知識需要不斷積累、總結和沉澱,思考和寫作是成長的催化劑
梯子
一、任務Task
System.Threading.Tasks在.NET4引入,前麵線程的API太多了,控制不方便,而ThreadPool控制能力又太弱,比如做線程的延續、阻塞、取消、超時等功能不太方便,所以Task就抽象了線程功能,在後台使用ThreadPool
1、啟動任務
可以使用TaskFactory類或Task類的構造函數和Start()方法,委託可以提供帶有一個Object類型的輸入參數,所以可以給任務傳遞任意數據,還漏了一個常用的Task.Run
TaskFactory taskFactory = new TaskFactory();
taskFactory.StartNew(() =>
{
Console.WriteLine($"tid={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
});
Task.Factory.StartNew(() =>
{
Console.WriteLine($"tid={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
});
Task task = new Task(() =>
{
Console.WriteLine($"tid={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
});
task.Start();
只有Task類實例方式需要Start()去啟動任務,當然可以RunSynchronously()來同步執行任務,主線程會等待,就是用主線程來執行這個task任務
Task task = new Task(() =>
{
Thread.Sleep(10000);
Console.WriteLine($"tid={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
});
task.RunSynchronously();
2、阻塞延續
在Thread中我們使用join來阻塞等待,在多個Thread時進行控制就不太方便。Task中我們使用實例方法Wait阻塞單個任務或靜態方法WaitAll和WaitAny阻塞多個任務
var task = new Task(() =>
{
Thread.Sleep(5*1000);
Console.WriteLine($"tid={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
});
var task2 = new Task(() =>
{
Thread.Sleep(10 * 1000);
Console.WriteLine($"tid={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
});
task.Start();
task2.Start();
//task.Wait();//單任務等待
//Task.WaitAny(task, task2);//任何一個任務完成就繼續
Task.WaitAll(task, task2);//任務都完成才繼續
如果不希望阻塞主線程,實現當一個任務或幾個任務完成后執行別的任務,可以使用Task靜態方法WhenAll和WhenAny,他們將返回一個Task,但這個Task不允許你控制,將會在滿足WhenAll和WhenAny里任務完成時自動完成,然後調用Task的ContinueWith方法,就可以在一個任務完成后緊跟開始另一個任務
Task.WhenAll(task, task2).ContinueWith((t) =>
{
Console.WriteLine($"tid={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
});
Task.Factory工廠中也存在類似ContinueWhenAll和ContinueWhenAny
3、任務層次結構
不僅可以在一個任務結束后執行另一個任務,也可以在一個任務內啟動一個任務,這就啟動了一個父子層次結構
var parentTask = new Task(()=>
{
Console.WriteLine($"parentId={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
Thread.Sleep(5*1000);
var childTask = new Task(() =>
{
Thread.Sleep(10 * 1000);
Console.WriteLine($"childId={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}")
});
childTask.Start();
});
parentTask.Start();
如果父任務在子任務之前結束,父任務的狀態為WaitingForChildrenToComplete,當子任務也完成時,父任務的狀態就變為RanToCompletion,當然,在創建任務時指定TaskCreationOptions枚舉參數,可以控制任務的創建和執行的可選行為
4、枚舉參數
簡單介紹下創建任務中的TaskCreationOptions枚舉參數,創建任務時我們可以提供TaskCreationOptions枚舉參數,用於控制任務的創建和執行的可選行為的標誌
- AttachedToParent:指定將任務附加到任務層次結構中的某個父級,意思就是建立父子關係,父任務必須等待子任務完成才可以繼續執行。和WaitAll效果一樣。上面例子如果在創建子任務時指定TaskCreationOptions.AttachedToParent,那麼父任務wait時也會等子任務的結束
- DenyChildAttach:不讓子任務附加到父任務上
- LongRunning:指定是長時間運行任務,如果事先知道這個任務會耗時比較長,建議設置此項。這樣,Task調度器會創建Thread線程,而不使用ThreadPool線程。因為你長時間佔用ThreadPool線程不還,那它可能必要時會在線程池中開啟新的線程,造成調度壓力
- PreferFairness:盡可能公平的安排任務,這意味着較早安排的任務將更可能較早運行,而較晚安排運行的任務將更可能較晚運行。實際通過把任務放到線程池的全局隊列中,讓工作線程去爭搶,默認是在本地隊列中。
另一個枚舉參數是ContinueWith方法中的TaskContinuationOptions枚舉參數,它除了擁有幾個和上面同樣功能的枚舉值外,還擁有控制任務的取消延續等功能
- LazyCancellation:在延續取消的情況下,防止延續的完成直到完成先前的任務。什麼意思呢?
