樣做:
List<Student> result=new ArrayList<>();
for(Student student:students){
if(student.getAge()>18){
result.add(student);
}
}
return result;使用Stream,我們可以參照上面的流程示意圖來做,首先產生Stream,然後filter過濾,最後歸併到容器中。
轉換為代碼如下:
return students.stream().filter(s->s.getAge()>18).collect(Collectors.toList());stream()獲得流filter(s->s.getAge()>18)過濾collect(Collectors.toList())歸併到容器中是不是很像在寫sql?
我們可以發現,當我們使用一個流的時候,主要包括三個步驟:
獲取流的方式有多種,對於常見的容器(Collection)可以直接.stream()獲取
例如:
Collection.stream()Collection.parallelStream()Arrays.stream(T array) or Stream.of()對於IO,我們也可以通過lines()方法獲取流:
java.nio.file.Files.walk()java.io.BufferedReader.lines()最後,我們還可以從無限大的數據源中產生流:
Random.ints()值得注意的是,JDK中針對基本數據類型的昂貴的裝箱和拆箱操作,提供了基本數據類型的流:
IntStreamLongStreamDoubleStream這三種基本數據類型和普通流差不多,不過他們流裏面的數據都是指定的基本數據類型。
Intstream.of(new int[]{1,2,3});
Intstream.rang(1,3);這是本章的重點,產生流比較容易,但是不同的業務系統的需求會涉及到很多不同的要求,明白我們能對流做什麼,怎麼做,才能更好的利用Stream API的特點。
流的操作類型分為兩種:
Intermediate:中間操作,一個流可以後面跟隨零個或多個intermediate操作。其目的主要是打開流,做出某種程度的數據映射/過濾,然後會返回一個新的流,交給下一個操作使用。這類操作都是惰性化的(lazy),就是說,僅僅調用到這類方法,並沒有真正開始流的遍歷。
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
Terminal:終結操作,一個流只能有一個terminal操作,當這個操作執行后,流就被使用“光”了,無法再被操作。所以這必定是流的最後一個操作。Terminal操作的執行,才會真正開始流的遍歷,並且會生成一個結果,或者一個 side effect。
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
Intermediate和Terminal完全可以按照上圖的流程圖理解,Intermediate表示在管道中間的過濾器,水會流入過濾器,然後再流出去,而Terminal操作便是最後一個過濾器,它在管道的最後面,流入Terminal的水,最後便會流出管道。
下面依次詳細的解讀下每一個操作所能產生的效果:
對於中間操作,所有的API的返回值基本都是Stream<T>,因此以後看見一個陌生的API也能通過返回值判斷它的所屬類型。
map/flatMap
map顧名思義,就是映射,map操作能夠將流中的每一個元素映射為另外的元素。
<R> Stream<R> map(Function<? super T, ? extends R> mapper);可以看到map接受的是一個Function,也就是接收參數,並返回一個值。
比如:
//提取 List<Student> 所有student 的名字
List<String> studentNames = students.stream().map(Student::getName)
.collect(Collectors.toList());上面的代碼等同於以前的:
List<String> studentNames=new ArrayList<>();
for(Student student:students){
studentNames.add(student.getName());
}再比如:將List中所有字母轉換為大寫:
List<String> words=Arrays.asList("a","b","c");
List<String> upperWords=words.stream().map(String::toUpperCase)
.collect(Collectors.toList());flatMap顧名思義就是扁平化映射,它具體的操作是將多個stream連接成一個stream,這個操作是針對類似多維數組的,比如容器裡面包含容器等。
List<List<Integer>> ints=new ArrayList<>(Arrays.asList(Arrays.asList(1,2),
Arrays.asList(3,4,5)));
List<Integer> flatInts=ints.stream().flatMap(Collection::stream).
