前言
最近在寫項目的時候發現自己的SQL基本功有些薄弱,遂上知乎查詢MYSQL關鍵字,期望得到某些高贊答案的指點,於是乎發現了
https://www.zhihu.com/question/34840297/answer/272185020 這位老兄的建議的書單,根據他的建議首先拜讀了《MYSQL必知必會》這本書,整體講的很基礎,頁數也不多一共 253 頁,適合基礎比較薄弱的同學進行食用。然後循序漸進,閱讀更深層次的書籍進行自我提升。這裏記載了自己在閱讀的過程中記錄的一些關鍵內容,分享給大家。書本 PDF 可以在上面的知乎鏈接獲取,或者點擊 http://www.notedeep.com/note/38/page/282 前往老哥的深度筆記進行下載。
閱讀心得
SQL語句和大小寫
SQL語句不區分大小寫,並且在 Windows 環境下,4.1.1版本之後(現在常用的都是 5.6/5.7/8.0+),MYSQL表名,字段名也是不區分大小寫的,因此我們在命名的時候建議使用單個單詞_單個單詞的形式命名,如:mysql_crash_course user_role
這裏附上阿里代碼規範的一條強制要求:
【強制】表名、字段名必須使用小寫字母或数字,禁止出現数字開頭,禁止兩個下劃線中間只出現数字。數據庫字段名的修改代價很大,因為無法進行預發布,所以字段名稱需要慎重考慮。
說明: MySQL 在 Windows 下不區分大小寫,但在 Linux 下默認是區分大小寫。因此,數據庫名、表名、字段名,都不允許出現任何大寫字母,避免節外生枝。
不能部分使用DISTINCT
- DISTINCT 關鍵字應用於所有列而不僅是前置它的列。如果給出 SELECT DISTINCT vend_id,prod_price ,除非指定的兩個列都不同,否則所有行都將被檢索出來。
- DISTINCT 不會返回其後面跟的所有字段都相同的列。即兩行中SELECT查詢的任何一個字段都相同才會被去重。不能通過DISTINCT加括號 () 等方式來對單個字段進行去重。
比如項目中有這麼一個需求:
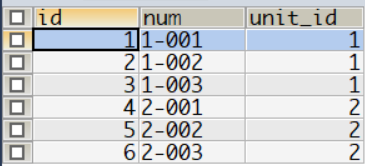
需要分頁查詢綁了某收費標準的房屋,因為是房屋列表查詢,我們默認相同ID的房屋只出現一次,錯誤的SQL如下:
房屋表
收費標準表
SELECT DISTINCT h.id, h.num, s.name
FROM house h
LEFT JOIN standard s
ON h.id = s.room_id
WHERE s.name = '物業費' OR s.name = '暖氣費';這條語句並不能返回想要的結果,即每套房屋只出現一次,因為不同的收費標準名稱不一樣,DISTINCT 不能對部分查詢條件去重。可以看到房號為1-001的記錄出現了兩次。
不過其實按照需求的描述我這裏僅查詢房屋的信息,對於查詢結果來說同一條記錄的房屋信息肯定完全相同,因此 DISTINCT 在我的業務中滿足要求。而有其他業務需要此關鍵字的時候,請大家慎重使用,切記不能部分使用該關鍵字
區分大小寫和排序順序
在對文本性的數據進行排序時,A與a相同嗎?a位於B之前還是位於Z之後?
