作者簡介
Vyacheslav,擁有運維和項目管理經驗的軟件工程師
這篇文章將承接我此前搭建的本地Docker開發環境,具體步驟已經放在在以下網址:
https://github.com/Voronenko/traefik2-compose-template
除了經典的docker化的項目之外,我還有其他的Kubernetes項目。儘管Kubernetes已經成為容器編排的事實標準,但是不得不承認Kubernetes是一個既消耗資源又消耗金錢的平台。由於我並不經常需要外部集群,因此我使用輕量級K3s發行版來進行Kubernetes本地開發。
K3s是為IoT和邊緣計算而構建的經過認證的Kubernetes發行版之一,還能夠按產品規模部署到VM。
我使用K3s的方式是這樣的:在我的工作筆記本上本地安裝K3s,儘管有時我需要在本地部署較重的測試工作負載,為此,我準備了兩個神器——兩個運行ESXi的外部Intel NUCs。
默認情況下,K3s安裝Traefik 1.x作為ingress,如果你對此十分滿意,那麼無需往下繼續閱讀了。
在我的場景中,我同時會牽涉到好幾個項目,特別是經典的docker和docker swarm,因此我經常遇到在獨立模式下部署Traefik的情況。
因此,本文其餘部分將深入介紹如何將外部traefik2配置為K3s集群的ingress。
安裝Kubernetes K3s系列集群
你可以按照常規方式使用命令curl -sfL https://get.k3s.io | sh -安裝K3s,或者你可以使用輕量實用程序k3sup安裝(https://github.com/alexellis/k3sup)。具體步驟在之前的文章介紹過。
與我們的設置不同的是,我們使用命令--no-deploy traefik專門安裝了不帶traefik組件的K3s。
export CLUSTER_MASTER=192.168.3.100
export CLUSTER_DEPLOY_USER=slavko
k3sup install --ip $CLUSTER_MASTER --user $CLUSTER_DEPLOY_USER --k3s-extra-args '--no-deploy traefik'
執行后,你將獲得使用kubectl所需的連接詳細信息。安裝K3s后,你可以快速檢查是否可以看到節點。
# Test your cluster with - export path to k3s cluster kubeconfig:
export KUBECONFIG=/home/slavko/kubeconfig
kubectl get node -o wide
注:這裏沒有固定的安裝模式,你甚至可以使用docker-compose自行啟動它。
server:
image: rancher/k3s:v0.8.0
command: server --disable-agent --no-deploy traefik
environment:
- K3S_CLUSTER_SECRET=somethingtotallyrandom
- K3S_KUBECONFIG_OUTPUT=/output/kubeconfig.yaml
- K3S_KUBECONFIG_MODE=666
volumes:
# k3s will generate a kubeconfig.yaml in this directory. This volume is mounted
# on your host, so you can then 'export KUBECONFIG=/somewhere/on/your/host/out/kubeconfig.yaml',
# in order for your kubectl commands to work.
- /somewhere/on/your/host/out:/output
# This directory is where you put all the (yaml) configuration files of
# the Kubernetes resources.
- /somewhere/on/your/host/in:/var/lib/rancher/k3s/server/manifests
ports:
- 6443:6443
node:
image: rancher/k3s:v0.8.0
privileged: true
links:
- server
environment:
- K3S_URL=https://server:6443
- K3S_CLUSTER_SECRET=somethingtotallyrandom
volumes:
# this is where you would place a alternative traefik image (saved as a .tar file with
# 'docker save'), if you want to use it, instead of the traefik:v2.0 image.
- /sowewhere/on/your/host/custom-image:/var/lib/rancher/k3s/agent/images
配置Traefik 2,與Kubernetes一起使用
在文章開頭提到的鏈接中,我已經在我的系統中安裝了Traefik 2,並根據該鏈接內容,服務於一些需求。現在是時候配置Traefik 2 Kubernetes後端了。
Traefik 2使用CRD(自定義資源定義)來完成這一點。定義的最新示例可以在以下鏈接中找到,但這些示例僅適用於Traefik 2也作為Kubernetes工作負載的一部分執行的情況:
https://docs.traefik.io/reference/dynamic-configuration/kubernetes-crd/
對於外部Traefik 2,我們僅需要以下描述的定義子集。
我們引入一系列自定義資源定義,以允許我們來描述我們的Kubernetes服務將會如何暴露到外部,traefik-crd.yaml:
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: ingressroutes.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: IngressRoute
plural: ingressroutes
singular: ingressroute
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: ingressroutetcps.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: IngressRouteTCP
plural: ingressroutetcps
singular: ingressroutetcp
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: middlewares.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: Middleware
plural: middlewares
singular: middleware
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: tlsoptions.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: TLSOption
plural: tlsoptions
singular: tlsoption
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: traefikservices.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: TraefikService
plural: traefikservices
singular: traefikservice
scope: Namespaced
同時,我們需要集群角色traefik-ingress-controller,以提供對服務、端點和secret的只讀訪問權限以及自定義的traefik.containo.us組,traefik-clusterrole.yaml:
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: traefik-ingress-controller
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- secrets
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses/status
verbs:
- update
- apiGroups:
- traefik.containo.us
resources:
- middlewares
verbs:
- get
- list
- watch
- apiGroups:
- traefik.containo.us
resources:
- ingressroutes
verbs:
- get
- list
- watch
- apiGroups:
- traefik.containo.us
resources:
- ingressroutetcps
verbs:
- get
- list
- watch
- apiGroups:
- traefik.containo.us
resources:
- tlsoptions
verbs:
- get
- list
- watch
- apiGroups:
- traefik.containo.us
resources:
- traefikservices
verbs:
- get
- list
- watch
最後,我們需要系統服務賬號traefik-ingress-controller與之前創建的集群角色traefik-ingress-controller相關聯。
---
kind: ServiceAccount
apiVersion: v1
metadata:
namespace: kube-system
name: traefik-ingress-controller
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: traefik-ingress-controller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: traefik-ingress-controller
subjects:
- kind: ServiceAccount
name: traefik-ingress-controller
namespace: kube-system
我們應用以上資源之後:
apply:
kubectl apply -f traefik-crd.yaml
kubectl apply -f traefik-clusterrole.yaml
kubectl apply -f traefik-service-account.yaml
我們已經準備好開始調整Traefik 2
將Traefik 2指向K3s集群
根據Traefik文檔的建議,當Traefik部署到Kubernetes中時,它將讀取環境變量KUBERNETES_SERVICE_HOST和KUBERNETES_SERVICE_PORT或KUBECONFIG來構造端點。
在/var/run/secrets/kubernetes.io/serviceaccount/token中查找訪問token,而SSL CA證書將在/var/run/secrets/kubernetes.io/serviceaccount/ca.crt.中查找。當部署到Kubernetes內部時,兩者都會自動提供掛載。
當無法找到環境變量時,Traefik會嘗試使用external-cluster客戶端連接到Kubernetes API server。這一情況下,需要設置endpoint。具體來說,可以將其設置為kubectl代理使用的URL,以使用相關的kubeconfig授予的身份驗證和授權連接到Kubernetes集群。
Traefik 2可以使用任何受支持的配置類型來靜態配置-toml、yaml或命令行交換。
[providers.kubernetesCRD]
endpoint = "http://localhost:8080"
token = "mytoken"
providers:
kubernetesCRD:
endpoint = "http://localhost:8080"
token = "mytoken"