collect(Collectors.toList());可以看到,相當於降維。
filter
filter顧名思義,就是過濾,通過測試的元素會被留下來並生成一個新的Stream
Stream<T> filter(Predicate<? super T> predicate);同理,我們可以filter接收的參數是Predicate,也就是推斷型函數式接口,接收參數,並返回boolean值。
比如:
//獲取所有大於18歲的學生
List<Student> studentNames = students.stream().filter(s->s.getAge()>18)
.collect(Collectors.toList());distinct
distinct是去重操作,它沒有參數
Stream<T> distinct();sorted
sorted排序操作,默認是從小到大排列,sorted方法包含一個重載,使用sorted方法,如果沒有傳遞參數,那麼流中的元素就需要實現Comparable<T>方法,也可以在使用sorted方法的時候傳入一個Comparator<T>
Stream<T> sorted(Comparator<? super T> comparator);
Stream<T> sorted();值得一說的是這個Comparator在Java 8之後被打上了@FunctionalInterface,其他方法都提供了default實現,因此我們可以在sort中使用Lambda表達式
例如:
//以年齡排序
students.stream().sorted((s,o)->Integer.compare(s.getAge(),o.getAge()))
.forEach(System.out::println);;然而還有更方便的,Comparator默認也提供了實現好的方法引用,使得我們更加方便的使用:
例如上面的代碼可以改成如下:
//以年齡排序
students.stream().sorted(Comparator.comparingInt(Student::getAge))
.forEach(System.out::println);;或者:
//以姓名排序
students.stream().sorted(Comparator.comparing(Student::getName)).
forEach(System.out::println);是不是更加簡潔。
peek
peek有遍歷的意思,和forEach一樣,但是它是一个中間操作。
peek接受一個消費型的函數式接口。
Stream<T> peek(Consumer<? super T> action);例如:
//去重以後打印出來,然後再歸併為List
List<Student> sortedStudents= students.stream().distinct().peek(System.out::println).
collect(Collectors.toList());limit
limit裁剪操作,和String::subString(0,x)有點先溝通,limit接受一個long類型參數,通過limit之後的元素只會剩下min(n,size)個元素,n表示參數,size表示流中元素個數
Stream<T> limit(long maxSize);例如:
//只留下前6個元素並打印
students.stream().limit(6).forEach(System.out::println);skip
skip表示跳過多少個元素,和limit比較像,不過limit是保留前面的元素,skip是保留後面的元素
Stream<T> skip(long n);例如:
//跳過前3個元素並打印
students.stream().skip(3).forEach(System.out::println);一個流處理中,有且只能有一個終結操作,通過終結操作之後,流才真正被處理,終結操作一般都返回其他的類型而不再是一個流,一般來說,終結操作都是將其轉換為一個容器。
forEach
forEach是終結操作的遍歷,操作和peek一樣,但是forEach之後就不會再返迴流
void forEach(Consumer<? super T> action);例如:
//遍歷打印
students.stream().forEach(System.out::println);上面的代碼和一下代碼效果相同:
for(Student student:students){
System.out.println(sudents);
}toArray
toArray和List##toArray()用法差不多,包含一個重載。
默認的toArray()返回一個Object[],
也可以傳入一個IntFunction<A[]> generator指定數據類型
一般建議第二種方式。
Object[] toArray();
<A> A[] toArray(IntFunction<A[]> generator);例如:
Student[] studentArray = students.stream().skip(3).toArray(Student[]::new);max/min
max/min即使找出最大或者最小的元素。max/min必須傳入一個Comparator。
Optional<T> min(Comparator<? super T> comparator);
Optional<T> max(Comparator<? super T> comparator);count
count返迴流中的元素數量
long count();例如:
long count = students.stream().skip(3).count();reduce
reduce為歸納操作,主要是將流中各個元素結合起來,它需要提供一個起始值,然後按一定規則進行運算,比如相加等,它接收一個二元操作 BinaryOperator函數式接口。從某種意義上來說,sum,min,max,average都是特殊的reduce
reduce包含三個重載:
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);例如:
List<Integer> integers = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
long count = integers.stream().reduce(0,(x,y)->x+y);以上代碼等同於:
long count = integers.stream().reduce(Integer::sum).get();reduce兩個參數和一個參數的區別在於有沒有提供一個起始值,
如果提供了起始值,則可以返回一個確定的值,如果沒有提供起始值,則返回Opeational防止流中沒有足夠的元素。
anyMatch allMatch noneMatch
測試是否有任意元素\所有元素\沒有元素匹配表達式
他們都接收一個推斷類型的函數式接口:Predicate
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate)例如:
boolean test = integers.stream().anyMatch(x->x>3);findFirst、 findAny
獲取元素,這兩個API都不接受任何參數,findFirt返迴流中第一個元素,findAny返迴流中任意一個元素。
Optional<T> findFirst();
Optional<T> findAny();也有有人會問
findAny()這麼奇怪的操作誰會用?這個API主要是為了在并行條件下想要獲取任意元素,以最大性能獲取任意元素
例如:
int foo = integers.stream().findAny().get();collect
collect收集操作,這個API放在後面將是因為它太重要了,基本上所有的流操作最後都會使用它。
我們先看collect的定義:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);可以看到,collect包含兩個重載:
一個參數和三個參數,
三個參數我們很少使用,因為JDK提供了足夠我們使用的Collector供我們直接使用,我們可以簡單了解下這三個參數什麼意思:
Supplier:用於產生最後存放元素的容器的生產者accumulator:將元素添加到容器中的方法combiner:將分段元素全部添加到容器中的方法前兩個元素我們都很好理解,第三個元素是幹嘛的呢?因為流提供了并行操作,因此有可能一個流被多個線程分別添加,然後再將各個子列表依次添加到最終的容器中。
↓ – – – – – – – – –
↓ — — —
↓ ———
如上圖,分而治之。
例如:
List<String> result = stream.collect(ArrayList::new, List::add, List::addAll);接下來看只有一個參數的collect
一般來說,只有一個參數的collect,我們都直接傳入Collectors中的方法引用即可:
List<Integer> = integers.stream().collect(Collectors.toList());Collectors中包含很多常用的轉換器。toList(),toSet()等。
Collectors中還包括一個groupBy(),他和Sql中的groupBy一樣都是分組,返回一個Map
例如:
//按學生年齡分組
Map<Integer,List<Student>> map= students.stream().
collect(Collectors.groupingBy(Student::getAge));
groupingBy可以接受3個參數,分別是
- 第一個參數:分組按照什麼分類
- 第二個參數:分組最後用什麼容器保存返回(當只有兩個參數是,此參數默認為
HashMap)- 第三個參數:按照第一個參數分類后,對應的分類的結果如何收集
有時候單參數的
groupingBy不滿足我們需求的時候,我們可以使用多個參數的groupingBy
例如:
//將學生以年齡分組,每組中只存學生的名字而不是對象
Map<Integer,List<String>> map = students.stream().
collect(Collectors.groupingBy(Student::getAge,Collectors.mapping(Student::getName,Collectors.toList())));toList默認生成的是ArrayList,toSet默認生成的是HashSet,如果想要指定其他容器,可以如下操作:
students.stream().collect(Collectors.toCollection(TreeSet::new));Collectors還包含一個toMap,利用這個API我們可以將List轉換為Map
Map<Integer,Student> map=students.stream().
collect(Collectors.toMap(Student::getAge,s->s));
值得注意的一點是,
IntStream,LongStream,DoubleStream是沒有collect()方法的,因為對於基本數據類型,要進行裝箱,拆箱操作,SDK並沒有將它放入流中,對於基本數據類型流,我們只能將其toArray()
了解了Stream API,下面詳細介紹一下如果優雅的使用Steam
了解流的惰性操作
前面說到,流的中間操作是惰性的,如果一個流操作流程中只有中間操作,沒有終結操作,那麼這個流什麼都不會做,整個流程中會一直等到遇到終結操作操作才會真正的開始執行。
例如:
students.stream().peek(System.out::println);這樣的流操作只有中間操作,沒有終結操作,那麼不管流裡面包含多少元素,他都不會執行任何操作。
明白流操作的順序的重要性
在Stream API中,還包括一類Short-circuiting,它能夠改變流中元素的數量,一般這類API如果是中間操作,最好寫在靠前位置:
考慮下面兩行代碼:
students.stream().sorted(Comparator.comparingInt(Student::getAge)).