在創建字段時可以指定字符集,一般使用 utf8mb4, 此時可以選擇相應的排序規則。
- utf8mb4_general_ci ci即大小寫不敏感,排序時忽略大小寫,A a 視作相同
- utf8mb4_bin / 帶 cs 的即大小寫敏感,相應的升序排列的話, A~Z 在前,小a~z在後
相應的,在設置大小寫敏感后,查詢條件 where cs = ‘a’ 只能查找到表中該字段為小寫 a 的行。而不敏感,即ci時,A,a都可以被查詢出來。
BETWEEN關鍵字的注意事項
在區間查詢時,我們最關注的不應該是區間內的能否被匹配到,因為這是肯定的。而區間的邊界能否被匹配才是我們應該注意的知識點,BETWEEN AND 關鍵字匹配區間時,包含左右邊界條件。如下面的 SQL 執行結果如下:
SELECT prod_name, prod_price
FROM products p
WHERE p.`prod_price` BETWEEN 5.99 AND 10NULL 與不匹配
在通過過濾選擇出不具有特定值的行時,你可能希望返回具有 NULL 值的行。但是,不行。常見的錯誤會發生在is_xxx 字段上,我經常有這個毛病,
對於 is_delete 字段,我認為為 null 或者 0 都是未刪除的房屋,所以當我使用
SELECT * FROM house WHERE is_delete = '0';查詢未刪除的房屋時,我只能查到 id 為 3 的房屋,這顯然與我的預期是不符的,解決辦法是where後面加 or is_delete is null ,或者給 is_delete 列默認值 0;建議使用後者。
這裏附上阿里代碼手冊的一條強制項目:
【強制】表達是與否概念的字段,必須使用 is_xxx 的方式命名,數據類型是 unsigned tinyint(1 表示是,0 表示否)。說明:任何字段如果為非負數,必須是 unsigned 。
解釋:tinyint 相當於 Java 中的 byte,取值範圍 -128 ~ 127 ,用來表達是否長度已經足夠,也可以用來表示人的年齡。而 unsigned 表示無符號的,對於確定為非負數的字段,使用 unsigned 可以將取值範圍擴大一倍。
AND 和 OR 的計算次序
舉個例子:假如需要列出價格為10美元(含)以上且由 1002 或 1003 製造的所有產品。下面的 SELECT 語句使用 AND 和 OR 操作符的組合建立了一個WHERE 子句:
SELECT *
FROM products
WHERE vend_id = 1002 OR vend_id = 1003 AND prod_price >= 10;查詢結果如下:
而被我用紅框標註的行很顯然不是我們需要的行,為什麼會這樣呢?原因在於計算的次序。SQL(像多數語言一樣)在處理 OR 操作符前,優先處理 AND 操作符。當SQL看到上述 WHERE 子句時,它理解為由供應商 1003 製造的任何價格為10美元(含)以上的產品,或者由供應商 1002 製造的任何產品,而不管其價格如何。換句話說,由於 AND 在計算次序中優先級更高,操作符被錯誤地組合了。解決方法就是加 ();正確的 SQL 如下:
SELECT *
FROM products
WHERE (vend_id = 1002 OR vend_id = 1003) AND prod_price >= 10;建議在任何時候使用具有 AND 和 OR 操作符的 WHERE 子句,都應該使用圓括號明確地分組操作符。不要過分依賴默認計算次序,即使它確實是你想要的東西也是如此。使用圓括號沒有什麼壞處,它能消除歧義。
UNION 組合查詢
- 利用 UNION ,可給出多條SELECT 語句,將它們的結果組合成單個結果集。
- UNION 中的每個查詢必須包含相同的列、表達式或聚集函數。
- 在使用UNION 時,重複的行被自動取消。這是 UNION 的默認行為,但是如果需要,可以改變它。事實上,如果想返回所有匹配行,可使用 UNION ALL 而不是 UNION 。
- 在用 UNION 組合查詢時,只能使用一條 ORDER BY 子句,它必須出現在最後一條 SELECT 語句之後
INSERT語句總是使用列的列表
一般不要使用沒有明確給出列的列表的 INSERT 語句。使用列的列表能使SQL代碼繼續發揮作用,即使表結構發生了變化。實際開發中有可能由於業務的需要,對錶結構進行修改,添加/刪除某一列。這時如果代碼中使用的SQL語句是沒有明確列表的插入語句就會報錯。當然一般我們使用逆向工程生成的 insertSelective(POJO) 並不存在這個問題,因為它對應生成的 SQL 會為我們生成列的列表。
小心使用更新和刪除語句
MySQL 沒有撤銷按鈕,因此在使用 UPDATE / DELETE 時一定要加上 WHERE 條件,並且在執行更新/刪除操作之前先進行 SELECT 操作,開啟事務。在執行結束后核對影響的行數和 SELECT 查詢出來的行數一致后再 COMMIT;