CancellationTokenSource source = new CancellationTokenSource();
source.Cancel();
var task1 = new Task(() =>
{
Console.WriteLine($"task1 id={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
});
var task2 = task1.ContinueWith(t =>
{
Console.WriteLine($"task2 id={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
},source.Token);
var task3 = task2.ContinueWith(t =>
{
Console.WriteLine($"task3 id={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
});
task1.Start();
上面例子我們企圖task1->task2->task3順序執行,然後通過CancellationToken來取消task2的執行。結果會是怎樣呢?結果task1和task3會并行執行(task3也是會執行的,而且是和task1并行,等於原來的一條鏈變成了兩條鏈),然後我們嘗試使用LazyCancellation,
var task2 = task1.ContinueWith(t =>
{
Console.WriteLine($"task2 id={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
},source.Token,TaskContinuationOptions.LazyCancellation,TaskScheduler.Current);
這樣,將會在task1執行完成后,task2才去判斷source.Token,為Cancel就不執行,接下來執行task3就保證了原來的順序
- ExecuteSynchronously:指定應同步執行延續任務,比如上例中,在延續任務task2中指定此參數,則task2會使用執行task1的線程來執行,這樣防止線程切換,可以做些共有資源的訪問。不指定的話就隨機,但也能也用到task1的線程
- NotOnRanToCompletion:延續任務必須在前面任務非完成狀態下執行
- OnlyOnRanToCompletion:延續任務必須在前面任務完成狀態才能執行
- NotOnFaulted,OnlyOnCanceled,OnlyOnFaulted等等
5、任務取消
在上篇使用Thread時,我們使用一個變量isStop標記是否取消任務,這種訪問共享變量的方式難免會出問題。task中提出CancellationTokenSource類專門處理任務取消,常見用法看下面代碼註釋
CancellationTokenSource source = new CancellationTokenSource();//構造函數中也可指定延遲取消
//註冊一個取消時調用的委託
source.Token.Register(() =>
{
Console.WriteLine("當前source已經取消,可以在這裏做一些其他事情(比如資源清理)...");
});
var task1 = new Task(() =>
{
while (!source.IsCancellationRequested)
{
Console.WriteLine($"task1 id={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}");
}
},source.Token);
task1.Start();
//source.Cancel();//取消
source.CancelAfter(1000);//延時取消
6、任務結果
讓子線程返回結果,可以將信息寫入到線程安全的共享變量中去,或則使用可以返回結果的任務。使用Task的泛型版本Task<TResult>,就可以定義返回結果的任務。Task是繼承自Task的,Result獲取結果時是要阻塞等待直到任務完成返回結果的,內部判斷沒有完成則wait。通過TaskStatus屬性可獲得此任務的狀態是啟動、運行、異常還是取消等
var task = new Task<string>(() =>
{
return "hello ketty";
});
task.Start();
string result = task.Result;
7、異常
可以使用AggregateException來接受任務中的異常信息,這是一個聚合異常繼承自Exception,可以遍歷獲取包含的所有異常,以及進行異常處理,決定是否繼續往上拋異常等
var task = Task.Factory.StartNew(() =>
{
var childTask1 = Task.Factory.StartNew(() =>
{
throw new Exception("childTask1異常...");
},TaskCreationOptions.AttachedToParent);
var childTask12= Task.Factory.StartNew(() =>
{
throw new Exception("childTask2異常...");
}, TaskCreationOptions.AttachedToParent);
});
try
{
try
{
task.Wait();
}
catch (AggregateException ex)
{
foreach (var item in ex.InnerExceptions)
{
Console.WriteLine($"message{item.InnerException.Message}");
}
ex.Handle(x =>
{
if (x.InnerException.Message == "childTask1異常...")