peek(System.out::println).
limit(3).
collect(Collectors.toList());students.stream().limit(3).
sorted(Comparator.comparingInt(Student::getAge)).
peek(System.out::println).
collect(Collectors.toList());兩段代碼所使用的API都是相同的,但是由於順序不同,帶來的結果都非常不一樣的,
第一段代碼會先排序所有的元素,再依次打印一遍,最後獲取前三個最小的放入list中,
第二段代碼會先截取前3個元素,在對這三個元素排序,然後遍歷打印,最後放入list中。
明白Lambda的局限性
由於Java目前只能Pass-by-value,因此對於Lambda也和有匿名類一樣的final的局限性。
具體原因可以參考
因此我們無法再lambda表達式中修改外部元素的值。
同時,在Stream中,我們無法使用break提前返回。
合理編排Stream的代碼格式
由於可能在使用流式編程的時候會處理很多的業務邏輯,導致API非常長,此時最後使用換行將各個操作分離開來,使得代碼更加易讀。
例如:
students.stream().limit(3).
sorted(Comparator.comparingInt(Student::getAge)).
peek(System.out::println).
collect(Collectors.toList());而不是:
students.stream().limit(3).sorted(Comparator.comparingInt(Student::getAge)).peek(System.out::println).collect(Collectors.toList());同時由於Lambda表達式省略了參數類型,因此對於變量,盡量使用完成的名詞,比如student而不是s,增加代碼的可讀性。
盡量寫出敢在代碼註釋上留下你的名字的代碼!
總之,Stream是Java 8 提供的簡化代碼的神器,合理使用它,能讓你的代碼更加優雅。
尊重勞動成功,轉載註明出處
參考鏈接:
《Effective Java》3th
如果覺得寫得不錯,歡迎關注微信公眾號:逸游Java ,每天不定時發布一些有關Java乾貨的文章,感謝關注
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
人的說話頻率基本上為300Hz~3400Hz,但是人耳朵聽覺頻率基本上為20Hz~20000Hz。
對於人類的語音信號而言,實際處理一般經過以下步驟:
人嘴說話——>聲電轉換——>抽樣(模數轉換)——>量化(將数字信號用適當的數值表示)——>編碼(數據壓縮)——>
傳輸(網絡或者其他方式)
——> 解碼(數據還原)——>反抽樣(數模轉換)——>電聲轉換——>人耳聽聲。
實際中,人發出的聲音信號為模擬信號,想要在實際中處理必須為数字信號,即採用抽樣、量化、編碼的處理方案。
處理的第一步為抽樣,即模數轉換。
簡單地說就是通過波形採樣的方法記錄1秒鐘長度的聲音,需要多少個數據。
根據奈魁斯特(NYQUIST)採樣定理,用兩倍於一個正弦波的頻繁率進行採樣就能完全真實地還原該波形。
所以,對於聲音信號而言,要想對離散信號進行還原,必須將抽樣頻率定為40KHz以上。實際中,一般定為44.1KHz。
44.1KHz採樣率的聲音就是要花費44000個數據來描述1秒鐘的聲音波形。
原則上採樣率越高,聲音的質量越好,採樣頻率一般共分為22.05KHz、44.1KHz、48KHz三個等級。
22.05 KHz只能達到FM廣播的聲音品質,44.1KHz則是理論上的CD音質界限,48KHz則已達到DVD音質了。