另外,使用 ALTER TABLE 要極為小心,應該在進行改動前做一個完整的備份(模式和數據的備份)。數據庫表的更改不能撤銷,如果增加了不需要的列,可能不能刪除它們。類似地,如果刪除了不應該刪除的列,可能會丟失該列中的所有數據。
視圖的規則和限制
- 與表一樣,視圖必須唯一命名(不能給視圖取與別的視圖或表相同的名字)。
- 對於可以創建的視圖數目沒有限制。
- 為了創建視圖,必須具有足夠的訪問權限。這些限制通常由數據庫管理人員授予。
- 視圖可以嵌套,即可以利用從其他視圖中檢索數據的查詢來構造一個視圖。
- ORDER BY 可以用在視圖中,但如果從該視圖檢索數據 SELECT 中也含有 ORDER BY ,那麼該視圖中的 ORDER BY 將被覆蓋。
- 視圖不能索引,也不能有關聯的觸發器或默認值。
- 視圖可以和表一起使用。例如,編寫一條聯結表和視圖的 SELECT語句。
其中視圖不能索引這一點要格外注意,在我開發過程中遇到過這樣一個視圖:使用 UNION 連結了好幾張表進行查詢,對查詢的結果使用 WHERE 條件再過濾,這裏雖然對於被連接的表對於 WHERE 條件后的字段都建立了索引,但是使用 UNION 連結生成視圖的臨時表並不能擁有索引。因此查詢的效率會很慢!所以建議在 UNION 查詢中將 WHERE 條件放在每個 SELECT 語句中。
改善性能的一些建議
-
首先,MySQL(與所有DBMS一樣)具有特定的硬件建議。在學習和研究MySQL時,使用任何舊的計算機作為服務器都可以。但
對用於生產的服務器來說,應該堅持遵循這些硬件建議。 -
一般來說,關鍵的生產DBMS應該運行在自己的專用服務器上。
-
MySQL是用一系列的默認設置預先配置的,從這些設置開始通常是很好的。但過一段時間后你可能需要調整內存分配、緩衝區大小等。(為查看當前設置,可使用 SHOW VARIABLES; 和 SHOWSTATUS; )
-
MySQL一個多用戶多線程的DBMS,換言之,它經常同時執行多個任務。如果這些任務中的某一個執行緩慢,則所有請求都會執
行緩慢。如果你遇到顯著的性能不良,可使用 SHOW PROCESSLIST显示所有活動進程(以及它們的線程ID和執行時間)。你還可以用KILL 命令終結某個特定的進程(使用這個命令需要作為管理員登錄)。 -
總是有不止一種方法編寫同一條 SELECT 語句。應該試驗聯結、並、子查詢等,找出最佳的方法。
-
使用 EXPLAIN 語句讓MySQL解釋它將如何執行一條 SELECT 語句。
-
一般來說,存儲過程執行得比一條一條地執行其中的各條MySQL語句快。但存儲過程一般難以調試和擴展,並且沒有移植性,因此阿里代碼規約裏面強制禁止使用存儲過程
-
應該總是使用正確的數據類型。
-
決不要檢索比需求還要多的數據。換言之,不要用 SELECT * (除非你真正需要每個列)。
-
有的操作(包括 INSERT )支持一個可選的 DELAYED 關鍵字,如果使用它,將把控制立即返回給調用程序,並且一旦有可能就實際執行該操作。
延遲插入,當插入和查詢併發執行時,插入被放入等待隊列中。直至所有查詢執行完畢后執行插入。並且MYSQL會在收到插入請求后直接返回給客戶端狀態信息,既是INSERT語句還在隊列中
-
在導入數據時,應該關閉自動提交。你可能還想刪除索引(包括FULLTEXT 索引),然後在導入完成后再重建它們。
-
必須索引數據庫表以改善數據檢索的性能。確定索引什麼不是一件微不足道的任務,需要分析使用的 SELECT 語句以找出重複的WHERE 和 ORDER BY 子句。如果一個簡單的 WHERE 子句返回結果所花的時間太長,則可以斷定其中使用的列(或幾個列)就是需要索引的對象。
-
你的 SELECT 語句中有一系列複雜的 OR 條件嗎?通過使用多條SELECT 語句和連接它們的 UNION 語句,你能看到極大的性能改進。
-
索引改善數據檢索的性能,但損害數據插入、刪除和更新的性能。如果你有一些表,它們收集數據且不經常被搜索,則在有必要之前不要索引它們。(索引可根據需要添加和刪除。)
-
LIKE 很慢。一般來說,最好是使用 FULLTEXT 而不是 LIKE 。但是 MYSQL FULLTEXT 對漢字並不友好,如果需要使用全文索引,建議使用搜索引擎 ES,可以參考我的另一篇博客: https://www.cnblogs.com/keatsCoder/p/11341835.html
-
數據庫是不斷變化的實體。一組優化良好的表一會兒后可能就面目全非了。由於表的使用和內容的更改,理想的優化和配置也會改變。
-
最重要的規則就是,每條規則在某些條件下都會被打破。
實際開發過程中,我們需要根據業務的需要,開啟慢查詢日誌,然後針對慢SQL,不斷地進行 EXPLAIN 與修改SQL和索引,以求達到 ref 級別,至少達到 range 級別。這就需要強大的內功支持而不是每次都通過百度來解決,希望閱讀此篇文章的你和我一起不斷修鍊。加油!