{
return true;//異常被處理,不繼續往上拋了
}
return false;
});
}
}
catch (Exception ex)
{
throw;
}
二、并行Parallel
1、Parallel.For()、Parallel.ForEach()
在.NET4中,另一個新增的抽象的線程時Parallel類。這個類定義了并行的for和foreach的靜態方法。Parallel.For()和Parallel.ForEach()方法多次調用一個方法,而Parallel.Invoke()方法允許同時調用不同的方法。首先Parallel是會阻塞主線程的,它將讓主線程也參与到任務中
Parallel.For()類似於for允許語句,并行迭代同一個方法,迭代順序沒有保證的
ParallelLoopResult result = Parallel.For(0, 10, i =>
{
Console.WriteLine($"{i} task:{Task.CurrentId} thread:{Thread.CurrentThread.ManagedThreadId}");
});
Console.WriteLine(result.IsCompleted);
也可以提前中斷Parallel.For()方法。For()方法的一個重載版本接受Action<int,parallelloopstate style=”font-size: inherit; color: inherit; line-height: inherit; margin: 0px; padding: 0px;”>類型參數。一般不使用,像下面這樣,本想大於5就停止,但實際也可能有大於5的任務已經在跑了。可以通過ParallelOptions傳入允許最大線程數以及取消Token等
ParallelLoopResult result = Parallel.For(0, 10, new ParallelOptions() { MaxDegreeOfParallelism = 8 },(i,loop) =>
{
Console.WriteLine($"{i} task:{Task.CurrentId} thread:{Thread.CurrentThread.ManagedThreadId}");
if (i > 5)
{
loop.Break();
}
});
2、Parallel.For<TLocal>
For還有一個高級泛型版本,相當於并行的聚合計算
ParallelLoopResult For<TLocal>(int fromInclusive, int toExclusive, Func<TLocal> localInit, Func<int, ParallelLoopState, TLocal, TLocal> body, Action<TLocal> localFinally);
像下面這樣我們求0…100的和,第三個參數更定一個種子初始值,第四個參數迭代累計,最後聚合
int totalNum = 0;
Parallel.For<int>(0, 100, () => { return 0; }, (current, loop, total) =>
{
total += current;
return total;
}, (total) =>
{
Interlocked.Add(ref totalNum, total);
});
上面For用來處理數組數據,ForEach()方法用來處理非數組的數據任務,比如字典數據繼承自IEnumerable的集合等
3、Parallel.Invoke()
Parallel.Invoke()則可以并行調用不同的方法,參數傳遞一個Action的委託數組
Parallel.Invoke(() => { Console.WriteLine($"方法1 thread:{Thread.CurrentThread.ManagedThreadId}"); }
, () => { Console.WriteLine($"方法2 thread:{Thread.CurrentThread.ManagedThreadId}"); }
, () => { Console.WriteLine($"方法3 thread:{Thread.CurrentThread.ManagedThreadId}"); });
4、PLinq
Plinq,為了能夠達到最大的靈活度,linq有了并行版本。使用也很簡單,只需要將原始集合AsParallel就轉換為支持并行化的查詢。也可以AsOrdered來順序執行,取消Token,強制并行等
var nums = Enumerable.Range(0, 100);
var query = from n in nums.AsParallel()
select new
{
thread=$"tid={Thread.CurrentThread.ManagedThreadId},datetime={DateTime.Now}"
};
三、異步等待AsyncAwait
異步編程模型,可能還需要大篇幅來學習,這裏先介紹下基本用法,內在本質需要用ILSpy反編譯來看,以後可能要分專題總結。文末先給幾個參考資料,有興趣自己闊以先琢磨琢磨鴨
1、簡單使用