# ...
--providers.kubernetescrd.endpoint=http://localhost:8080
--providers.kubernetescrd.token=mytoken
第一次運行時,如果你在外部有Traefik,很有可能沒有traefik-ingress-controller訪問token來指定mytoken。那麼,你需要執行以下命令:
# Check all possible clusters, as your .KUBECONFIG may have multiple contexts:
kubectl config view -o jsonpath='{"Cluster name\tServer\n"}{range .clusters[*]}{.name}{"\t"}{.cluster.server}{"\n"}{end}'
# Output kind of
# Alias tip: k config view -o jsonpath='{"Cluster name\tServer\n"}{range .clusters[*]}{.name}{"\t"}{.cluster.server}{"\n"}{end}'
# Cluster name Server
# default https://127.0.0.1:6443
# You are interested in: "default", if you did not name it differently
# Select name of cluster you want to interact with from above output:
export CLUSTER_NAME="default"
# Point to the API server referring the cluster name
export APISERVER=$(kubectl config view -o jsonpath="{.clusters[?(@.name==\"$CLUSTER_NAME\")].cluster.server}")
# usually https://127.0.0.1:6443
# Gets the token value
export TOKEN=$(kubectl get secrets -o jsonpath="{.items[?(@.metadata.annotations['kubernetes\.io/service-account\.name']=='traefik-ingress-controller')].data.token}" --namespace kube-system|base64 --decode)
# Explore the API with TOKEN
如果成功了,你應該收到以下響應:
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "192.168.3.100:6443"
}
]
以及一些事實,如token:
eyJhbGciOiJSUzI1NiIsImtpZCI6IjBUeTQyNm5nakVWbW5PaTRRbDhucGlPeWhlTHhxTXZjUDJsRmNacURjVnMifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJ0cmFlZmlrLWluZ3Jlc3MtY29udHJvbGxlci10b2tlbi12emM3diIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJ0cmFlZmlrLWluZ3Jlc3MtY29udHJvbGxlciIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImQ5NTc3ZTkxLTdlNjQtNGMwNi1iZDgyLWNkZTk0OWM4MTI1MSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTp0cmFlZmlrLWluZ3Jlc3MtY29udHJvbGxlciJ9.Mk8EBS4soO8uX-uSnV3o4qZKR6Iw6bgeSmPhHbJ2fjuqFgLnLh4ggxa-N9AqmCsEWiYjSi5oKAu986UEC-_kGQh3xaCYsUwlkM8147fsnwCbomSeGIct14JztVL9F8JwoDH6T0BOEjn-J9uY8-fUKYL_Y7uTrilhFapuILPsj_bFfgIeOOapRD0XshKBQV9Qzg8URxyQyfzl68ilm1Q13h3jLj8CFE2RlgEUFk8TqYH4T4fhfpvV-gNdmKJGODsJDI1hOuWUtBaH_ce9w6woC9K88O3FLKVi7fbvlDFrFoJ2iVZbrRALPjoFN92VA7a6R3pXUbKebTI3aUJiXyfXRQ
根據上次響應的API server的外部地址:https://192.168.3.100:6443
同樣,提供的token中沒有任何特殊之處:這是JWT的token,你可以使用https://jwt.io/#debugger-io,檢查它的內容。
{
"alg": "RS256",
"kid": "0Ty426ngjEVmnOi4Ql8npiOyheLxqMvcP2lFcZqDcVs"
}
{
"iss": "kubernetes/serviceaccount",
"kubernetes.io/serviceaccount/namespace": "kube-system",
"kubernetes.io/serviceaccount/secret.name": "traefik-ingress-controller-token-vzc7v",
"kubernetes.io/serviceaccount/service-account.name": "traefik-ingress-controller",
"kubernetes.io/serviceaccount/service-account.uid": "d9577e91-7e64-4c06-bd82-cde949c81251",
"sub": "system:serviceaccount:kube-system:traefik-ingress-controller"
}
正確的配置非常重要,因此請確保對APISERVER的兩個調用均返回合理的響應。
export APISERVER=YOURAPISERVER
export TOKEN=YOURTOKEN
curl -X GET $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
curl -X GET $APISERVER/api/v1/endpoints --header "Authorization: Bearer $TOKEN" --insecure
創建其他訪問token
控制器循環確保每個服務賬戶都有一個帶有API token的secret,可以像我們之前那樣被發現。
此外,你還可以為一個服務賬戶創建額外的token,創建一個ServiceAccountToken類型的secret,併為服務賬戶添加一個註釋,控制器會用生成的token來更新它。
---
apiVersion: v1
kind: Secret
namespace: kube-system
metadata:
name: traefik-manual-token
annotations:
kubernetes.io/service-account.name: traefik-ingress-controller
type: kubernetes.io/service-account-token
# Any tokens for non-existent service accounts will be cleaned up by the token controller.
# kubectl describe secrets/traefik-manual-token
用以下命令創建:
kubectl create -f ./traefik-service-account-secret.yaml
kubectl describe secret traefik-manual-token
刪除/無效:
kubectl delete secret traefik-manual-token
對外部traefik 2的更改構成定義
我們需要在文章開頭給出的鏈接中獲得的traefik2配置進行哪些更改?