常用的函數
文本處理函數
日期和時間處理函數
數值處理函數
聚合函數
- 雖然 MAX() 一般用來找出最大的數值或日期值,但MySQL允許將它用來返回任意列中的最大值,包括返迴文本列中的最大值。在用於文本數據時,如果數據按相應的列排序,則 MAX() 返回最後一行。MIN() 函數類似
- MAX() 函數忽略列值為 NULL 的行。MIN() 函數類似,SUM() 也是
附錄
由於數中所附的附件內容(建表語句即數據插入語句)需要外網才能訪問,為了方便大家使用。這裏我已經下載下來附在了這篇博客裏面。如果不需要這些語句,可以直接通過網頁右邊的目錄跳躍到下一章進行瀏覽
建表語句
########################################
# MySQL Crash Course MYSQL必知必會建表語句
# http://www.forta.com/books/0672327120/
# 提供者博客園:后青春期的Keats 複製請註明出處
########################################
########################
# Create customers table
########################
CREATE TABLE customers
(
cust_id int NOT NULL AUTO_INCREMENT,
cust_name char(50) NOT NULL ,
cust_address char(50) NULL ,
cust_city char(50) NULL ,
cust_state char(5) NULL ,
cust_zip char(10) NULL ,
cust_country char(50) NULL ,
cust_contact char(50) NULL ,
cust_email char(255) NULL ,
PRIMARY KEY (cust_id)
) ENGINE=InnoDB;
#########################
# Create orderitems table
#########################
CREATE TABLE orderitems
(
order_num int NOT NULL ,
order_item int NOT NULL ,
prod_id char(10) NOT NULL ,
quantity int NOT NULL ,
item_price decimal(8,2) NOT NULL ,
PRIMARY KEY (order_num, order_item)
) ENGINE=InnoDB;
#####################
# Create orders table
#####################
CREATE TABLE orders
(
order_num int NOT NULL AUTO_INCREMENT,
order_date datetime NOT NULL ,
cust_id int NOT NULL ,
PRIMARY KEY (order_num)
) ENGINE=InnoDB;
#######################
# Create products table
#######################
CREATE TABLE products
(
prod_id char(10) NOT NULL,
vend_id int NOT NULL ,
prod_name char(255) NOT NULL ,
prod_price decimal(8,2) NOT NULL ,
prod_desc text NULL ,
PRIMARY KEY(prod_id)
) ENGINE=InnoDB;
######################
# Create vendors table
######################
CREATE TABLE vendors
(
vend_id int NOT NULL AUTO_INCREMENT,
vend_name char(50) NOT NULL ,
vend_address char(50) NULL ,
vend_city char(50) NULL ,
vend_state char(5) NULL ,
vend_zip char(10) NULL ,
vend_country char(50) NULL ,
PRIMARY KEY (vend_id)
) ENGINE=InnoDB;
###########################
# Create productnotes table
###########################
CREATE TABLE productnotes
(
note_id int NOT NULL AUTO_INCREMENT,
prod_id char(10) NOT NULL,
note_date datetime NOT NULL,
note_text text NULL ,
PRIMARY KEY(note_id),
FULLTEXT(note_text)
) ENGINE=MyISAM;
#####################
# Define foreign keys
#####################
ALTER TABLE orderitems ADD CONSTRAINT fk_orderitems_orders FOREIGN KEY (order_num) REFERENCES orders (order_num);
ALTER TABLE orderitems ADD CONSTRAINT fk_orderitems_products FOREIGN KEY (prod_id) REFERENCES products (prod_id);
ALTER TABLE orders ADD CONSTRAINT fk_orders_customers FOREIGN KEY (cust_id) REFERENCES customers (cust_id);
ALTER TABLE products ADD CONSTRAINT fk_products_vendors FOREIGN KEY (vend_id) REFERENCES vendors (vend_id);數據語句
########################################
# MySQL Crash Course MYSQL必知必會數據語句
# http://www.forta.com/books/0672327120/
# 提供者博客園:后青春期的Keats 複製請註明出處
########################################
##########################
# Populate customers table
##########################
INSERT INTO customers(cust_id, cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact, cust_email)
VALUES(10001, 'Coyote Inc.', '200 Maple Lane', 'Detroit', 'MI', '44444', 'USA', 'Y Lee', 'ylee@coyote.com');
INSERT INTO customers(cust_id, cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact)
VALUES(10002, 'Mouse House', '333 Fromage Lane', 'Columbus', 'OH', '43333', 'USA', 'Jerry Mouse');
INSERT INTO customers(cust_id, cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact, cust_email)
VALUES(10003, 'Wascals', '1 Sunny Place', 'Muncie', 'IN', '42222', 'USA', 'Jim Jones', 'rabbit@wascally.com');
INSERT INTO customers(cust_id, cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact, cust_email)