這是.NET4.5開始提供的一對語法糖,使得可以較簡便的使用異步編程。async用在方法定義前面,await只能寫在帶有async標記的方法中,任何方法都可以增加async,一般成對出現,只有async沒有意義,只有await會報錯,請先看下面的示例
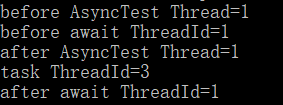
private static async void AsyncTest()
{
//主線程執行
Console.WriteLine($"before await ThreadId={Thread.CurrentThread.ManagedThreadId}");
TaskFactory taskFactory = new TaskFactory();
Task task = taskFactory.StartNew(() =>
{
Thread.Sleep(3000);
Console.WriteLine($"task ThreadId={Thread.CurrentThread.ManagedThreadId}");
});
await task;//主線程到這裏就返回了,執行主線程任務
//子線程執行,其實是封裝成委託,在task之後成為回調(編譯器功能 狀態機實現) 後面相當於task.ContinueWith()
//這個回調的線程是不確定的:可能是主線程 可能是子線程 也可能是其他線程,在winform中是主線程
Console.WriteLine($"after await ThreadId={Thread.CurrentThread.ManagedThreadId}");
}
一般使用async都會讓方法返回一個Task的,像下面這樣複雜一點的
private static async Task<string> AsyncTest2()
{
Console.WriteLine($"before await ThreadId={Thread.CurrentThread.ManagedThreadId}");
TaskFactory taskFactory = new TaskFactory();
string x = await taskFactory.StartNew(() =>
{
Thread.Sleep(3000);
Console.WriteLine($"task ThreadId={Thread.CurrentThread.ManagedThreadId}");
return "task over";
});
Console.WriteLine($"after await ThreadId={Thread.CurrentThread.ManagedThreadId}");
return x;
}
通過var reslult = AsyncTest2().Result;調用即可。但注意如果調用Wait或Result的代碼位於UI線程,Task的實際執行在其他線程,其需要返回UI線程則會造成死鎖,所以應該Async all the way
2、優雅
從上面簡單示例中可以看出異步編程的執行邏輯:主線程A邏輯->異步任務線程B邏輯->主線程C邏輯。
異步方法的返回類型只能是void、Task、Task。示例中異步方法的返回值類型是Task,通常void也不推薦使用,沒有返回值直接用Task就是
上一篇也大概了解到如果我們要在任務中更新UI,需要調用Invoke通知UI線程來更新,代碼看起來像下面這樣,在一個任務後去更新UI
private void button1_Click(object sender, EventArgs e)
{
var ResultTask = Task.Run(() => {
Thread.Sleep(5000);
return "任務完成";
});
ResultTask.ContinueWith((r)=>
{
textBox1.Invoke(() => {
textBox1.Text = r.Result;
});
});
}
如果使用async/await會看起來像這樣,是不是優雅了許多。以看似同步編程的方式實現異步
private async void button1_Click(object sender, EventArgs e)
{
var t = Task.Run(() => {
Thread.Sleep(5000);
return "任務完成";
});
textBox1.Text = await t;
}
3、最後
在.NET 4.5中引入的Async和Await兩個新的關鍵字后,用戶能以一種簡潔直觀的方式實現異步編程。甚至都不需要改變代碼的邏輯結構,就能將原來的同步函數改造為異步函數。
在內部實現上,Async和Await這兩個關鍵字由編譯器轉換為狀態機,通過System.Threading.Tasks中的并行類實現代碼的異步執行。
字數有點多了,我的能力也就高考作文800字能寫的出奇好。看了很多異步編程,腦袋有點炸,等消化后再輸出一次,技藝不足,只能用輸出倒逼輸入了,下一篇會是線程安全集合、鎖問題、同步問題,基於事件的異步模式等
Search the fucking web
Read the fucking maunal
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整