https://github.com/Voronenko/traefik2-compose-template
a) 我們在新文件夾kubernetes_data中存儲ca.crt文件,該文件用於驗證對Kubernetes授權的調用。這是可以在kubeconfig文件的clusters-> cluster-> certificate-authority-data下找到的證書。
該volume將映射在/var/run/secrets/kubernetes.io/serviceaccount下以獲取官方Traefik 2鏡像
volumes:
...
- ./kubernetes_data:/var/run/secrets/kubernetes.io/serviceaccount
b) 調整Traefik 2 kubernetescrd後端以提供3個參數:endpoint、證書路徑和token。請注意,作為外部Traefik作為docker容器,你需要指定正確的endpoint地址,並確保以安全的方式進行。
- "--providers.kubernetescrd=true"
- "--providers.kubernetescrd.endpoint=https://192.168.3.100:6443"
- "--providers.kubernetescrd.certauthfilepath=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt"
- "--providers.kubernetescrd.token=YOURTOKENWITHOUTANYQUOTES
如果你都執行正確了,那麼你現在應該在Traefik UI上看到了一些希望。如果你沒有看到traefik,或者在運行Traefik時有問題,你可以查看之後的故障排除部分。
現在是時候通過Trafik 2暴露一些Kubernetes服務了,以確保Traefik 2能夠作為ingress工作。讓我們來看經典案例whoami服務,whoami-service.yaml
apiVersion: v1
kind: Service
metadata:
name: whoami
spec:
ports:
- protocol: TCP
name: web
port: 80
selector:
app: whoami
---
kind: Deployment
apiVersion: apps/v1
metadata:
namespace: default
name: whoami
labels:
app: whoami
spec:
replicas: 2
selector:
matchLabels:
app: whoami
template:
metadata:
labels:
app: whoami
spec:
containers:
- name: whoami
image: containous/whoami
ports:
- name: web
containerPort: 80
並且以http或https的方式暴露它,whoami.k.voronenko.net全限定域名下的whoami-ingress-route.yaml。
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: ingressroute-notls
namespace: default
spec:
entryPoints:
- web
routes:
- match: Host(`whoami.k.voronenko.net`)
kind: Rule
services:
- name: whoami
port: 80
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: ingressroute-tls
namespace: default
spec:
entryPoints:
- websecure
routes:
- match: Host(`whoami.k.voronenko.net`)
kind: Rule
services:
- name: whoami
port: 80
tls:
certResolver: default
然後應用它:
kubectl apply -f whoami-service.yaml
kubectl apply -f whoami-ingress-route.yaml
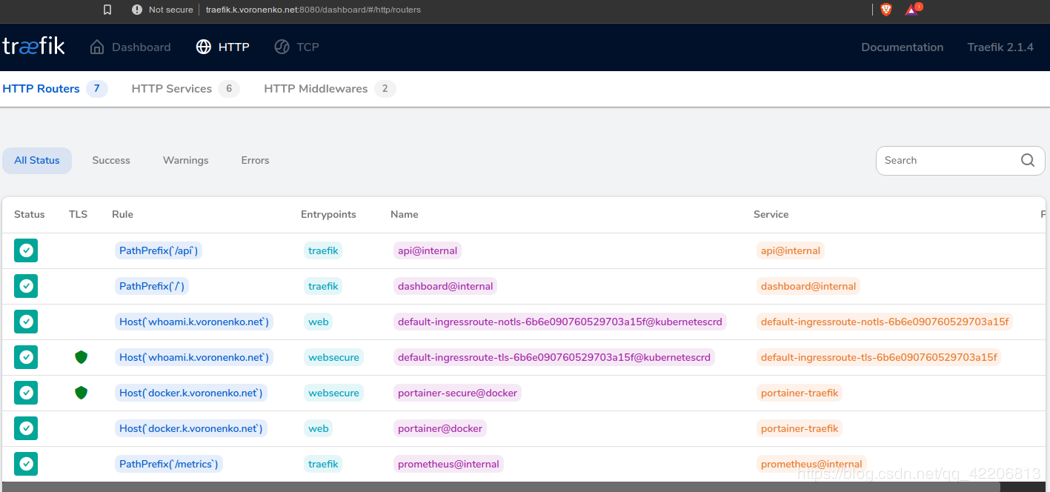
應用后,你應該會在Traefik dashboard上看到一些希望,即KubernetesCRD後端。
正如你所看到的,Traefik已經檢測到我們的K3s Kubernetes集群上運行的新工作負載,而且它與我們在同一個盒子上的經典Docker工作負載(如portainer)很好地共存。
讓我們檢查一下Traefik 2是否將Traefik路由到了我們的Kubernetes工作負載:如你所見,你可以在http和https endpoint上成功地接觸到whoami工作負載,瀏覽器接受你的證書為可信任的“綠標籤”。
我們的目標達到了!我們在本地筆記本上配置了Traefik 2。Traefik 2將你的docker或Kubernetes工作流暴露在http或https endpoint上。帶可選的 letsencrypt 的 Traefik 2 將負責 https。