VALUES(10004, 'Yosemite Place', '829 Riverside Drive', 'Phoenix', 'AZ', '88888', 'USA', 'Y Sam', 'sam@yosemite.com');
INSERT INTO customers(cust_id, cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact)
VALUES(10005, 'E Fudd', '4545 53rd Street', 'Chicago', 'IL', '54545', 'USA', 'E Fudd');
########################
# Populate vendors table
########################
INSERT INTO vendors(vend_id, vend_name, vend_address, vend_city, vend_state, vend_zip, vend_country)
VALUES(1001,'Anvils R Us','123 Main Street','Southfield','MI','48075', 'USA');
INSERT INTO vendors(vend_id, vend_name, vend_address, vend_city, vend_state, vend_zip, vend_country)
VALUES(1002,'LT Supplies','500 Park Street','Anytown','OH','44333', 'USA');
INSERT INTO vendors(vend_id, vend_name, vend_address, vend_city, vend_state, vend_zip, vend_country)
VALUES(1003,'ACME','555 High Street','Los Angeles','CA','90046', 'USA');
INSERT INTO vendors(vend_id, vend_name, vend_address, vend_city, vend_state, vend_zip, vend_country)
VALUES(1004,'Furball Inc.','1000 5th Avenue','New York','NY','11111', 'USA');
INSERT INTO vendors(vend_id, vend_name, vend_address, vend_city, vend_state, vend_zip, vend_country)
VALUES(1005,'Jet Set','42 Galaxy Road','London', NULL,'N16 6PS', 'England');
INSERT INTO vendors(vend_id, vend_name, vend_address, vend_city, vend_state, vend_zip, vend_country)
VALUES(1006,'Jouets Et Ours','1 Rue Amusement','Paris', NULL,'45678', 'France');
#########################
# Populate products table
#########################
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('ANV01', 1001, '.5 ton anvil', 5.99, '.5 ton anvil, black, complete with handy hook');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('ANV02', 1001, '1 ton anvil', 9.99, '1 ton anvil, black, complete with handy hook and carrying case');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('ANV03', 1001, '2 ton anvil', 14.99, '2 ton anvil, black, complete with handy hook and carrying case');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('OL1', 1002, 'Oil can', 8.99, 'Oil can, red');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('FU1', 1002, 'Fuses', 3.42, '1 dozen, extra long');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('SLING', 1003, 'Sling', 4.49, 'Sling, one size fits all');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('TNT1', 1003, 'TNT (1 stick)', 2.50, 'TNT, red, single stick');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('TNT2', 1003, 'TNT (5 sticks)', 10, 'TNT, red, pack of 10 sticks');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('FB', 1003, 'Bird seed', 10, 'Large bag (suitable for road runners)');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('FC', 1003, 'Carrots', 2.50, 'Carrots (rabbit hunting season only)');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('SAFE', 1003, 'Safe', 50, 'Safe with combination lock');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('DTNTR', 1003, 'Detonator', 13, 'Detonator (plunger powered), fuses not included');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('JP1000', 1005, 'JetPack 1000', 35, 'JetPack 1000, intended for single use');
INSERT INTO products(prod_id, vend_id, prod_name, prod_price, prod_desc)
VALUES('JP2000', 1005, 'JetPack 2000', 55, 'JetPack 2000, multi-use');
#######################
# Populate orders table
#######################
INSERT INTO orders(order_num, order_date, cust_id)
VALUES(20005, '2005-09-01', 10001);
INSERT INTO orders(order_num, order_date, cust_id)
VALUES(20006, '2005-09-12', 10003);
INSERT INTO orders(order_num, order_date, cust_id)
VALUES(20007, '2005-09-30', 10004);
INSERT INTO orders(order_num, order_date, cust_id)
VALUES(20008, '2005-10-03', 10005);
INSERT INTO orders(order_num, order_date, cust_id)
VALUES(20009, '2005-10-08', 10001);
###########################