對於音頻信號而言,實際上必須進行編碼。在這裏,編碼指信源編碼,即數據壓縮。如果,未經過數據壓縮,直接量化進行傳輸則被稱為PCM(脈衝編碼調製)。
要算一個PCM音頻流的碼率是一件很輕鬆的事情,採樣率值×採樣大小值×聲道數 bps。
一個採樣率為44.1KHz,採樣大小為16bit,雙聲道的PCM編碼的WAV文件,它的數據速率則為 44.1K×16×2 =1411.2 Kbps。
我們常說128K的MP3,對應的WAV的參數,就是這個1411.2 Kbps,這個參數也被稱為數據帶寬,它和ADSL中的帶寬是一個概念。將碼率除以8,就可以得到這個WAV的數據速率,即176.4KB/s。這表示存儲一秒鐘採樣率為44.1KHz,採樣大小為16bit,雙聲道的PCM編碼的音頻信號,需要176.4KB的空間,1分鐘則約為10.34M,這對大部分用戶是不可接受的,尤其是喜歡在電腦上聽音樂的朋友,要降低磁盤佔用
只有2種方法,
降低採樣指標或者壓縮。降低指標是不可取的,因此專家們研發了各種壓縮方案。最原始的有DPCM、ADPCM,其中最出名的為MP3。所以,採用了數據壓縮以後的碼率遠小於原始碼率。
音頻播放器,錄音機,語音電話,音視頻監控應用,音視頻直播應用,音頻編輯/處理軟件,藍牙耳機/音箱,等等。
(1)音頻採集/播放
(2)音頻算法處理(去噪、靜音檢測、回聲消除、音效處理、功放/增強、混音/分離,等等)
(3)音頻的編解碼和格式轉換
(4)音頻傳輸協議的開發(SIP,A2DP、AVRCP,等等)
延時敏感、卡頓敏感、噪聲抑制(Denoise)、回聲消除(AEC)、靜音檢測(VAD)、混音算法,等等。
在音頻開發中,下面的這幾個概念經常會遇到。
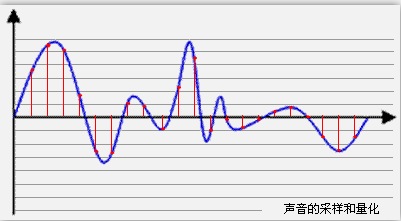
採樣就是把模擬信號数字化的過程,不僅僅是音頻需要採樣,所有的模擬信號都需要通過採樣轉換為可以用0101來表示的数字信號,示意圖如下所示:
藍色代表模擬音頻信號,紅色的點代表採樣得到的量化數值。
採樣頻率越高,紅色的間隔就越密集,記錄這一段音頻信號所用的數據量就越大,同時音頻質量也就越高。
根據奈奎斯特理論,採樣頻率只要不低於音頻信號最高頻率的兩倍,就可以無損失地還原原始的聲音。
通常人耳能聽到頻率範圍大約在20Hz~20kHz之間的聲音,為了保證聲音不失真,採樣頻率應在40kHz以上。常用的音頻採樣頻率有:8kHz、11.025kHz、22.05kHz、16kHz、37.8kHz、44.1kHz、48kHz、96kHz、192kHz等。
對採樣率為44.1kHz的AAC音頻進行解碼時,一幀的解碼時間須控制在23.22毫秒內。
通常是按1024個採樣點一幀
分析:
一個AAC原始幀包含某段時間內1024個採樣點相關數據。
用1024主要是因為AAC是用的1024點的mdct。
音頻幀的播放時間=一個AAC幀對應的採樣樣本的個數/採樣頻率(單位為s)
採樣率(samplerate)為 44100Hz,表示每秒 44100個採樣點,
所以,根據公式,
音頻幀的播放時長 = 一個AAC幀對應的採樣點個數 / 採樣頻率
則,當前一幀的播放時間 = 1024 * 1000/44100= 23.22 ms(單位為ms)
48kHz採樣率,
則,當前一幀的播放時間 = 1024 * 1000/48000= 21.333ms(單位為ms)
22.05kHz採樣率,
則,當前一幀的播放時間 = 1024 * 1000/22050= 46.439ms(單位為ms)
mp3 每幀均為1152個字節,
則:
每幀播放時長 = 1152 * 1000 / sample_rate
例如:sample_rate = 44100HZ時,
計算出的時長為26.122ms,
這就是經常聽到的mp3每幀播放時間固定為26ms的由來。