故障排查
正如你所知,在配置過程可能存在多個問題,你可以考慮使用一些分析工具,如:
https://github.com/Voronenko/dotfiles/blob/master/Makefile#L185
我特別建議:
a) VMWare octant:這是一個基於Web的功能強大的Kubernetes dashboard,你可以在上面使用你的kubeconfig
b) Rakess:這是一個獨立工具也是一個kubectl插件,用於显示Kubernetes服務器資源的訪問矩陣(https://github.com/corneliusweig/rakkess)
檢查系統賬戶的憑據
rakkess --sa kube-system:traefik-ingress-controller
c) kubectl
檢查哪些角色與服務賬戶相關聯
kubectl get clusterrolebindings -o json | jq -r '
.items[] |
select(
.subjects // [] | .[] |
[.kind,.namespace,.name] == ["ServiceAccount","kube-system","traefik-ingress-controller"]
) |
.metadata.name'
d) Traefik 文檔:例如kubernetescrd後端提供了更多配置開關的方式。
--providers.kubernetescrd (Default: "false")
Enable Kubernetes backend with default settings.
--providers.kubernetescrd.certauthfilepath (Default: "")
Kubernetes certificate authority file path (not needed for in-cluster client).
--providers.kubernetescrd.disablepasshostheaders (Default: "false")
Kubernetes disable PassHost Headers.
--providers.kubernetescrd.endpoint (Default: "")
Kubernetes server endpoint (required for external cluster client).
--providers.kubernetescrd.ingressclass (Default: "")
Value of kubernetes.io/ingress.class annotation to watch for.
--providers.kubernetescrd.labelselector (Default: "")
Kubernetes label selector to use.
--providers.kubernetescrd.namespaces (Default: "")
Kubernetes namespaces.
--providers.kubernetescrd.throttleduration (Default: "0")
Ingress refresh throttle duration
--providers.kubernetescrd.token (Default: "")
Kubernetes bearer token (not needed for in-cluster client).
--providers.kubernetesingress (Default: "false")
Enable Kubernetes backend with default settings.
--providers.kubernetesingress.certauthfilepath (Default: "")
Kubernetes certificate authority file path (not needed for in-cluster client).
--providers.kubernetesingress.disablepasshostheaders (Default: "false")
Kubernetes disable PassHost Headers.
--providers.kubernetesingress.endpoint (Default: "")
Kubernetes server endpoint (required for external cluster client).
--providers.kubernetesingress.ingressclass (Default: "")
Value of kubernetes.io/ingress.class annotation to watch for.
--providers.kubernetesingress.ingressendpoint.hostname (Default: "")
Hostname used for Kubernetes Ingress endpoints.