# Populate orderitems table
###########################
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20005, 1, 'ANV01', 10, 5.99);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20005, 2, 'ANV02', 3, 9.99);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20005, 3, 'TNT2', 5, 10);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20005, 4, 'FB', 1, 10);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20006, 1, 'JP2000', 1, 55);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20007, 1, 'TNT2', 100, 10);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20008, 1, 'FC', 50, 2.50);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20009, 1, 'FB', 1, 10);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20009, 2, 'OL1', 1, 8.99);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20009, 3, 'SLING', 1, 4.49);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20009, 4, 'ANV03', 1, 14.99);
#############################
# Populate productnotes table
#############################
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(101, 'TNT2', '2005-08-17',
'Customer complaint:
Sticks not individually wrapped, too easy to mistakenly detonate all at once.
Recommend individual wrapping.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(102, 'OL1', '2005-08-18',
'Can shipped full, refills not available.
Need to order new can if refill needed.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(103, 'SAFE', '2005-08-18',
'Safe is combination locked, combination not provided with safe.
This is rarely a problem as safes are typically blown up or dropped by customers.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(104, 'FC', '2005-08-19',
'Quantity varies, sold by the sack load.
All guaranteed to be bright and orange, and suitable for use as rabbit bait.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(105, 'TNT2', '2005-08-20',
'Included fuses are short and have been known to detonate too quickly for some customers.
Longer fuses are available (item FU1) and should be recommended.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(106, 'TNT2', '2005-08-22',
'Matches not included, recommend purchase of matches or detonator (item DTNTR).'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(107, 'SAFE', '2005-08-23',
'Please note that no returns will be accepted if safe opened using explosives.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(108, 'ANV01', '2005-08-25',
'Multiple customer returns, anvils failing to drop fast enough or falling backwards on purchaser. Recommend that customer considers using heavier anvils.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(109, 'ANV03', '2005-09-01',
'Item is extremely heavy. Designed for dropping, not recommended for use with slings, ropes, pulleys, or tightropes.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(110, 'FC', '2005-09-01',
'Customer complaint: rabbit has been able to detect trap, food apparently less effective now.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(111, 'SLING', '2005-09-02',
'Shipped unassembled, requires common tools (including oversized hammer).'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(112, 'SAFE', '2005-09-02',
'Customer complaint:
Circular hole in safe floor can apparently be easily cut with handsaw.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(113, 'ANV01', '2005-09-05',
'Customer complaint:
Not heavy enough to generate flying stars around head of victim. If being purchased for dropping, recommend ANV02 or ANV03 instead.'
);
INSERT INTO productnotes(note_id, prod_id, note_date, note_text)
VALUES(114, 'SAFE', '2005-09-07',
'Call from individual trapped in safe plummeting to the ground, suggests an escape hatch be added.
Comment forwarded to vendor.'
);本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益