上圖中,每一個紅色的採樣點,都需要用一個數值來表示大小,這個數值的數據類型大小可以是:4bit、8bit、16bit、32bit等等,位數越多,表示得就越精細,聲音質量自然就越好,當然,數據量也會成倍增大。
常見的位寬是:8bit 或者 16bit
由於音頻的採集和播放是可以疊加的,因此,可以同時從多個音頻源採集聲音,並分別輸出到不同的揚聲器,故聲道數一般表示聲音錄製時的音源數量或回放時相應的揚聲器數量。
單聲道(Mono)和雙聲道(Stereo)比較常見,顧名思義,前者的聲道數為1,後者為2
是用於測量显示幀數的量度。所謂的測量單位為每秒显示幀數(Frames per Second,簡稱:FPS)或“赫茲”(Hz)。
音頻跟視頻很不一樣,視頻每一幀就是一張圖像,而從上面的正玄波可以看出,音頻數據是流式的,本身沒有明確的一幀幀的概念,在實際的應用中,為了音頻算法處理/傳輸的方便,一般約定俗成取2.5ms~60ms為單位的數據量為一幀音頻。
這個時間被稱之為“採樣時間”,其長度沒有特別的標準,它是根據編×××和具體應用的需求來決定的,我們可以計算一下一幀音頻幀的大小:
假設某通道的音頻信號是採樣率為8kHz,位寬為16bit,20ms一幀,雙通道,則一幀音頻數據的大小為:
int size = 8000 x 16bit x 0.02s x 2 = 5120 bit = 640 byte
上面提到過,模擬的音頻信號轉換為数字信號需要經過採樣和量化,量化的過程被稱之為編碼,根據不同的量化策略,產生了許多不同的編碼方式,常見的編碼方式有:PCM 和 ADPCM,這些數據代表着無損的原始数字音頻信號,添加一些文件頭信息,就可以存儲為WAV文件了,它是一種由微軟和IBM聯合開發的用於音頻数字存儲的標準,可以很容易地被解析和播放。
我們在音頻開發過程中,會經常涉及到WAV文件的讀寫,以驗證採集、傳輸、接收的音頻數據的正確性。
首先簡單介紹一下音頻數據壓縮的最基本的原理:因為有冗餘信息,所以可以壓縮。
(1) 頻譜掩蔽效應: 人耳所能察覺的聲音信號的頻率範圍為20Hz~20KHz,在這個頻率範圍以外的音頻信號屬於冗餘信號。
(2) 時域掩蔽效應: 當強音信號和弱音信號同時出現時,弱信號會聽不到,因此,弱音信號也屬於冗餘信號。
下面簡單列出常見的音頻壓縮格式:
MP3,AAC,OGG,WMA,Opus,FLAC,APE,m4a,AMR,等等
imsdroid,sipdroid,csipsimple,linphone,WebRTC 等等
speex、ffmpeg,webrtc audio module(NS、VAD、AECM、AGC),等等
音頻採集: MediaRecoder,AudioRecord
音頻播放: SoundPool,MediaPlayer,AudioTrack
音頻編解碼: MediaCodec
NDK API: OpenSL ES
ITU-TG.114規定,對於高質量語音可接受的時延是300ms。一般來說,如果時延在300~400ms,通話的交互性比較差,但還可以接受。時延大於400ms時,則交互通信非常困難。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
日前,戴姆勒集團總裁迪特•蔡澈(Dieter Zetsche)稱,電動汽車一次充電必須能供應至少310英里(499公里)的行程,才能替代燃油汽車,成為主流。
但蔡澈在接受美國媒體採訪時稱,在短時期內讓所有消費者接受電動汽車不太可能,並稱這是一個連續的過程。首先要降低車載電池的成本。蔡澈估計該價格在170美元每千瓦時左右,而110-130美元則會使汽車很有競爭優勢。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