--providers.kubernetesingress.ingressendpoint.ip (Default: "")
IP used for Kubernetes Ingress endpoints.
--providers.kubernetesingress.ingressendpoint.publishedservice (Default: "")
Published Kubernetes Service to copy status from.
--providers.kubernetesingress.labelselector (Default: "")
Kubernetes Ingress label selector to use.
--providers.kubernetesingress.namespaces (Default: "")
Kubernetes namespaces.
--providers.kubernetesingress.throttleduration (Default: "0")
Ingress refresh throttle duration
--providers.kubernetesingress.token (Default: "")
Kubernetes bearer token (not needed for in-cluster client).
e) 確保Traefik有足夠的權限可以訪問apiserver endpoint
如果你希望Traefik為你查詢信息:通過在配置中放置一些錯誤的apiserver地址,可以查看訪問的endpoint和查詢順序。有了這些知識和你的Traefik Kubernetes token,你就可以使用Traefik憑證檢查這些endpoint是否可以訪問。
traefik_1 | E0421 12:30:12.624877 1 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20190718183610-8e956561bbf5/tools/cache/reflector.go:98: Failed to list *v1.Endpoints: Get https://192.168.3.101:6443/api/v1/endpoints?limit=500&resourceVersion=0:
traefik_1 | E0421 12:30:12.625341 1 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20190718183610-8e956561bbf5/tools/cache/reflector.go:98: Failed to list *v1.Service: Get https://192.168.3.101:6443/api/v1/services?limit=500&resourceVersion=0:
traefik_1 | E0421 12:30:12.625395 1 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20190718183610-8e956561bbf5/tools/cache/reflector.go:98: Failed to list *v1beta1.Ingress: Get https://192.168.3.101:6443/apis/extensions/v1beta1/ingresses?limit=500&resourceVersion=0:
traefik_1 | E0421 12:30:12.625449 1 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20190718183610-8e956561bbf5/tools/cache/reflector.go:98: Failed to list *v1alpha1.Middleware: Get https://192.168.3.101:6443/apis/traefik.containo.us/v1alpha1/middlewares?limit=500&resourceVersion=0:
traefik_1 | E0421 12:30:12.625492 1 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20190718183610-8e956561bbf5/tools/cache/reflector.go:98: Failed to list *v1alpha1.IngressRoute: Get https://192.168.3.101:6443/apis/traefik.containo.us/v1alpha1/ingressroutes?limit=500&resourceVersion=0:
traefik_1 | E0421 12:30:12.625531 1 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20190718183610-8e956561bbf5/tools/cache/reflector.go:98: Failed to list *v1alpha1.TraefikService: Get https://192.168.3.101:6443/apis/traefik.containo.us/v1alpha1/traefikservices?limit=500&resourceVersion=0:
traefik_1 | E0421 12:30:12.625572 1 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20190718183610-8e956561bbf5/tools/cache/reflector.go:98: Failed to list *v1alpha1.TLSOption: Get https://192.168.3.101:6443/apis/traefik.containo.us/v1alpha1/tlsoptions?limit=500&resourceVersion=0:
traefik_1 | E0421 12:30:12.625610 1 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20190718183610-8e956561bbf5/tools/cache/reflector.go:98: Failed to list *v1alpha1.IngressRouteTCP: Get https://192.168.3.101:6443/apis/traefik.containo.us/v1alpha1/ingressroutetcps?limit=500&resourceVersion=0:
f) 記錄K3s本身
安裝腳本將自動檢測你的操作系統是使用systemd還是openrc並啟動服務。使用openrc運行時,將在/var/log/k3s.log中創建日誌。使用systemd運行時,將在/var/log/syslog中創建日誌,並使用journalctl -u k3s查看。
在那裡,你可能會得到一些提示,例如:
кві 21 15:42:44 u18d k3s[612]: E0421 15:42:44.936960 612 authentication.go:104] Unable to authenticate the request due to an error: invalid bearer token
這將為你提供有關K8s Traefik起初使用時出現問題的線索,Enjoy your journey!
相關代碼你可以在以下鏈接中找到:
https://github.com/Voronenko/k3s-mini
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案