《華爾街日報》網站發表文章稱,幾個月前,Uber在拼車服務領域好像是勢不可擋的王者。但最近一系列事件,特別是蘋果向Uber頭號競爭對手投資10億美元,表明形勢已迅速發生變化。此前,Uber在世界各地陷入與監管機構的鬥爭,並努力平息其約100萬位司機隊伍的動盪;如今,它必須面對一家中國初創公司的挑戰,其支持者包括全球最大的電腦製造商、中國最大的互聯網公司和汽車製造巨頭等。
隨著蘋果的現金注入,中國的打車服務滴滴出行可能獲得蘋果龐大的技術和行銷資源,這將有助於其拓展數以百萬計的新用戶,在快速發展的交通領域開發下一代產品。
滴滴至少已經獲得50億美元的融資,證明它在資金籌集上可以與Uber的中國業務競爭。滴滴還擁有強大的中國合作夥伴,包括阿裡巴巴集團和騰訊等。在滴滴最近一輪融資中,它們將向該公司投入更多資金。消息人士表示,這輪融資對滴滴的估值為250億美元。滴滴的服務已與阿裡巴巴旗下的支付寶和騰訊的微信進行整合。
今年年初,Uber最大的美國競爭對手Lyft獲得了通用汽車的支持。通用汽車與Lyft合作,是為了佈局未來無人駕駛汽車領域的競爭。根據雙方合作協定,通用汽車將向Lyft投資5億美元。上周,這兩家公司宣佈,它們計畫明年開始測試無人駕駛電動計程車車隊。在最新一輪融資中,Lyft估值達到了55億美元。
Uber聯合創始人、CEO 特拉維斯•卡蘭尼克(Travis Kalanick) 習慣諷刺競爭對手。對於蘋果投資其競爭對手的消息,他週五在Twitter上發了一條消息稱,他的女友布持有iPhone製造商的股票,這使她成為他的競爭對手的間接投資人。他在這消息上加上了 “#ridesharewars”和“#thanksalottim” 標籤,指的是蘋果CEO蒂姆•庫克。
Uber通過債務和股權融資已募集100多億美元資金,最近估值達到625億美元。該公司正在全球範圍內建立合作同盟,從中國百度到印度媒體集團Bennett Coleman & Co都成為其合作夥伴。這些合作夥伴已分別幫助Uber在中國和印度擴張——卡蘭尼克向投資者強調這兩個市場是他的公司最大的擴張機會。
但在某些方面,Uber喜歡利用其資金來實現其競爭地位,而不是依賴于合作夥伴的幫助。去年,隨著蘋果和Alphabet等財大氣粗的科技巨頭加大對無人駕駛汽車研發的投入,該公司從卡內基•梅隆大學挖來了40位世界頂級機器人技術研究人員和科學家,並在匹茲堡一個新的技術中心啟動了自己的無人駕駛汽車項目。
Uber與其它公司的合作夥伴關係之一充滿了變數。2013年,Alphabet旗下風投公司Google Ventures向Uber投資了2.5億美元,這是其當時單筆最大投資。但自那以後,穀歌開始測試自己的打車應用,而Uber開始開發自己的地圖和無人駕駛汽車技術,顯然在與穀歌的競爭。不過,Alphabet高級副總裁大衛•德拉蒙德(David Drummond)仍然是Uber的董事會成員。
Uber採取“自己去做”的策略,與其競爭對手之間不斷擴大合作形成鮮明對比。去年,滴滴向Lyft投資10億美元,如今它們的合作夥伴關係已演變成一個涉及多方的國際聯盟。滴滴和Lyft已將它們的應用捆綁在一起,使中國遊客到美國可以使用Lyft的應用叫車,反之亦然。在未來幾個月內,印度的Ola和新加坡的GrabTaxi Holdings Pte. Ltd計畫推出類似功能。
Uber在中國市場已處於下風,而蘋果的投資會讓其競爭對手更為強大。為吸引中國拼車服務市場的使用者和投資者,Uber在中國的子公司UberChina與滴滴陷入激烈競爭。滴滴和UberChina都爭相從本地投資者籌集數十億美元的資金,利用現金補貼的舉措爭取司機和乘客使用他們的服務。
與蘋果的交易可能加強滴滴的技術研發實力。該公司已成立一個名為“滴滴研究院”的研發中心,專注於機器學習、人工智慧和資料採擷等領域。
文章來源:網易科技
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!